The erlang is a dimensionless unit that is used in telephony as a measure of offered load or carried load on service-providing elements such as telephone circuits or telephone switching equipment. A single cord circuit has the capacity to be used for 60 minutes in one hour. Full utilization of that capacity, 60 minutes of traffic, constitutes 1 erlang.

Queueing theory is the mathematical study of waiting lines, or queues. A queueing model is constructed so that queue lengths and waiting time can be predicted. Queueing theory is generally considered a branch of operations research because the results are often used when making business decisions about the resources needed to provide a service.
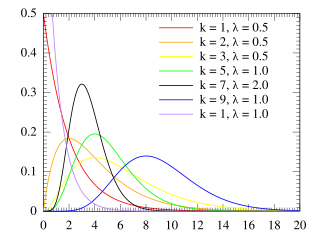
The Erlang distribution is a two-parameter family of continuous probability distributions with support . The two parameters are:
In probability theory the hypoexponential distribution or the generalized Erlang distribution is a continuous distribution, that has found use in the same fields as the Erlang distribution, such as queueing theory, teletraffic engineering and more generally in stochastic processes. It is called the hypoexponetial distribution as it has a coefficient of variation less than one, compared to the hyper-exponential distribution which has coefficient of variation greater than one and the exponential distribution which has coefficient of variation of one.
The birth–death process is a special case of continuous-time Markov process where the state transitions are of only two types: "births", which increase the state variable by one and "deaths", which decrease the state by one. It was introduced by William Feller. The model's name comes from a common application, the use of such models to represent the current size of a population where the transitions are literal births and deaths. Birth–death processes have many applications in demography, queueing theory, performance engineering, epidemiology, biology and other areas. They may be used, for example, to study the evolution of bacteria, the number of people with a disease within a population, or the number of customers in line at the supermarket.
A phase-type distribution is a probability distribution constructed by a convolution or mixture of exponential distributions. It results from a system of one or more inter-related Poisson processes occurring in sequence, or phases. The sequence in which each of the phases occurs may itself be a stochastic process. The distribution can be represented by a random variable describing the time until absorption of a Markov process with one absorbing state. Each of the states of the Markov process represents one of the phases.
In queueing theory, a discipline within the mathematical theory of probability, a G-network is an open network of G-queues first introduced by Erol Gelenbe as a model for queueing systems with specific control functions, such as traffic re-routing or traffic destruction, as well as a model for neural networks. A G-queue is a network of queues with several types of novel and useful customers:
In queueing theory, a discipline within the mathematical theory of probability, the Pollaczek–Khinchine formula states a relationship between the queue length and service time distribution Laplace transforms for an M/G/1 queue. The term is also used to refer to the relationships between the mean queue length and mean waiting/service time in such a model.

In queueing theory, a discipline within the mathematical theory of probability, an M/M/1 queue represents the queue length in a system having a single server, where arrivals are determined by a Poisson process and job service times have an exponential distribution. The model name is written in Kendall's notation. The model is the most elementary of queueing models and an attractive object of study as closed-form expressions can be obtained for many metrics of interest in this model. An extension of this model with more than one server is the M/M/c queue.

In queueing theory, a discipline within the mathematical theory of probability, a fork–join queue is a queue where incoming jobs are split on arrival for service by numerous servers and joined before departure. The model is often used for parallel computations or systems where products need to be obtained simultaneously from different suppliers. The key quantity of interest in this model is usually the time taken to service a complete job. The model has been described as a "key model for the performance analysis of parallel and distributed systems." Few analytical results exist for fork–join queues, but various approximations are known.
In queueing theory, a discipline within the mathematical theory of probability, mean value analysis (MVA) is a recursive technique for computing expected queue lengths, waiting time at queueing nodes and throughput in equilibrium for a closed separable system of queues. The first approximate techniques were published independently by Schweitzer and Bard, followed later by an exact version by Lavenberg and Reiser published in 1980.
In queueing theory, a discipline within the mathematical theory of probability, the M/M/c queue is a multi-server queueing model. In Kendall's notation it describes a system where arrivals form a single queue and are governed by a Poisson process, there are c servers, and job service times are exponentially distributed. It is a generalisation of the M/M/1 queue which considers only a single server. The model with infinitely many servers is the M/M/∞ queue.
In queueing theory, a discipline within the mathematical theory of probability, the backpressure routing algorithm is a method for directing traffic around a queueing network that achieves maximum network throughput, which is established using concepts of Lyapunov drift. Backpressure routing considers the situation where each job can visit multiple service nodes in the network. It is an extension of max-weight scheduling where each job visits only a single service node.
In queueing theory, a discipline within the mathematical theory of probability, an M/G/1 queue is a queue model where arrivals are Markovian, service times have a General distribution and there is a single server. The model name is written in Kendall's notation, and is an extension of the M/M/1 queue, where service times must be exponentially distributed. The classic application of the M/G/1 queue is to model performance of a fixed head hard disk.
In queueing theory, a discipline within the mathematical theory of probability, a fluid queue is a mathematical model used to describe the fluid level in a reservoir subject to randomly determined periods of filling and emptying. The term dam theory was used in earlier literature for these models. The model has been used to approximate discrete models, model the spread of wildfires, in ruin theory and to model high speed data networks. The model applies the leaky bucket algorithm to a stochastic source.
In queueing theory, a discipline within the mathematical theory of probability, the M/M/∞ queue is a multi-server queueing model where every arrival experiences immediate service and does not wait. In Kendall's notation it describes a system where arrivals are governed by a Poisson process, there are infinitely many servers, so jobs do not need to wait for a server. Each job has an exponentially distributed service time. It is a limit of the M/M/c queue model where the number of servers c becomes very large.
In queueing theory, a discipline within the mathematical theory of probability, a heavy traffic approximation is the matching of a queueing model with a diffusion process under some limiting conditions on the model's parameters. The first such result was published by John Kingman who showed that when the utilisation parameter of an M/M/1 queue is near 1 a scaled version of the queue length process can be accurately approximated by a reflected Brownian motion.
In queueing theory, a discipline within the mathematical theory of probability, an M/D/1 queue represents the queue length in a system having a single server, where arrivals are determined by a Poisson process and job service times are fixed (deterministic). The model name is written in Kendall's notation. Agner Krarup Erlang first published on this model in 1909, starting the subject of queueing theory. An extension of this model with more than one server is the M/D/c queue.
In mathematics and telecommunications, stochastic geometry models of wireless networks refer to mathematical models based on stochastic geometry that are designed to represent aspects of wireless networks. The related research consists of analyzing these models with the aim of better understanding wireless communication networks in order to predict and control various network performance metrics. The models require using techniques from stochastic geometry and related fields including point processes, spatial statistics, geometric probability, percolation theory, as well as methods from more general mathematical disciplines such as geometry, probability theory, stochastic processes, queueing theory, information theory, and Fourier analysis.

In probability theory, statistics and related fields, a Poisson point process is a type of random mathematical object that consists of points randomly located on a mathematical space with the essential feature that the points occur independently of one another. The Poisson point process is also called a Poisson random measure, Poisson random point field and Poisson point field. When the process is defined on the real number line, it is often called simply the Poisson process.


