
In computability theory and computational complexity theory, a decision problem is a problem that can be posed as a yes–no question of the input values. An example of a decision problem is deciding whether a given natural number is prime. Another is the problem "given two numbers x and y, does x evenly divide y?". The answer is either 'yes' or 'no' depending upon the values of x and y. A method for solving a decision problem, given in the form of an algorithm, is called a decision procedure for that problem. A decision procedure for the decision problem "given two numbers x and y, does x evenly divide y?" would give the steps for determining whether x evenly divides y. One such algorithm is long division. If the remainder is zero the answer is 'yes', otherwise it is 'no'. A decision problem which can be solved by an algorithm is called decidable.

A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.
The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
In computer science, the Aho–Corasick algorithm is a string-searching algorithm invented by Alfred V. Aho and Margaret J. Corasick in 1975. It is a kind of dictionary-matching algorithm that locates elements of a finite set of strings within an input text. It matches all strings simultaneously. The complexity of the algorithm is linear in the length of the strings plus the length of the searched text plus the number of output matches. Note that because all matches are found, there can be a quadratic number of matches if every substring matches.
In mathematics, the transitive closure of a binary relation R on a set X is the smallest relation on X that contains R and is transitive. For finite sets, "smallest" can be taken in its usual sense, of having the fewest related pairs; for infinite sets it is the unique minimal transitive superset of R.

In mathematics and computer science, a canonical, normal, or standardform of a mathematical object is a standard way of presenting that object as a mathematical expression. Often, it is one which provides the simplest representation of an object and which allows it to be identified in a unique way. The distinction between "canonical" and "normal" forms varies from subfield to subfield. In most fields, a canonical form specifies a unique representation for every object, while a normal form simply specifies its form, without the requirement of uniqueness.
In computer science, an abstract semantic graph (ASG) or term graph is a form of abstract syntax in which an expression of a formal or programming language is represented by a graph whose vertices are the expression's subterms. An ASG is at a higher level of abstraction than an abstract syntax tree, which is used to express the syntactic structure of an expression or program.
In computational complexity theory and computability theory, a search problem is a type of computational problem represented by a binary relation. If R is a binary relation such that field(R) ⊆ Γ+ and T is a Turing machine, then T calculates R if:
Semantic integration is the process of interrelating information from diverse sources, for example calendars and to do lists, email archives, presence information, documents of all sorts, contacts, search results, and advertising and marketing relevance derived from them. In this regard, semantics focuses on the organization of and action upon information by acting as an intermediary between heterogeneous data sources, which may conflict not only by structure but also context or value.

An and-inverter graph (AIG) is a directed, acyclic graph that represents a structural implementation of the logical functionality of a circuit or network. An AIG consists of two-input nodes representing logical conjunction, terminal nodes labeled with variable names, and edges optionally containing markers indicating logical negation. This representation of a logic function is rarely structurally efficient for large circuits, but is an efficient representation for manipulation of boolean functions. Typically, the abstract graph is represented as a data structure in software.
Ontology alignment, or ontology matching, is the process of determining correspondences between concepts in ontologies. A set of correspondences is also called an alignment. The phrase takes on a slightly different meaning, in computer science, cognitive science or philosophy.
Semantic interoperability is the ability of computer systems to exchange data with unambiguous, shared meaning. Semantic interoperability is a requirement to enable machine computable logic, inferencing, knowledge discovery, and data federation between information systems.
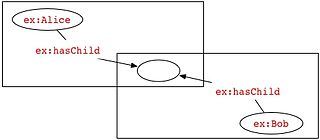
In RDF, a blank node is a node in an RDF graph representing a resource for which a URI or literal is not given. The resource represented by a blank node is also called an anonymous resource. According to the RDF standard a blank node can only be used as subject or object of an RDF triple.
The terms schema matching and mapping are often used interchangeably for a database process. For this article, we differentiate the two as follows: Schema matching is the process of identifying that two objects are semantically related while mapping refers to the transformations between the objects. For example, in the two schemas DB1.Student and DB2.Grad-Student ; possible matches would be: DB1.Student ≈ DB2.Grad-Student; DB1.SSN = DB2.ID etc. and possible transformations or mappings would be: DB1.Marks to DB2.Grades.
Semantic matching is a technique used in computer science to identify information which is semantically related.
A lightweight ontology is an ontology or knowledge organization system in which concepts are connected by rather general associations than strict formal connections. Examples of lightweight ontologies include associative network and multilingual classifications but the term is not used consistently.
In computing, a graph database (GDB) is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A key concept of the system is the graph. The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes. The relationships allow data in the store to be linked together directly and, in many cases, retrieved with one operation. Graph databases hold the relationships between data as a priority. Querying relationships is fast because they are perpetually stored in the database. Relationships can be intuitively visualized using graph databases, making them useful for heavily inter-connected data.
DSSim is an ontology mapping system, that has been conceived to achieve a certain level of the envisioned machine intelligence on the Semantic Web. The main driving factors behind its development was to provide an alternative to the existing heuristics or machine learning based approaches with a multi-agent approach that makes use of uncertain reasoning. The system provides a possible approach to establish machine understanding over Semantic Web data through multi-agent beliefs and conflict resolution.
This glossary of artificial intelligence is a list of definitions of terms and concepts relevant to the study of artificial intelligence, its sub-disciplines, and related fields. Related glossaries include Glossary of computer science, Glossary of robotics, and Glossary of machine vision.
The Mivar-based approach is a mathematical tool for designing artificial intelligence (AI) systems. Mivar was developed by combining production and Petri nets. The Mivar-based approach was developed for semantic analysis and adequate representation of humanitarian epistemological and axiological principles in the process of developing artificial intelligence. The Mivar-based approach incorporates computer science, informatics and discrete mathematics, databases, expert systems, graph theory, matrices and inference systems. The Mivar-based approach involves two technologies: