Related Research Articles

Metabolomics is the scientific study of chemical processes involving metabolites, the small molecule substrates, intermediates, and products of cell metabolism. Specifically, metabolomics is the "systematic study of the unique chemical fingerprints that specific cellular processes leave behind", the study of their small-molecule metabolite profiles. The metabolome represents the complete set of metabolites in a biological cell, tissue, organ, or organism, which are the end products of cellular processes. Messenger RNA (mRNA), gene expression data, and proteomic analyses reveal the set of gene products being produced in the cell, data that represents one aspect of cellular function. Conversely, metabolic profiling can give an instantaneous snapshot of the physiology of that cell, and thus, metabolomics provides a direct "functional readout of the physiological state" of an organism. There are indeed quantifiable correlations between the metabolome and the other cellular ensembles, which can be used to predict metabolite abundances in biological samples from, for example mRNA abundances. One of the ultimate challenges of systems biology is to integrate metabolomics with all other -omics information to provide a better understanding of cellular biology.

An aroma compound, also known as an odorant, aroma, fragrance or flavoring, is a chemical compound that has a smell or odor. For an individual chemical or class of chemical compounds to impart a smell or fragrance, it must be sufficiently volatile for transmission via the air to the olfactory system in the upper part of the nose. As examples, various fragrant fruits have diverse aroma compounds, particularly strawberries which are commercially cultivated to have appealing aromas, and contain several hundred aroma compounds.

The metabolome refers to the complete set of small-molecule chemicals found within a biological sample. The biological sample can be a cell, a cellular organelle, an organ, a tissue, a tissue extract, a biofluid or an entire organism. The small molecule chemicals found in a given metabolome may include both endogenous metabolites that are naturally produced by an organism as well as exogenous chemicals that are not naturally produced by an organism.

Ethyl acetate is the organic compound with the formula CH3CO2CH2CH3, simplified to C4H8O2. This colorless liquid has a characteristic sweet smell and is used in glues, nail polish removers, and the decaffeination process of tea and coffee. Ethyl acetate is the ester of ethanol and acetic acid; it is manufactured on a large scale for use as a solvent.

Eugenol is an allyl chain-substituted guaiacol, a member of the allylbenzene class of chemical compounds. It is a colorless to pale yellow, aromatic oily liquid extracted from certain essential oils especially from clove, nutmeg, cinnamon, basil and bay leaf. It is present in concentrations of 80–90% in clove bud oil and at 82–88% in clove leaf oil. Eugenol has a pleasant, spicy, clove-like scent. The name is derived from Eugenia caryophyllata, the former Linnean nomenclature term for cloves. The currently accepted name is Syzygium aromaticum.

Linalool refers to two enantiomers of a naturally occurring terpene alcohol found in many flowers and spice plants. Linalool has multiple commercial applications, the majority of which are based on its pleasant scent. A colorless oil, linalool is classified as an acyclic monoterpenoid. In plants, it is a metabolite, a volatile oil component, an antimicrobial agent, and an aroma compound. Linalool has uses in manufacturing of soaps, fragrances, food additives as flavors, household products, and insecticides. Esters of linalool are referred to as linalyl, e.g. linalyl pyrophosphate, an isomer of geranyl pyrophosphate.

Eucalyptol is a monoterpenoid colorless liquid, and a bicyclic ether. It has a fresh camphor-like odor and a spicy, cooling taste. It is insoluble in water, but miscible with organic solvents. Eucalyptol makes up about 70–90% of eucalyptus oil. Eucalyptol forms crystalline adducts with hydrohalic acids, o-cresol, resorcinol, and phosphoric acid. Formation of these adducts is useful for purification.

Myrcene, or β-myrcene, is a monoterpene. A colorless oil, it occurs widely in essential oils. It is produced mainly semi-synthetically from Myrcia, from which it gets its name. It is an intermediate in the production of several fragrances. α-Myrcene is the name for the isomer 2-methyl-6-methylene-1,7-octadiene, which has not been found in nature.
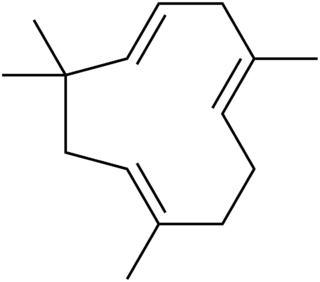
Humulene, also known as α-humulene or α-caryophyllene, is a naturally occurring monocyclic sesquiterpene (C15H24), containing an 11-membered ring and consisting of 3 isoprene units containing three nonconjugated C=C double bonds, two of them being triply substituted and one being doubly substituted. It was first found in the essential oils of Humulus lupulus (hops), from which it derives its name. Humulene is an isomer of β-caryophyllene, and the two are often found together as a mixture in many aromatic plants.
The DrugBank database is a comprehensive, freely accessible, online database containing information on drugs and drug targets created and maintained by the University of Alberta and The Metabolomics Innovation Centre located in Alberta, Canada. As both a bioinformatics and a cheminformatics resource, DrugBank combines detailed drug data with comprehensive drug target information. DrugBank has used content from Wikipedia; Wikipedia also often links to Drugbank, posing potential circular reporting issues.
ChemSpider is a freely accessible online database of chemicals owned by the Royal Society of Chemistry. It contains information on more than 100 million molecules from over 270 data sources, each of them receiving a unique identifier called ChemSpider Identifier.

Ergothioneine is a naturally occurring amino acid and is a thiourea derivative of histidine, containing a sulfur atom on the imidazole ring. This compound occurs in relatively few organisms, notably actinomycetota, cyanobacteria, and certain fungi. Ergothioneine was discovered by Charles Tanret in 1909 and named after the ergot fungus from which it was first purified, with its structure being determined in 1911.
The ChemDB HIV, Opportunistic Infection and Tuberculosis Therapeutics Database is a publicly available tool developed by the National Institute of Allergy and Infectious Diseases to compile preclinical data on small molecules with potential therapeutic action against HIV/AIDS and related opportunistic infections.
The Human Metabolome Database (HMDB) is a comprehensive, high-quality, freely accessible, online database of small molecule metabolites found in the human body. It has been created by the Human Metabolome Project funded by Genome Canada and is one of the first dedicated metabolomics databases. The HMDB facilitates human metabolomics research, including the identification and characterization of human metabolites using NMR spectroscopy, GC-MS spectrometry and LC/MS spectrometry. To aid in this discovery process, the HMDB contains three kinds of data: 1) chemical data, 2) clinical data, and 3) molecular biology/biochemistry data (Fig. 1–3). The chemical data includes 41,514 metabolite structures with detailed descriptions along with nearly 10,000 NMR, GC-MS and LC/MS spectra.
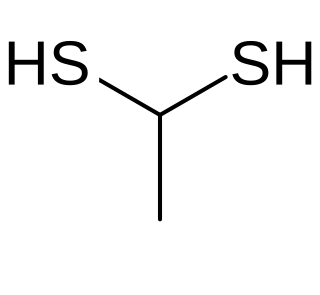
Ethane-1,1-dithiol is an organosulfur compound with formula CH3CH(SH)2. It is a colourless smelly liquid that is added to or found in some foods. The compound is an example of a geminal dithiol.
The Yeast Metabolome Database (YMDB) is a comprehensive, high-quality, freely accessible, online database of small molecule metabolites found in or produced by Saccharomyces cerevisiae. The YMDB was designed to facilitate yeast metabolomics research, specifically in the areas of general fermentation as well as wine, beer and fermented food analysis. YMDB supports the identification and characterization of yeast metabolites using NMR spectroscopy, GC-MS spectrometry and Liquid chromatography–mass spectrometry. The YMDB contains two kinds of data: 1) chemical data and 2) molecular biology/biochemistry data. The chemical data includes 2027 metabolite structures with detailed metabolite descriptions along with nearly 4000 NMR, GC-MS and LC/MS spectra.
The Serum Metabolome database is a free web database about small molecule metabolites found in human serum and their concentration values. The database includes chemical data, clinical data and molecular/biochemistry data from literature and experiment. This database also references many other databases, such as KEGG, PubChem, MetaCyc, ChEBI, PDB, Swiss-Prot, GenBank, and Human Metabolome Database (HMDB).
2-Methylbutanoic acid, also known as 2-methylbutyric acid is a branched-chain alkyl carboxylic acid with the chemical formula CH3CH2CH(CH3)CO2H, classified as a short-chain fatty acid. It exists in two enantiomeric forms, (R)- and (S)-2-methylbutanoic acid. (R)-2-methylbutanoic acid occurs naturally in cocoa beans and (S)-2-methylbutanoic occurs in many fruits such as apples and apricots, as well as in the scent of the orchid Luisia curtisii.
David S. Wishart is a Canadian researcher in metabolomics and a Distinguished University Professor in the Department of Biological Sciences and the Department of Computing Science at the University of Alberta. Wishart also holds cross appointments in the Faculty of Pharmacy and Pharmaceutical Sciences and the Department of Laboratory Medicine and Pathology in the Faculty of Medicine and Dentistry. Additionally, Wishart holds a joint appointment in metabolomics at the Pacific Northwest National Laboratory in Richland, Washington. Wishart is well known for his pioneering contributions to the fields of protein NMR spectroscopy, bioinformatics, cheminformatics and metabolomics. In 2011, Wishart founded the Metabolomics Innovation Centre (TMIC), which is Canada's national metabolomics laboratory.
2-Decanone is a ketone with the chemical formula C10H20O.
References
- 1 2 Scalbert, A.; Andres-Lacueva, C.; Arita, M.; Kroon, P.; Manach, C.; Urpi-Sarda, M.; Wishart, D.S. (2011). "Databases on Food Phytochemicals and Their Health-Promoting Effects". J. Agric. Food Chem. 59 (9): 4331–4348. doi:10.1021/jf200591d. PMID 21438636.
- 1 2 Wishart, D. S.; Knox, C.; Guo, A.; Eisner, A.; Young, N.; Gautam, B.; Hau, D. D.; Psychogios, N.; Dong, E.; Bouatra, S.; Mandal, R.; Sinelnikov, I.; Xia, J.; Jia, L.; Cruz, J. A.; Lim, E.; Sobsey, C. A.; Shrivastava, S.; Huang, P.; Liu, P.; Fang, L.; Peng, J.; Fradette, R.; Cheng, D.; Tzur, D.; Clements, M.; Lewis, A.; Souza, A. D.; Zuniga, A.; Dawe, M.; Xiong, Y.; Clive, D.; Greiner, R.; Nazyrova, A.; Shaykhutdinov, R.; Li, L.; Vogel, H. J.; Forsythe, I. (2009). "HMDB: a knowledgebase for the human metabolome". Nucleic Acids Research. 37 (Database issue): D603–D610. doi:10.1093/nar/gkn810. PMC 2686599 . PMID 18953024.