Related Research Articles
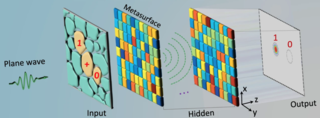
An optical neural network is a physical implementation of an artificial neural network with optical components. Early optical neural networks used a photorefractive Volume hologram to interconnect arrays of input neurons to arrays of output with synaptic weights in proportion to the multiplexed hologram's strength. Volume holograms were further multiplexed using spectral hole burning to add one dimension of wavelength to space to achieve four dimensional interconnects of two dimensional arrays of neural inputs and outputs. This research led to extensive research on alternative methods using the strength of the optical interconnect for implementing neuronal communications.
There are many types of artificial neural networks (ANN).

In machine learning, feature learning or representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
A convolutional neural network (CNN) is a regularized type of feed-forward neural network that learns features by itself via filter optimization. This type of deep learning network has been applied to process and make predictions from many different types of data including text, images and audio. Convolution-based networks are the de-facto standard in deep learning-based approaches to computer vision and image processing, and have only recently have been replaced -- in some cases -- by newer deep learning architectures such as the transformer. Vanishing gradients and exploding gradients, seen during backpropagation in earlier neural networks, are prevented by using regularized weights over fewer connections. For example, for each neuron in the fully-connected layer, 10,000 weights would be required for processing an image sized 100 × 100 pixels. However, applying cascaded convolution kernels, only 25 neurons are required to process 5x5-sized tiles. Higher-layer features are extracted from wider context windows, compared to lower-layer features.
Multimodal learning, in the context of machine learning, is a type of deep learning using multiple modalities of data, such as text, audio, or images.
A vision processing unit (VPU) is an emerging class of microprocessor; it is a specific type of AI accelerator, designed to accelerate machine vision tasks.
In artificial neural networks, a convolutional layer is a type of network layer that applies a convolution operation to the input. Convolutional layers are some of the primary building blocks of convolutional neural networks (CNNs), a class of neural network most commonly applied to images, video, audio, and other data that have the property of uniform translational symmetry.

An event camera, also known as a neuromorphic camera, silicon retina or dynamic vision sensor, is an imaging sensor that responds to local changes in brightness. Event cameras do not capture images using a shutter as conventional (frame) cameras do. Instead, each pixel inside an event camera operates independently and asynchronously, reporting changes in brightness as they occur, and staying silent otherwise.
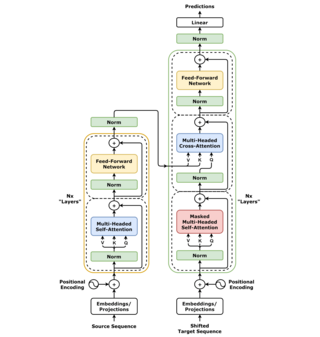
A transformer is a deep learning architecture developed by researchers at Google and based on the multi-head attention mechanism, proposed in the 2017 paper "Attention Is All You Need". Text is converted to numerical representations called tokens, and each token is converted into a vector via lookup from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism, allowing the signal for key tokens to be amplified and less important tokens to be diminished.
Bidirectional encoder representations from transformers (BERT) is a language model introduced in October 2018 by researchers at Google. It learns to represent text as a sequence of vectors using self-supervised learning. It uses the encoder-only transformer architecture. It is notable for its dramatic improvement over previous state-of-the-art models, and as an early example of a large language model. As of 2020, BERT is a ubiquitous baseline in natural language processing (NLP) experiments.

Seq2seq is a family of machine learning approaches used for natural language processing. Applications include language translation, image captioning, conversational models, and text summarization. Seq2seq uses sequence transformation: it turns one sequence into another sequence.
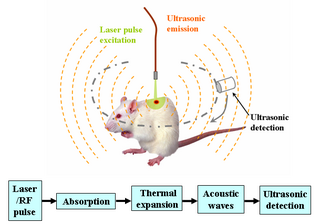
Deep learning in photoacoustic imaging combines the hybrid imaging modality of photoacoustic imaging (PA) with the rapidly evolving field of deep learning. Photoacoustic imaging is based on the photoacoustic effect, in which optical absorption causes a rise in temperature, which causes a subsequent rise in pressure via thermo-elastic expansion. This pressure rise propagates through the tissue and is sensed via ultrasonic transducers. Due to the proportionality between the optical absorption, the rise in temperature, and the rise in pressure, the ultrasound pressure wave signal can be used to quantify the original optical energy deposition within the tissue.

Attention is a machine learning method that determines the relative importance of each component in a sequence relative to the other components in that sequence. In natural language processing, importance is represented by "soft" weights assigned to each word in a sentence. More generally, attention encodes vectors called token embeddings across a fixed-width sequence that can range from tens to millions of tokens in size.

Video super-resolution (VSR) is the process of generating high-resolution video frames from the given low-resolution video frames. Unlike single-image super-resolution (SISR), the main goal is not only to restore more fine details while saving coarse ones, but also to preserve motion consistency.

Contrastive Language-Image Pre-training (CLIP) is a technique for training a pair of neural network models, one for image understanding and one for text understanding, using a contrastive objective. This method has enabled broad applications across multiple domains, including cross-modal retrieval, text-to-image generation, aesthetic ranking, and image captioning.

A vision transformer (ViT) is a transformer designed for computer vision. A ViT decomposes an input image into a series of patches, serializes each patch into a vector, and maps it to a smaller dimension with a single matrix multiplication. These vector embeddings are then processed by a transformer encoder as if they were token embeddings.

Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques. The generative artificial intelligence technology is the premier product of Stability AI and is considered to be a part of the ongoing artificial intelligence boom.

"Attention Is All You Need" is a 2017 landmark research paper in machine learning authored by eight scientists working at Google. The paper introduced a new deep learning architecture known as the transformer, based on the attention mechanism proposed in 2014 by Bahdanau et al. It is considered a foundational paper in modern artificial intelligence, as the transformer approach has become the main architecture of large language models like those based on GPT. At the time, the focus of the research was on improving Seq2seq techniques for machine translation, but the authors go further in the paper, foreseeing the technique's potential for other tasks like question answering and what is now known as multimodal Generative AI.
The Latent Diffusion Model (LDM) is a diffusion model architecture developed by the CompVis group at LMU Munich.
MobileNet is a family of convolutional neural network (CNN) architectures designed for image classification, object detection, and other computer vision tasks. They are designed for small size, low latency, and low power consumption, making them suitable for on-device inference and edge computing on resource-constrained devices like mobile phones and embedded systems. They were originally designed to be run efficiently on mobile devices with TensorFlow Lite.
References
- 1 2 3 4 5 6 Jaegle, Andrew; Gimeno, Felix; Brock, Andrew; Zisserman, Andrew; Vinyals, Oriol; Carreira, Joao (2021-06-22). "Perceiver: General Perception with Iterative Attention". arXiv: 2103.03206 [cs.CV].
- 1 2 3 Jaegle, Andrew; Borgeaud, Sebastian; Alayrac, Jean-Baptiste; Doersch, Carl; Ionescu, Catalin; Ding, David; Koppula, Skanda; Zoran, Daniel; Brock, Andrew; Shelhamer, Evan; Hénaff, Olivier (2021-08-02). "Perceiver IO: A General Architecture for Structured Inputs & Outputs". arXiv: 2107.14795 [cs.LG].