Related Research Articles
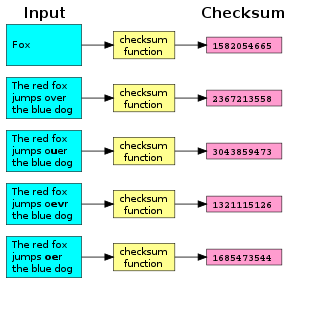
A checksum is a small-sized block of data derived from another block of digital data for the purpose of detecting errors that may have been introduced during its transmission or storage. By themselves, checksums are often used to verify data integrity but are not relied upon to verify data authenticity.

A hash function is any function that can be used to map data of arbitrary size to fixed-size values, though there are some hash functions that support variable-length output. The values returned by a hash function are called hash values, hash codes, hash digests, digests, or simply hashes. The values are usually used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter-storage addressing.
The MD5 message-digest algorithm is a widely used hash function producing a 128-bit hash value. MD5 was designed by Ronald Rivest in 1991 to replace an earlier hash function MD4, and was specified in 1992 as RFC 1321.
The Lempel–Ziv–Markov chain algorithm (LZMA) is an algorithm used to perform lossless data compression. It has been under development since either 1996 or 1998 by Igor Pavlov and was first used in the 7z format of the 7-Zip archiver. This algorithm uses a dictionary compression scheme somewhat similar to the LZ77 algorithm published by Abraham Lempel and Jacob Ziv in 1977 and features a high compression ratio and a variable compression-dictionary size, while still maintaining decompression speed similar to other commonly used compression algorithms.

A cryptographic hash function (CHF) is a hash algorithm that has special properties desirable for a cryptographic application:

In cryptography, a timing attack is a side-channel attack in which the attacker attempts to compromise a cryptosystem by analyzing the time taken to execute cryptographic algorithms. Every logical operation in a computer takes time to execute, and the time can differ based on the input; with precise measurements of the time for each operation, an attacker can work backwards to the input. Finding secrets through timing information may be significantly easier than using cryptanalysis of known plaintext, ciphertext pairs. Sometimes timing information is combined with cryptanalysis to increase the rate of information leakage.
In cryptography, a message authentication code (MAC), sometimes known as an authentication tag, is a short piece of information used for authenticating and integrity-checking a message. In other words, to confirm that the message came from the stated sender and has not been changed. The MAC value allows verifiers to detect any changes to the message content.
File verification is the process of using an algorithm for verifying the integrity of a computer file, usually by checksum. This can be done by comparing two files bit-by-bit, but requires two copies of the same file, and may miss systematic corruptions which might occur to both files. A more popular approach is to generate a hash of the copied file and comparing that to the hash of the original file.

Unix time is a date and time representation widely used in computing. It measures time by the number of non-leap seconds that have elapsed since 00:00:00 UTC on 1 January 1970, the Unix epoch. In modern computing, values are sometimes stored with higher granularity, such as microseconds or nanoseconds.
Fowler–Noll–Vo is a non-cryptographic hash function created by Glenn Fowler, Landon Curt Noll, and Kiem-Phong Vo.
SHA-2 is a set of cryptographic hash functions designed by the United States National Security Agency (NSA) and first published in 2001. They are built using the Merkle–Damgård construction, from a one-way compression function itself built using the Davies–Meyer structure from a specialized block cipher.
In mathematics and computing, universal hashing refers to selecting a hash function at random from a family of hash functions with a certain mathematical property. This guarantees a low number of collisions in expectation, even if the data is chosen by an adversary. Many universal families are known, and their evaluation is often very efficient. Universal hashing has numerous uses in computer science, for example in implementations of hash tables, randomized algorithms, and cryptography.
In cryptography, key stretching techniques are used to make a possibly weak key, typically a password or passphrase, more secure against a brute-force attack by increasing the resources it takes to test each possible key. Passwords or passphrases created by humans are often short or predictable enough to allow password cracking, and key stretching is intended to make such attacks more difficult by complicating a basic step of trying a single password candidate. Key stretching also improves security in some real-world applications where the key length has been constrained, by mimicking a longer key length from the perspective of a brute-force attacker.

In computer science, a fingerprinting algorithm is a procedure that maps an arbitrarily large data item to a much shorter bit string, its fingerprint, that uniquely identifies the original data for all practical purposes just as human fingerprints uniquely identify people for practical purposes. This fingerprint may be used for data deduplication purposes. This is also referred to as file fingerprinting, data fingerprinting, or structured data fingerprinting.

Cryptography, or cryptology, is the practice and study of techniques for secure communication in the presence of adversarial behavior. More generally, cryptography is about constructing and analyzing protocols that prevent third parties or the public from reading private messages. Modern cryptography exists at the intersection of the disciplines of mathematics, computer science, information security, electrical engineering, digital signal processing, physics, and others. Core concepts related to information security are also central to cryptography. Practical applications of cryptography include electronic commerce, chip-based payment cards, digital currencies, computer passwords, and military communications.
bcrypt is a password-hashing function designed by Niels Provos and David Mazières, based on the Blowfish cipher and presented at USENIX in 1999. Besides incorporating a salt to protect against rainbow table attacks, bcrypt is an adaptive function: over time, the iteration count can be increased to make it slower, so it remains resistant to brute-force search attacks even with increasing computation power.
The Jenkins hash functions are a family of non-cryptographic hash functions for multi-byte keys designed by Bob Jenkins. The first one was formally published in 1997.
MurmurHash is a non-cryptographic hash function suitable for general hash-based lookup. It was created by Austin Appleby in 2008 and, as of 8 January 2016, is hosted on GitHub along with its test suite named SMHasher. It also exists in a number of variants, all of which have been released into the public domain. The name comes from two basic operations, multiply (MU) and rotate (R), used in its inner loop.
BLAKE is a cryptographic hash function based on Daniel J. Bernstein's ChaCha stream cipher, but a permuted copy of the input block, XORed with round constants, is added before each ChaCha round. Like SHA-2, there are two variants differing in the word size. ChaCha operates on a 4×4 array of words. BLAKE repeatedly combines an 8-word hash value with 16 message words, truncating the ChaCha result to obtain the next hash value. BLAKE-256 and BLAKE-224 use 32-bit words and produce digest sizes of 256 bits and 224 bits, respectively, while BLAKE-512 and BLAKE-384 use 64-bit words and produce digest sizes of 512 bits and 384 bits, respectively.
crypt is a POSIX C library function. It is typically used to compute the hash of user account passwords. The function outputs a text string which also encodes the salt, and identifies the hash algorithm used. This output string forms a password record, which is usually stored in a text file.
References
- ↑ Binstock, Andrew (1996). "Hashing Rehashed". Dr. Dobb's .
- ↑ "Hash Functions". www.cs.hmc.edu. Retrieved 2015-06-10.
- ↑ CORPORATE UNIX Press (1993). System V application binary interface . ISBN 0-13-100439-5.
- ↑ "ELF hash function may overflow". 12 April 2023. Retrieved 2023-04-14.