
In formal language theory, a context-free grammar (CFG) is a formal grammar whose production rules can be applied to a nonterminal symbol regardless of its context. In particular, in a context-free grammar, each production rule is of the form
In computer science, the Earley parser is an algorithm for parsing strings that belong to a given context-free language, though it may suffer problems with certain nullable grammars. The algorithm, named after its inventor, Jay Earley, is a chart parser that uses dynamic programming; it is mainly used for parsing in computational linguistics. It was first introduced in his dissertation in 1968.
In computer science, LR parsers are a type of bottom-up parser that analyse deterministic context-free languages in linear time. There are several variants of LR parsers: SLR parsers, LALR parsers, canonical LR(1) parsers, minimal LR(1) parsers, and generalized LR parsers. LR parsers can be generated by a parser generator from a formal grammar defining the syntax of the language to be parsed. They are widely used for the processing of computer languages.
Yacc is a computer program for the Unix operating system developed by Stephen C. Johnson. It is a lookahead left-to-right rightmost derivation (LALR) parser generator, generating a LALR parser based on a formal grammar, written in a notation similar to Backus–Naur form (BNF). Yacc is supplied as a standard utility on BSD and AT&T Unix. GNU-based Linux distributions include Bison, a forward-compatible Yacc replacement.
GNU Bison, commonly known as Bison, is a parser generator that is part of the GNU Project. Bison reads a specification in Bison syntax, warns about any parsing ambiguities, and generates a parser that reads sequences of tokens and decides whether the sequence conforms to the syntax specified by the grammar.
In computer science, an LL parser is a top-down parser for a restricted context-free language. It parses the input from Left to right, performing Leftmost derivation of the sentence.
In computer science, a Simple LR or SLR parser is a type of LR parser with small parse tables and a relatively simple parser generator algorithm. As with other types of LR(1) parser, an SLR parser is quite efficient at finding the single correct bottom-up parse in a single left-to-right scan over the input stream, without guesswork or backtracking. The parser is mechanically generated from a formal grammar for the language.
A canonical LR parser is a type of bottom-up parsing algorithm used in computer science to analyze and process programming languages. It is based on the LR parsing technique, which stands for "left-to-right, rightmost derivation in reverse."
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
Top-down parsing in computer science is a parsing strategy where one first looks at the highest level of the parse tree and works down the parse tree by using the rewriting rules of a formal grammar. LL parsers are a type of parser that uses a top-down parsing strategy.
The dangling else is a problem in programming of parser generators in which an optional else clause in an if–then(–else) statement results in nested conditionals being ambiguous. Formally, the reference context-free grammar of the language is ambiguous, meaning there is more than one correct parse tree.
Berkeley Yacc (byacc) is a Unix parser generator designed to be compatible with Yacc. It was originally written by Robert Corbett and released in 1989. Due to its liberal license and because it was faster than the AT&T Yacc, it quickly became the most popular version of Yacc. It has the advantages of being written in ANSI C89 and being public domain software.
A GLR parser is an extension of an LR parser algorithm to handle non-deterministic and ambiguous grammars. The theoretical foundation was provided in a 1974 paper by Bernard Lang. It describes a systematic way to produce such algorithms, and provides uniform results regarding correctness proofs, complexity with respect to grammar classes, and optimization techniques. The first actual implementation of GLR was described in a 1984 paper by Masaru Tomita, it has also been referred to as a "parallel parser". Tomita presented five stages in his original work, though in practice it is the second stage that is recognized as the GLR parser.
In formal grammar theory, the deterministic context-free grammars (DCFGs) are a proper subset of the context-free grammars. They are the subset of context-free grammars that can be derived from deterministic pushdown automata, and they generate the deterministic context-free languages. DCFGs are always unambiguous, and are an important subclass of unambiguous CFGs; there are non-deterministic unambiguous CFGs, however.
In computer science, recursive ascent parsing is a technique for implementing an LR parser which uses mutually-recursive functions rather than tables. Thus, the parser is directly encoded in the host language similar to recursive descent. Direct encoding usually yields a parser which is faster than its table-driven equivalent for the same reason that compilation is faster than interpretation. It is also (nominally) possible to hand edit a recursive ascent parser, whereas a tabular implementation is nigh unreadable to the average human.

In computing, a compiler is a computer program that transforms source code written in a programming language or computer language, into another computer language. The most common reason for transforming source code is to create an executable program.
SLR grammars are the class of formal grammars accepted by a Simple LR parser. SLR grammars are a superset of all LR(0) grammars and a subset of all LALR(1) and LR(1) grammars.
A lookahead LR parser (LALR) generator is a software tool that reads a context-free grammar (CFG) and creates an LALR parser which is capable of parsing files written in the context-free language defined by the CFG. LALR parsers are desirable because they are very fast and small in comparison to other types of parsers.
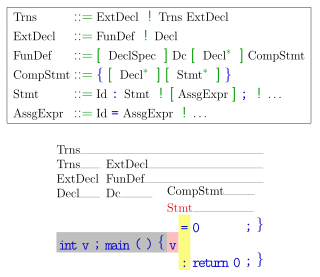
In formal language theory, an LL grammar is a context-free grammar that can be parsed by an LL parser, which parses the input from Left to right, and constructs a Leftmost derivation of the sentence. A language that has an LL grammar is known as an LL language. These form subsets of deterministic context-free grammars (DCFGs) and deterministic context-free languages (DCFLs), respectively. One says that a given grammar or language "is an LL grammar/language" or simply "is LL" to indicate that it is in this class.
A shift-reduce parser is a class of efficient, table-driven bottom-up parsing methods for computer languages and other notations formally defined by a grammar. The parsing methods most commonly used for parsing programming languages, LR parsing and its variations, are shift-reduce methods. The precedence parsers used before the invention of LR parsing are also shift-reduce methods. All shift-reduce parsers have similar outward effects, in the incremental order in which they build a parse tree or call specific output actions.
