Related Research Articles

The Cyrillic script is a writing system used for various languages across Eurasia and is used as the national script in various Slavic, Turkic, Mongolic, Uralic, Caucasian and Iranic-speaking countries in Southeastern Europe, Eastern Europe, the Caucasus, Central Asia, North Asia, and East Asia.

Mojibake is the garbled text that is the result of text being decoded using an unintended character encoding. The result is a systematic replacement of symbols with completely unrelated ones, often from a different writing system.

Tajik, also called Tajiki Persian, Tajiki, and Tadzhiki, is the variety of Persian spoken in Tajikistan and Uzbekistan by Tajiks. It is closely related to neighbouring Dari with which it forms a continuum of mutually intelligible varieties of the Persian language. Several scholars consider Tajik as a dialectal variety of Persian rather than a language on its own. The popularity of this conception of Tajik as a variety of Persian was such that, during the period in which Tajik intellectuals were trying to establish Tajik as a language separate from Persian, prominent intellectual Sadriddin Ayni counterargued that Tajik was not a "bastardised dialect" of Persian. The issue of whether Tajik and Persian are to be considered two dialects of a single language or two discrete languages has political sides to it.
ISO/IEC 8859-5:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 5: Latin/Cyrillic alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1988. It is informally referred to as Latin/Cyrillic. It was designed to cover languages using a Cyrillic alphabet such as Bulgarian, Belarusian, Russian, Serbian and Macedonian but was never widely used. It would also have been usable for Ukrainian in the Soviet Union from 1933 to 1990, but it is missing the Ukrainian letter ge, ґ, which is required in Ukrainian orthography before and since, and during that period outside Soviet Ukraine. As a result, IBM created Code page 1124.
KOI8-R is an 8-bit character encoding, derived from the KOI-8 encoding by the programmer Andrei Chernov in 1993 and designed to cover Russian, which uses a Cyrillic alphabet. KOI8-R was based on Russian Morse code, which was created from a phonetic version of Latin Morse code. As a result, Russian Cyrillic letters are in pseudo-Roman order rather than the normal Cyrillic alphabetical order. Although this may seem unnatural, if the 8th bit is stripped, the text is partially readable in ASCII and may convert to syntactically correct KOI7. For example, "Русский Текст" in KOI8-R becomes rUSSKIJ tEKST.
KOI8-U is an 8-bit character encoding, designed to cover Ukrainian, which uses a Cyrillic alphabet. It is based on KOI8-R, which covers Russian and Bulgarian, but replaces eight box drawing characters with four Ukrainian letters Ґ, Є, І, and Ї in both upper case and lower case.
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
KOI (КОИ) is a family of several code pages for the Cyrillic script. The name stands for Kod obmena informatsiey which means "Code for Information Interchange".
KOI-8 (КОИ-8) is an 8-bit character set standardized in GOST 19768-74. It is an extension of KOI-7 which allows the use of the Latin alphabet along with the Russian alphabet, both the upper and lower case letters; however, the letter Ёё and the uppercase Ъ are missed, the latter to avoid conflicts with the delete character. The first 127 code points are identical to ASCII with the exception of the dollar sign $ replaced by the universal currency sign ¤. The rows x8_ and x9_ might be filled with the additional control characters from EBCDIC.
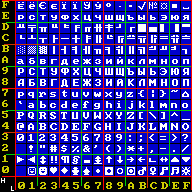
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially, this encoding was only available in the Russian version of MS-DOS 4.01 (1990) and since MS-DOS 6.22 in any language version.
KOI-7 (КОИ-7) is a 7-bit character encoding, designed to cover Russian, which uses the Cyrillic alphabet.
The currency sign¤ is a character used to denote an unspecified currency. It can be described as a circle the size of a lowercase character with four short radiating arms at 45° (NE), 135° (SE), 225° (SW) and 315° (NW). It is raised slightly above the baseline. The character is sometimes called scarab.
Windows code pages are sets of characters or code pages used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows, although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
YUSCII is an informal name for several JUS standards for 7-bit character encoding. These include:
KOI8-RU is an 8-bit character encoding, designed to cover Russian, Ukrainian, and Belarusian which use a Cyrillic alphabet. It is closely related to KOI8-R, which covers Russian and Bulgarian, but replaces ten box drawing characters with five Ukrainian and Belarusian letters Ґ, Є, І, Ї, and Ў in both upper case and lower case. It is even more closely related to KOI8-U, which does not include Ў but otherwise makes the same replacements. The additional letter allocations are matched by KOI8-E, except for Ґ which is added to KOI8-F.
ISO-IR-153 is an 8-bit character set that covers the Russian and Bulgarian alphabets. Unlike the KOI encodings, this encoding lists the Cyrillic letters in their correct traditional order. This has become the basis for ISO/IEC 8859-5 and the Cyrillic Unicode block.
ISO-IR-111 or KOI8-E is an 8-bit character set. It is a multinational extension of KOI-8 for Belarusian, Macedonian, Serbian, and Ukrainian. The name "ISO-IR-111" refers to its registration number in the ISO-IR registry, and denotes it as a set usable with ISO/IEC 2022.
The Macintosh Turkic Cyrillic encoding is used in Apple Macintosh computers to represent texts in the Cyrillic script for Turkic languages. It was created by Michael Everson for use in his fonts, but is not an official Mac OS Codepage. It supports Azerbaijani, Bashkir, Kazakh, Kyrgyz, Tajik, Tatar, Turkmen, and Uzbek.
Windows Cyrillic + German is a modification of Windows-1251 that was used by Paratype to cover languages that use the Cyrillic script such as Russian, Bulgarian, and Serbian Cyrillic on a German language keyboard. This encoding was also used by Gamma Unitype. This encoding is supported by FontLab Studio 5.
Windows Cyrillic + French is a modification of Windows-1251 that was used by Paratype to cover languages that use the Cyrillic script such as Russian and Bulgarian on a French language keyboard. This encoding was also used by Gamma Unitype. This encoding is supported by FontLab Studio 5.
References
- 1 2 Flohr, Guido. "Locale::RecodeData::KOI8_T - Conversion routines for KOI8-T". libintl-perl-1.31. CPAN.
- 1 2 Davis, Michael (2000-11-21). "Tajiki TrueType fonts for the Web: Frequently Asked Questions". Travel Tajikistan. Archived from the original on 2001-10-05.
- ↑ Storchaka, Serhiy (2014-10-20). "Add support of KOI8-T encoding". Python Bug Tracker.