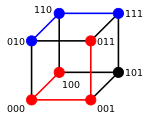
Two example distances: 100→011 has distance 3; 010→111 has distance 2
The minimum distance between any two vertices is the Hamming distance between the two binary strings.
In information theory, the Hamming distance between two strings or vectors of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other, or equivalently, the minimum number of errors that could have transformed one string into the other. In a more general context, the Hamming distance is one of several string metrics for measuring the edit distance between two sequences. It is named after the American mathematician Richard Hamming.
The Hamming distance between two equal-length strings of symbols is the number of positions at which the corresponding symbols are different.[1]
Examples
The symbols may be letters, bits, or decimal digits, among other possibilities. For example, the Hamming distance between:
"karolin" and "kathrin" is 3.
"karolin" and "kerstin" is 3.
"kathrin" and "kerstin" is 4.
0000 and 1111 is 4.
2173896 and 2233796 is 3.
Properties
For a fixed length n, the Hamming distance is a metric on the set of the words of length n (also known as a Hamming space), as it fulfills the conditions of non-negativity, symmetry, the Hamming distance of two words is 0 if and only if the two words are identical, and it satisfies the triangle inequality as well:[2] Indeed, if we fix three words a, b and c, then whenever there is a difference between the ith letter of a and the ith letter of c, then there must be a difference between the ith letter of a and ith letter of b, or between the ith letter of b and the ith letter of c. Hence the Hamming distance between a and c is not larger than the sum of the Hamming distances between a and b and between b and c. The Hamming distance between two words a and b can also be seen as the Hamming weight of a − b for an appropriate choice of the − operator, much as the difference between two integers can be seen as a distance from zero on the number line.[clarification needed]
For binary strings a and b the Hamming distance is equal to the number of ones (population count) in aXORb.[3] The metric space of length-n binary strings, with the Hamming distance, is known as the Hamming cube; it is equivalent as a metric space to the set of distances between vertices in a hypercube graph. One can also view a binary string of length n as a vector in by treating each symbol in the string as a real coordinate; with this embedding, the strings form the vertices of an n-dimensional hypercube, and the Hamming distance of the strings is equivalent to the Manhattan distance between the vertices.
Error detection and error correction
The minimum Hamming distance or minimum distance (usually denoted by dmin) is used to define some essential notions in coding theory, such as error detecting and error correcting codes. In particular, a codeC is said to be k error detecting if, and only if, the minimum Hamming distance between any two of its codewords is at least k+1.[2]
For example, consider a code consisting of two codewords "000" and "111". The Hamming distance between these two words is 3, and therefore it is k=2 error detecting. This means that if one bit is flipped or two bits are flipped, the error can be detected. If three bits are flipped, then "000" becomes "111" and the error cannot be detected.
A code C is said to be k-error correcting if, for every word w in the underlying Hamming space H, there exists at most one codeword c (from C) such that the Hamming distance between w and c is at most k. In other words, a code is k-errors correcting if the minimum Hamming distance between any two of its codewords is at least 2k+1. This is also understood geometrically as any closed balls of radius k centered on distinct codewords being disjoint.[2] These balls are also called Hamming spheres in this context.[4]
For example, consider the same 3-bit code consisting of the two codewords "000" and "111". The Hamming space consists of 8 words 000, 001, 010, 011, 100, 101, 110 and 111. The codeword "000" and the single bit error words "001","010","100" are all less than or equal to the Hamming distance of 1 to "000". Likewise, codeword "111" and its single bit error words "110","101" and "011" are all within 1 Hamming distance of the original "111". In this code, a single bit error is always within 1 Hamming distance of the original codes, and the code can be 1-error correcting, that is k=1. Since the Hamming distance between "000" and "111" is 3, and those comprise the entire set of codewords in the code, the minimum Hamming distance is 3, which satisfies 2k+1 = 3.
Thus a code with minimum Hamming distance d between its codewords can detect at most d-1 errors and can correct ⌊(d-1)/2⌋ errors.[2] The latter number is also called the packing radius or the error-correcting capability of the code.[4]
It is used in telecommunication to count the number of flipped bits in a fixed-length binary word as an estimate of error, and therefore is sometimes called the signal distance.[7] For q-ary strings over an alphabet of size q≥2 the Hamming distance is applied in case of the q-ary symmetric channel, while the Lee distance is used for phase-shift keying or more generally channels susceptible to synchronization errors because the Lee distance accounts for errors of ±1.[8] If or both distances coincide because any pair of elements from or differ by 1, but the distances are different for larger .
The Hamming distance is also used in systematics as a measure of genetic distance.[9]
However, for comparing strings of different lengths, or strings where not just substitutions but also insertions or deletions have to be expected, a more sophisticated metric such as the Levenshtein distance may be more appropriate.[10]:32
Algorithm example
The following function, written in Python 3, returns the Hamming distance between two strings:
defhamming_distance(string1:str,string2:str)->int:"""Return the Hamming distance between two strings."""iflen(string1)!=len(string2):raiseValueError("Strings must be of equal length.")dist_counter=0forninrange(len(string1)):ifstring1[n]!=string2[n]:dist_counter+=1returndist_counter
The following C function will compute the Hamming distance of two integers (considered as binary values, that is, as sequences of bits). The running time of this procedure is proportional to the Hamming distance rather than to the number of bits in the inputs. It computes the bitwiseexclusive or of the two inputs, and then finds the Hamming weight of the result (the number of nonzero bits) using an algorithm of Wegner (1960) that repeatedly finds and clears the lowest-order nonzero bit. Some compilers support the __builtin_popcount function which can calculate this using specialized processor hardware where available.
inthamming_distance(unsignedx,unsignedy){intdist=0;// The ^ operators sets to 1 only the bits that are differentfor(unsignedval=x^y;val>0;++dist){// We then count the bit set to 1 using the Peter Wegner wayval=val&(val-1);// Set to zero val's lowest-order 1}// Return the number of differing bitsreturndist;}
A faster alternative is to use the population count (popcount) assembly instruction. Certain compilers such as GCC and Clang make it available via an intrinsic function:
// Hamming distance for 32-bit integersinthamming_distance32(unsignedintx,unsignedinty){return__builtin_popcount(x^y);}// Hamming distance for 64-bit integersinthamming_distance64(unsignedlonglongx,unsignedlonglongy){return__builtin_popcountll(x^y);}
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.