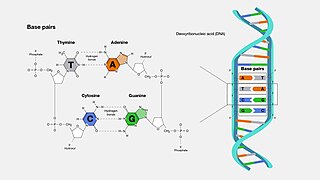
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Deoxyribonucleic acid is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.
A telomere is a region of repetitive nucleotide sequences associated with specialized proteins at the ends of linear chromosomes. Telomeres are a widespread genetic feature most commonly found in eukaryotes. In most, if not all species possessing them, they protect the terminal regions of chromosomal DNA from progressive degradation and ensure the integrity of linear chromosomes by preventing DNA repair systems from mistaking the very ends of the DNA strand for a double-strand break.

Nucleobases are nitrogen-containing biological compounds that form nucleosides, which, in turn, are components of nucleotides, with all of these monomers constituting the basic building blocks of nucleic acids. The ability of nucleobases to form base pairs and to stack one upon another leads directly to long-chain helical structures such as ribonucleic acid (RNA) and deoxyribonucleic acid (DNA). Five nucleobases—adenine (A), cytosine (C), guanine (G), thymine (T), and uracil (U)—are called primary or canonical. They function as the fundamental units of the genetic code, with the bases A, G, C, and T being found in DNA while A, G, C, and U are found in RNA. Thymine and uracil are distinguished by merely the presence or absence of a methyl group on the fifth carbon (C5) of these heterocyclic six-membered rings. In addition, some viruses have aminoadenine (Z) instead of adenine. It differs in having an extra amine group, creating a more stable bond to thymine.
In a chain-like biological molecule, such as a protein or nucleic acid, a structural motif is a common three-dimensional structure that appears in a variety of different, evolutionarily unrelated molecules. A structural motif does not have to be associated with a sequence motif; it can be represented by different and completely unrelated sequences in different proteins or RNA.

A Hoogsteen base pair is a variation of base-pairing in nucleic acids such as the A•T pair. In this manner, two nucleobases, one on each strand, can be held together by hydrogen bonds in the major groove. A Hoogsteen base pair applies the N7 position of the purine base and C6 amino group, which bind the Watson–Crick (N3–C4) face of the pyrimidine base.

Triple-stranded DNA is a DNA structure in which three oligonucleotides wind around each other and form a triple helix. In triple-stranded DNA, the third strand binds to a B-form DNA double helix by forming Hoogsteen base pairs or reversed Hoogsteen hydrogen bonds.

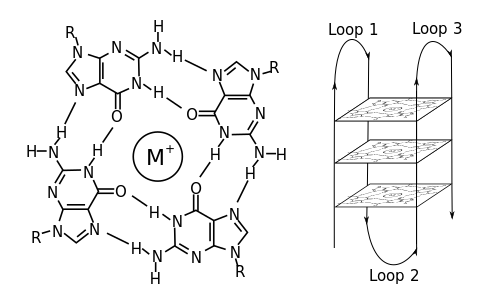
In molecular biology, G-quadruplex secondary structures (G4) are formed in nucleic acids by sequences that are rich in guanine. They are helical in shape and contain guanine tetrads that can form from one, two or four strands. The unimolecular forms often occur naturally near the ends of the chromosomes, better known as the telomeric regions, and in transcriptional regulatory regions of multiple genes, both in microbes and across vertebrates including oncogenes in humans. Four guanine bases can associate through Hoogsteen hydrogen bonding to form a square planar structure called a guanine tetrad, and two or more guanine tetrads can stack on top of each other to form a G-quadruplex.
In biochemistry, two biopolymers are antiparallel if they run parallel to each other but with opposite directionality (alignments). An example is the two complementary strands of a DNA double helix, which run in opposite directions alongside each other.
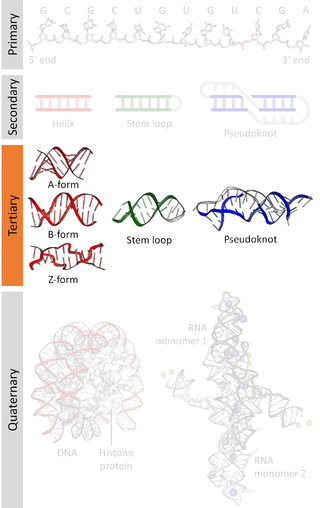
Nucleic acid tertiary structure is the three-dimensional shape of a nucleic acid polymer. RNA and DNA molecules are capable of diverse functions ranging from molecular recognition to catalysis. Such functions require a precise three-dimensional structure. While such structures are diverse and seemingly complex, they are composed of recurring, easily recognizable tertiary structural motifs that serve as molecular building blocks. Some of the most common motifs for RNA and DNA tertiary structure are described below, but this information is based on a limited number of solved structures. Many more tertiary structural motifs will be revealed as new RNA and DNA molecules are structurally characterized.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
Twisted intercalating nucleic acid (TINA) is a nucleic acid molecule that, when added to triplex-forming oligonucleotides (TFOs), stabilizes Hoogsteen triplex DNA formation from double-stranded DNA (dsDNA) and TFOs. Its ability to twist around a triple bond increases ease of intercalation within double stranded DNA in order to form triplex DNA. Certain configurations have been shown to stabilize Watson-Crick antiparallel duplex DNA. TINA-DNA primers have been shown to increase the specificity of binding in PCR. The use of TINA insertions in G-quadruplexes has also been shown to enhance anti-HIV-1 activity. TINA stabilized PT demonstrates improved sensitivity and specificity of DNA based clinical diagnostic assays.

Telomeric repeat–containing RNA (TERRA) is a long non-coding RNA transcribed from telomeres - repetitive nucleotide regions found on the ends of chromosomes that function to protect DNA from deterioration or fusion with neighboring chromosomes. TERRA has been shown to be ubiquitously expressed in almost all cell types containing linear chromosomes - including humans, mice, and yeasts. While the exact function of TERRA is still an active area of research, it is generally believed to play a role in regulating telomerase activity as well as maintaining the heterochromatic state at the ends of chromosomes. TERRA interaction with other associated telomeric proteins has also been shown to help regulate telomere integrity in a length-dependent manner.
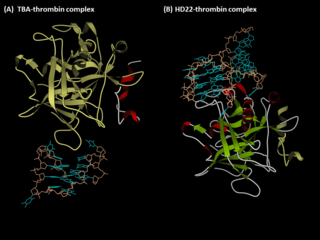
Anti-thrombin aptamers are G-quadruplex-bearing oligonucleotides, which recognizes the exosites of human thrombin. The first anti-thrombin aptamer, TBA, was generated through via SELEX technology in 1992 by L.C. Bock, J.J. Toole and colleagues. A second thrombin-binding aptamer, HD22, recognizes thrombin exosite II and was discovered in 1997 by NeXstar. These two aptamers have high affinity and good specificity and have been widely studied and used for the development of aptamer-based therapeutics and diagnostics.
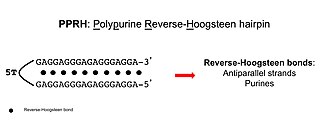
Polypurine reverse-Hoogsteen hairpins (PPRHs) are non-modified oligonucleotides containing two polypurine domains, in a mirror repeat fashion, linked by a pentathymidine stretch forming double-stranded DNA stem-loop molecules. The two polypurine domains interact by intramolecular reverse-Hoogsteen bonds allowing the formation of this specific hairpin structure.

Cynthia J. Burrows is an American chemist, currently a distinguished professor in the department of chemistry at the University of Utah, where she is also the Thatcher Presidential Endowed Chair of Biological Chemistry. Burrows was the Senior Editor of the Journal of Organic Chemistry (2001-2013) and became Editor-in-Chief of Accounts of Chemical Research in 2014.,,
Non-canonical base pairs are planar hydrogen bonded pairs of nucleobases, having hydrogen bonding patterns which differ from the patterns observed in Watson-Crick base pairs, as in the classic double helical DNA. The structures of polynucleotide strands of both DNA and RNA molecules can be understood in terms of sugar-phosphate backbones consisting of phosphodiester-linked D 2’ deoxyribofuranose sugar moieties, with purine or pyrimidine nucleobases covalently linked to them. Here, the N9 atoms of the purines, guanine and adenine, and the N1 atoms of the pyrimidines, cytosine and thymine, respectively, form glycosidic linkages with the C1’ atom of the sugars. These nucleobases can be schematically represented as triangles with one of their vertices linked to the sugar, and the three sides accounting for three edges through which they can form hydrogen bonds with other moieties, including with other nucleobases. The side opposite to the sugar linked vertex is traditionally called the Watson-Crick edge, since they are involved in forming the Watson-Crick base pairs which constitute building blocks of double helical DNA. The two sides adjacent to the sugar-linked vertex are referred to, respectively, as the Sugar and Hoogsteen edges.
i-motif DNA, short for intercalated-motif DNA, are cytosine-rich four-stranded quadruplex DNA structures, similar to the G-quadruplex structures that are formed in guanine-rich regions of DNA.
Professor Stephen Neidle is a British X-ray crystallographer, chemist and drug designer working at the UCL School of Pharmacy. His area of scientific research has been in nucleic acid structure and recognition, and the research topic of quadruplexes.
Non-B DNA refers to DNA conformations that differ from the canonical B-DNA conformation, the most common form of DNA found in nature at neutral pH and physiological salt concentrations. Non-B DNA structures can arise due to various factors, including DNA sequence, length, supercoiling, and environmental conditions. Non-B DNA structures can have important biological roles, but they can also cause problems, such as genomic instability and disease.