
In statistics, cluster sampling is a sampling plan used when mutually homogeneous yet internally heterogeneous groupings are evident in a statistical population. It is often used in marketing research.
In statistics, survey sampling describes the process of selecting a sample of elements from a target population to conduct a survey. The term "survey" may refer to many different types or techniques of observation. In survey sampling it most often involves a questionnaire used to measure the characteristics and/or attitudes of people. Different ways of contacting members of a sample once they have been selected is the subject of survey data collection. The purpose of sampling is to reduce the cost and/or the amount of work that it would take to survey the entire target population. A survey that measures the entire target population is called a census. A sample refers to a group or section of a population from which information is to be obtained.

In statistics, stratified sampling is a method of sampling from a population which can be partitioned into subpopulations.
Randomization is a statistical process in which a random mechanism is employed to select a sample from a population or assign subjects to different groups. The process is crucial in ensuring the random allocation of experimental units or treatment protocols, thereby minimizing selection bias and enhancing the statistical validity. It facilitates the objective comparison of treatment effects in experimental design, as it equates groups statistically by balancing both known and unknown factors at the outset of the study. In statistical terms, it underpins the principle of probabilistic equivalence among groups, allowing for the unbiased estimation of treatment effects and the generalizability of conclusions drawn from sample data to the broader population.
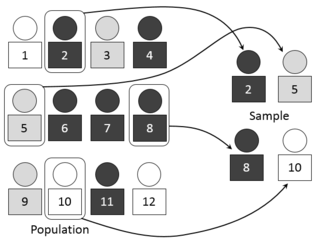
In statistics, quality assurance, and survey methodology, sampling is the selection of a subset or a statistical sample of individuals from within a statistical population to estimate characteristics of the whole population. The subset is meant to reflect the whole population and statisticians attempt to collect samples that are representative of the population. Sampling has lower costs and faster data collection compared to recording data from the entire population, and thus, it can provide insights in cases where it is infeasible to measure an entire population.
Nonprobability sampling is a form of sampling that does not utilise random sampling techniques where the probability of getting any particular sample may be calculated.
In survey methodology, one-dimensional systematic sampling is a statistical method involving the selection of elements from an ordered sampling frame. The most common form of systematic sampling is an equiprobability method. This applies in particular when the sampled units are individuals, households or corporations. When a geographic area is sampled for a spatial analysis, bi-dimensional systematic sampling on an area sampling frame can be applied.
SUDAAN is a proprietary statistical software package for the analysis of correlated data, including correlated data encountered in complex sample surveys. SUDAAN originated in 1972 at RTI International. Individual commercial licenses are sold for $1,460 a year, or $3,450 permanently.
Sample size determination or estimation is the act of choosing the number of observations or replicates to include in a statistical sample. The sample size is an important feature of any empirical study in which the goal is to make inferences about a population from a sample. In practice, the sample size used in a study is usually determined based on the cost, time, or convenience of collecting the data, and the need for it to offer sufficient statistical power. In complex studies, different sample sizes may be allocated, such as in stratified surveys or experimental designs with multiple treatment groups. In a census, data is sought for an entire population, hence the intended sample size is equal to the population. In experimental design, where a study may be divided into different treatment groups, there may be different sample sizes for each group.
In statistics, a sampling frame is the source material or device from which a sample is drawn. It is a list of all those within a population who can be sampled, and may include individuals, households or institutions.
This glossary of statistics and probability is a list of definitions of terms and concepts used in the mathematical sciences of statistics and probability, their sub-disciplines, and related fields. For additional related terms, see Glossary of mathematics and Glossary of experimental design.
Bootstrapping is a procedure for estimating the distribution of an estimator by resampling one's data or a model estimated from the data. Bootstrapping assigns measures of accuracy to sample estimates. This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.
Forest inventory is the systematic collection of data and forest information for assessment or analysis. An estimate of the value and possible uses of timber is an important part of the broader information required to sustain ecosystems. When taking forest inventory the following are important things to measure and note: species, diameter at breast height (DBH), height, site quality, age, and defects. From the data collected one can calculate the number of trees per acre, the basal area, the volume of trees in an area, and the value of the timber. Inventories can be done for other reasons than just calculating the value. A forest can be cruised to visually assess timber and determine potential fire hazards and the risk of fire. The results of this type of inventory can be used in preventive actions and also awareness. Wildlife surveys can be undertaken in conjunction with timber inventory to determine the number and type of wildlife within a forest. The aim of the statistical forest inventory is to provide comprehensive information about the state and dynamics of forests for strategic and management planning. Merely looking at the forest for assessment is called taxation.
Balanced repeated replication is a statistical technique for estimating the sampling variability of a statistic obtained by stratified sampling.
Stratification of clinical trials is the partitioning of subjects and results by a factor other than the treatment given.
The Health Information National Trends Survey (HINTS) is a cross-sectional, nationally representative survey of American adults sponsored by the National Cancer Institute. HINTS provides publicly available data on American adults' knowledge of, attitudes toward, and behaviors related to cancer prevention, control and communication. Researchers use the data to identify trends in health communication, including how people find cancer information, which sources they use, their feelings about the search process, and how they perceive cancer overall.
In statistics, a simple random sample is a subset of individuals chosen from a larger set in which a subset of individuals are chosen randomly, all with the same probability. It is a process of selecting a sample in a random way. In SRS, each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals. Simple random sampling is a basic type of sampling and can be a component of other more complex sampling methods.
In survey research, the design effect is a number that shows how well a sample of people may represent a larger group of people for a specific measure of interest. This is important when the sample comes from a sampling method that is different than just picking people using a simple random sample.
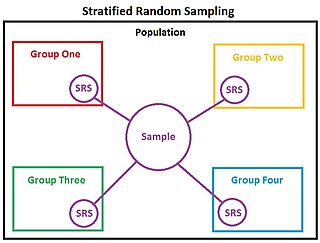
In statistics, stratified randomization is a method of sampling which first stratifies the whole study population into subgroups with same attributes or characteristics, known as strata, then followed by simple random sampling from the stratified groups, where each element within the same subgroup are selected unbiasedly during any stage of the sampling process, randomly and entirely by chance. Stratified randomization is considered a subdivision of stratified sampling, and should be adopted when shared attributes exist partially and vary widely between subgroups of the investigated population, so that they require special considerations or clear distinctions during sampling. This sampling method should be distinguished from cluster sampling, where a simple random sample of several entire clusters is selected to represent the whole population, or stratified systematic sampling, where a systematic sampling is carried out after the stratification process.
The National Health and Nutritional Survey is a national health examination survey conducted in Japan. Beginning as the National Nutrition Survey (NNS) after World War II, it is the oldest of all such surveys currently conducted in the world as of December 2015. The NHNS is the only health examination and interview survey conducted nationally in Japan to obtain general information on health, nutrition, and physical activity.