for arbitrary real constants a, b and non-zero c. It is named after the mathematician Carl Friedrich Gauss. The graph of a Gaussian is a characteristic symmetric "bell curve" shape. The parameter a is the height of the curve's peak, b is the position of the center of the peak, and c (the standard deviation, sometimes called the Gaussian RMS width) controls the width of the "bell".
The product of two Gaussian functions is a Gaussian, and the convolution of two Gaussian functions is also a Gaussian, with variance being the sum of the original variances: . The product of two Gaussian probability density functions (PDFs), though, is not in general a Gaussian PDF.
Taking the Fourier transform (unitary, angular-frequency convention) of a Gaussian function with parameters a = 1, b = 0 and c yields another Gaussian function, with parameters , b = 0 and .[2] So in particular the Gaussian functions with b = 0 and are kept fixed by the Fourier transform (they are eigenfunctions of the Fourier transform with eigenvalue1). A physical realization is that of the diffraction pattern: for example, a photographic slide whose transmittance has a Gaussian variation is also a Gaussian function.
The fact that the Gaussian function is an eigenfunction of the continuous Fourier transform allows us to derive the following interesting[clarification needed] identity from the Poisson summation formula:
Integral of a Gaussian function
The integral of an arbitrary Gaussian function is
An alternative form is
where f must be strictly positive for the integral to converge.
Relation to standard Gaussian integral
The integral
for some real constants a, b, c > 0 can be calculated by putting it into the form of a Gaussian integral. First, the constant a can simply be factored out of the integral. Next, the variable of integration is changed from x to y = x − b:
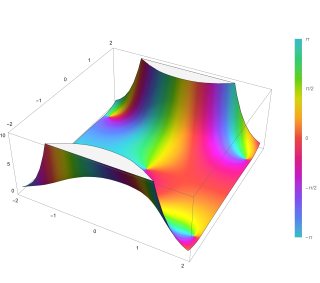
3d plot of a Gaussian function with a two-dimensional domain
Base form:
In two dimensions, the power to which e is raised in the Gaussian function is any negative-definite quadratic form. Consequently, the level sets of the Gaussian will always be ellipses.
A particular example of a two-dimensional Gaussian function is
Here the coefficient A is the amplitude, x0,y0 is the center, and σx,σy are the x and y spreads of the blob. The figure on the right was created using A = 1, x0 = 0, y0 = 0, σx = σy = 1.
The volume under the Gaussian function is given by
In general, a two-dimensional elliptical Gaussian function is expressed as
A more general formulation of a Gaussian function with a flat-top and Gaussian fall-off can be taken by raising the content of the exponent to a power :
This function is known as a super-Gaussian function and is often used for Gaussian beam formulation.[4] This function may also be expressed in terms of the full width at half maximum (FWHM), represented by w:
In a two-dimensional formulation, a Gaussian function along and can be combined[5] with potentially different and to form a rectangular Gaussian distribution:
The integral of this Gaussian function over the whole -dimensional space is given as
It can be easily calculated by diagonalizing the matrix and changing the integration variables to the eigenvectors of .
More generally a shifted Gaussian function is defined as
where is the shift vector and the matrix can be assumed to be symmetric, , and positive-definite. The following integrals with this function can be calculated with the same technique:
A number of fields such as stellar photometry, Gaussian beam characterization, and emission/absorption line spectroscopy work with sampled Gaussian functions and need to accurately estimate the height, position, and width parameters of the function. There are three unknown parameters for a 1D Gaussian function (a, b, c) and five for a 2D Gaussian function .
The most common method for estimating the Gaussian parameters is to take the logarithm of the data and fit a parabola to the resulting data set.[6][7] While this provides a simple curve fitting procedure, the resulting algorithm may be biased by excessively weighting small data values, which can produce large errors in the profile estimate. One can partially compensate for this problem through weighted least squares estimation, reducing the weight of small data values, but this too can be biased by allowing the tail of the Gaussian to dominate the fit. In order to remove the bias, one can instead use an iteratively reweighted least squares procedure, in which the weights are updated at each iteration.[7] It is also possible to perform non-linear regression directly on the data, without involving the logarithmic data transformation; for more options, see probability distribution fitting.
Parameter precision
Once one has an algorithm for estimating the Gaussian function parameters, it is also important to know how precise those estimates are. Any least squares estimation algorithm can provide numerical estimates for the variance of each parameter (i.e., the variance of the estimated height, position, and width of the function). One can also use Cramér–Rao bound theory to obtain an analytical expression for the lower bound on the parameter variances, given certain assumptions about the data.[8][9]
The spacing between each sampling (i.e. the distance between pixels measuring the data) is uniform.
The peak is "well-sampled", so that less than 10% of the area or volume under the peak (area if a 1D Gaussian, volume if a 2D Gaussian) lies outside the measurement region.
The width of the peak is much larger than the distance between sample locations (i.e. the detector pixels must be at least 5 times smaller than the Gaussian FWHM).
When these assumptions are satisfied, the following covariance matrixK applies for the 1D profile parameters , , and under i.i.d. Gaussian noise and under Poisson noise:[8]
where is the width of the pixels used to sample the function, is the quantum efficiency of the detector, and indicates the standard deviation of the measurement noise. Thus, the individual variances for the parameters are, in the Gaussian noise case,
and in the Poisson noise case,
For the 2D profile parameters giving the amplitude , position , and width of the profile, the following covariance matrices apply:[9]
where the individual parameter variances are given by the diagonal elements of the covariance matrix.
One may ask for a discrete analog to the Gaussian; this is necessary in discrete applications, particularly digital signal processing. A simple answer is to sample the continuous Gaussian, yielding the sampled Gaussian kernel. However, this discrete function does not have the discrete analogs of the properties of the continuous function, and can lead to undesired effects, as described in the article scale space implementation.
This is the discrete analog of the continuous Gaussian in that it is the solution to the discrete diffusion equation (discrete space, continuous time), just as the continuous Gaussian is the solution to the continuous diffusion equation.[10][11]
Gaussian functions are the Green's function for the (homogeneous and isotropic) diffusion equation (and to the heat equation, which is the same thing), a partial differential equation that describes the time evolution of a mass-density under diffusion. Specifically, if the mass-density at time t=0 is given by a Dirac delta, which essentially means that the mass is initially concentrated in a single point, then the mass-distribution at time t will be given by a Gaussian function, with the parameter a being linearly related to 1/√t and c being linearly related to √t; this time-varying Gaussian is described by the heat kernel. More generally, if the initial mass-density is φ(x), then the mass-density at later times is obtained by taking the convolution of φ with a Gaussian function. The convolution of a function with a Gaussian is also known as a Weierstrass transform.
Mathematically, the derivatives of the Gaussian function can be represented using Hermite functions. For unit variance, the n-th derivative of the Gaussian is the Gaussian function itself multiplied by the n-th Hermite polynomial, up to scale.
Gaussian beams are used in optical systems, microwave systems and lasers.
In scale space representation, Gaussian functions are used as smoothing kernels for generating multi-scale representations in computer vision and image processing. Specifically, derivatives of Gaussians (Hermite functions) are used as a basis for defining a large number of types of visual operations.
In geostatistics they have been used for understanding the variability between the patterns of a complex training image. They are used with kernel methods to cluster the patterns in the feature space.[13]
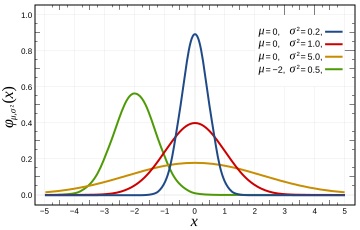
In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is
The uncertainty principle, also known as Heisenberg's indeterminacy principle, is a fundamental concept in quantum mechanics. It states that there is a limit to the precision with which certain pairs of physical properties, such as position and momentum, can be simultaneously known. In other words, the more accurately one property is measured, the less accurately the other property can be known.
In mathematics, the error function, often denoted by erf, is a function defined as:
In mathematics, a Green's function is the impulse response of an inhomogeneous linear differential operator defined on a domain with specified initial conditions or boundary conditions.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In mathematics, the Dawson function or Dawson integral (named after H. G. Dawson) is the one-sided Fourier–Laplace sine transform of the Gaussian function.
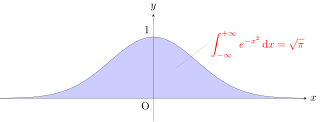
The Gaussian integral, also known as the Euler–Poisson integral, is the integral of the Gaussian function over the entire real line. Named after the German mathematician Carl Friedrich Gauss, the integral is
In mathematics, Laplace's method, named after Pierre-Simon Laplace, is a technique used to approximate integrals of the form
The Voigt profile is a probability distribution given by a convolution of a Cauchy-Lorentz distribution and a Gaussian distribution. It is often used in analyzing data from spectroscopy or diffraction.
In probability theory, the Rice distribution or Rician distribution is the probability distribution of the magnitude of a circularly-symmetric bivariate normal random variable, possibly with non-zero mean (noncentral). It was named after Stephen O. Rice (1907–1986).
In probability theory, calculation of the sum of normally distributed random variables is an instance of the arithmetic of random variables.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In statistics, the Q-function is the tail distribution function of the standard normal distribution. In other words, is the probability that a normal (Gaussian) random variable will obtain a value larger than standard deviations. Equivalently, is the probability that a standard normal random variable takes a value larger than .
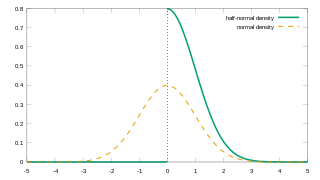
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
In numerical analysis, Gauss–Hermite quadrature is a form of Gaussian quadrature for approximating the value of integrals of the following kind:
Common integrals in quantum field theory are all variations and generalizations of Gaussian integrals to the complex plane and to multiple dimensions. Other integrals can be approximated by versions of the Gaussian integral. Fourier integrals are also considered.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product is a product distribution.
In machine learning, diffusion models, also known as diffusion probabilistic models or score-based generative models, are a class of latent variable generative models. A diffusion model consists of three major components: the forward process, the reverse process, and the sampling procedure. The goal of diffusion models is to learn a diffusion process that generates a probability distribution for a given dataset from which we can then sample new images. They learn the latent structure of a dataset by modeling the way in which data points diffuse through their latent space.
↑ Caruana, Richard A.; Searle, Roger B.; Heller, Thomas.; Shupack, Saul I. (1986). "Fast algorithm for the resolution of spectra". Analytical Chemistry. American Chemical Society (ACS). 58 (6): 1162–1167. doi:10.1021/ac00297a041. ISSN0003-2700.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.