
Artificial neural networks (ANNs), usually simply called neural networks (NNs) or neural nets, are computing systems inspired by the biological neural networks that constitute animal brains.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers with the main benefit of searchability. It is also known as automatic speech recognition (ASR), computer speech recognition or speech to text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.

A neural network is a network or circuit of biological neurons, or, in a modern sense, an artificial neural network, composed of artificial neurons or nodes. Thus, a neural network is either a biological neural network, made up of biological neurons, or an artificial neural network, used for solving artificial intelligence (AI) problems. The connections of the biological neuron are modeled in artificial neural networks as weights between nodes. A positive weight reflects an excitatory connection, while negative values mean inhibitory connections. All inputs are modified by a weight and summed. This activity is referred to as a linear combination. Finally, an activation function controls the amplitude of the output. For example, an acceptable range of output is usually between 0 and 1, or it could be −1 and 1.
As of the early 2000s, several speech recognition (SR) software packages exist for Linux. Some of them are free and open-source software and others are proprietary software. Speech recognition usually refers to software that attempts to distinguish thousands of words in a human language. Voice control may refer to software used for communicating operational commands to a computer.
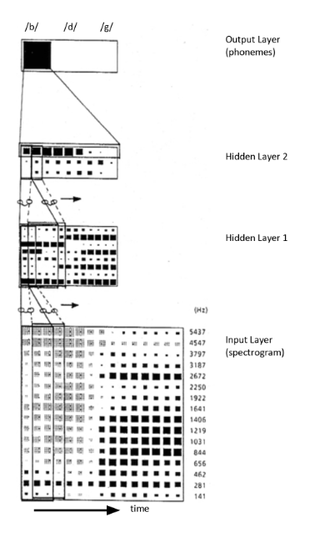
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
RWTH ASR is a proprietary speech recognition toolkit.

Deep learning is part of a broader family of machine learning methods based on artificial neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised.
Nelson Harold Morgan is an American computer scientist and professor in residence (emeritus) of electrical engineering and computer science at the University of California, Berkeley. Morgan is the co-inventor of the Relative Spectral (RASTA) approach to speech signal processing, first described in a technical report published in 1991.

In deep learning, a convolutional neural network is a class of artificial neural network (ANN), most commonly applied to analyze visual imagery. CNNs are also known as Shift Invariant or Space Invariant Artificial Neural Networks (SIANN), based on the shared-weight architecture of the convolution kernels or filters that slide along input features and provide translation-equivariant responses known as feature maps. Counter-intuitively, most convolutional neural networks are not invariant to translation, due to the downsampling operation they apply to the input. They have applications in image and video recognition, recommender systems, image classification, image segmentation, medical image analysis, natural language processing, brain–computer interfaces, and financial time series.
In signal processing, Feature space Maximum Likelihood Linear Regression (fMLLR) is a global feature transform that are typically applied in a speaker adaptive way, where fMLLR transforms acoustic features to speaker adapted features by a multiplication operation with a transformation matrix. In some literature, fMLLR is also known as the Constrained Maximum Likelihood Linear Regression (cMLLR).

Keras is an open-source software library that provides a Python interface for artificial neural networks. Keras acts as an interface for the TensorFlow library.

spaCy is an open-source software library for advanced natural language processing, written in the programming languages Python and Cython. The library is published under the MIT license and its main developers are Matthew Honnibal and Ines Montani, the founders of the software company Explosion.
The following outline is provided as an overview of and topical guide to machine learning. Machine learning is a subfield of soft computing within computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. In 1959, Arthur Samuel defined machine learning as a "field of study that gives computers the ability to learn without being explicitly programmed". Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from an example training set of input observations in order to make data-driven predictions or decisions expressed as outputs, rather than following strictly static program instructions.

Stephen John Young is a British researcher, Professor of Information Engineering at the University of Cambridge and an entrepreneur. He is one of the pioneers of automated speech recognition and statistical spoken dialogue systems. He served as the Senior Pro-Vice-Chancellor of the University of Cambridge from 2009 to 2015, responsible for planning and resources. From 2015 to 2019, he held a joint appointment between his professorship at Cambridge and Apple, where he was a senior member of the Siri development team.
The Open Neural Network Exchange (ONNX) [] is an open-source artificial intelligence ecosystem of technology companies and research organizations that establish open standards for representing machine learning algorithms and software tools to promote innovation and collaboration in the AI sector. ONNX is available on GitHub.
Beijing Unisound Information Technology Co., Ltd., often shortened to Unisound, is a Chinese technology company based in Beijing. It is a unicorn startup specialising in speech recognition and artificial intelligence services applicable to a variety of industries.
OpenVINO toolkit is a free toolkit facilitating the optimization of a deep learning model from a framework and deployment using an inference engine onto Intel hardware. The toolkit has two versions: OpenVINO toolkit, which is supported by open source community and Intel Distribution of OpenVINO toolkit, which is supported by Intel. OpenVINO was developed by Intel. The toolkit is cross-platform and free for use under Apache License version 2.0. The toolkit enables a write-once, deploy-anywhere approach to deep learning deployments on Intel platforms, including CPU, integrated GPU, Intel Movidius VPU, and FPGAs.
The audio deepfake is a type of artificial intelligence used to create convincing speech sentences that sound like specific people saying things they did not say. This technology was initially developed for various applications to improve human life. For example, it can be used to produce audiobooks, and also to help people who have lost their voices to get them back. Commercially, it has opened the door to several opportunities. This technology can also create more personalized digital assistants and natural-sounding speech translation services.