
A, or a, is the first letter and the first vowel of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is a, plural aes. It is similar in shape to the Ancient Greek letter alpha, from which it derives. The uppercase version consists of the two slanting sides of a triangle, crossed in the middle by a horizontal bar. The lowercase version can be written in two forms: the double-storey a and single-storey ɑ. The latter is commonly used in handwriting and fonts based on it, especially fonts intended to be read by children, and is also found in italic type.
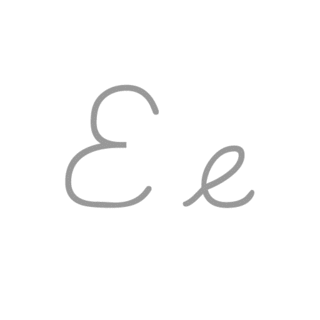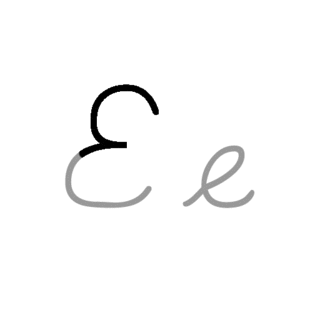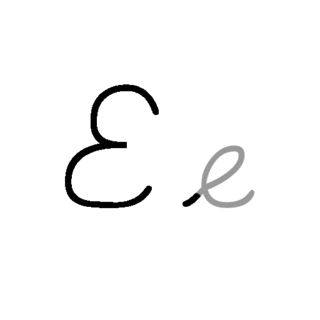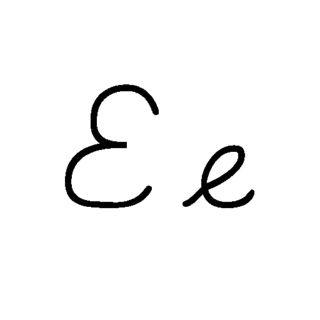
E, or e, is the fifth letter and the second vowel letter in the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is e ; plural ees, Es or E's. It is the most commonly used letter in many languages, including Czech, Danish, Dutch, English, French, German, Hungarian, Latin, Latvian, Norwegian, Spanish, and Swedish.

The International Phonetic Alphabet (IPA) is an alphabetic system of phonetic notation based primarily on the Latin script. It was devised by the International Phonetic Association in the late 19th century as a standardized representation of speech sounds in written form. The IPA is used by lexicographers, foreign language students and teachers, linguists, speech–language pathologists, singers, actors, constructed language creators, and translators.

O, or o, is the fifteenth letter and the fourth vowel letter in the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is o, plural oes.

T, or t, is the twentieth letter in the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is tee, plural tees. It is derived from the Semitic Taw 𐤕 of the Phoenician and Paleo-Hebrew script via the Greek letter τ (tau). In English, it is most commonly used to represent the voiceless alveolar plosive, a sound it also denotes in the International Phonetic Alphabet. It is the most commonly used consonant and the second-most commonly used letter in English-language texts.

U or u, is the twenty-first and sixth-to-last letter and fifth vowel letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is u, plural ues.

Æ is a character formed from the letters a and e, originally a ligature representing the Latin diphthong ae. It has been promoted to the status of a letter in some languages, including Danish, Norwegian, Icelandic, and Faroese. It was also used in Old Swedish before being changed to ä. Today, the International Phonetic Alphabet uses it to represent the near-open front unrounded vowel. Diacritic variants include Ǣ/ǣ, Ǽ/ǽ, Æ̀/æ̀, Æ̂/æ̂ and Æ̃/æ̃.
In digital typography, combining characters are characters that are intended to modify other characters. The most common combining characters in the Latin script are the combining diacritical marks.
Unicode has subscripted and superscripted versions of a number of characters including a full set of Arabic numerals. These characters allow any polynomial, chemical and certain other equations to be represented in plain text without using any form of markup like HTML or TeX.
As of Unicode version 15.0 Cyrillic script is encoded across several blocks:
Unicode has a certain amount of duplication of characters. These are pairs of single Unicode code points that are canonically equivalent. The reason for this are compatibility issues with legacy systems.

Latin epsilon or open E is a letter of the extended Latin alphabet, based on the lowercase of the Greek letter epsilon (ε). It occurs in the orthographies of many Niger–Congo and Nilo-Saharan languages, such as Ewe, Akan, Lingala, Dinka and Maasai, for the vowel or, and is included in the African reference alphabet.

Latin alpha or script a is a letter of the Latin alphabet based on one lowercase form of a, or on the Greek lowercase alpha (α).
Diacritical marks of two dots¨, placed side-by-side over or under a letter, are used in a number of languages for several different purposes. The most familiar to English language speakers are the diaeresis and the umlaut, though there are numerous others. For example, in Albanian, ë represents a schwa. Such dots are also sometimes used for stylistic reasons.

L, or l or ℓ in cursive, is the twelfth letter in the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is el, plural els.
Over a thousand characters from the Latin script are encoded in the Unicode Standard, grouped in several basic and extended Latin blocks. The extended ranges contain mainly precomposed letters plus diacritics that are equivalently encoded with combining diacritics, as well as some ligatures and distinct letters, used for example in the orthographies of various African languages and the Vietnamese alphabet. Latin Extended-C contains additions for Uighur and the Claudian letters. Latin Extended-D comprises characters that are mostly of interest to medievalists. Latin Extended-E mostly comprises characters used for German dialectology (Teuthonista). Latin Extended-F and -G contain characters for phonetic transcription.
Bopomofo, or Mandarin Phonetic Symbols, also named Zhuyin, is a Chinese transliteration system for Mandarin Chinese and other related languages and dialects. More commonly used in Taiwanese Mandarin, it may also be used to transcribe other varieties of Chinese, particularly other varieties of Mandarin Chinese dialects, as well as Taiwanese Hokkien. Consisting of 37 characters and five tone marks, it transcribes all possible sounds in Mandarin.
Tone letters are letters that represent the tones of a language, most commonly in languages with contour tones.
IPA Extensions is a block (U+0250–U+02AF) of the Unicode standard that contains full size letters used in the International Phonetic Alphabet (IPA). Both modern and historical characters are included, as well as former and proposed IPA signs and non-IPA phonetic letters. Additional characters employed for phonetics, like the palatalization sign, are encoded in the blocks Phonetic Extensions (1D00–1D7F) and Phonetic Extensions Supplement (1D80–1DBF). Diacritics are found in the Spacing Modifier Letters (02B0–02FF) and Combining Diacritical Marks (0300–036F) blocks. Its block name in Unicode 1.0 was Standard Phonetic.
