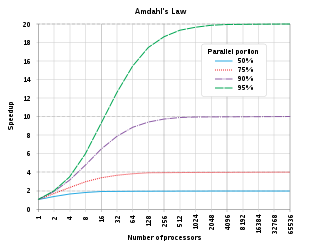
In computer architecture, Amdahl's law is a formula that shows how much faster a task can be completed when you add more resources to the system.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. In many cases, a thread is a component of a process.

A superscalar processor is a CPU that implements a form of parallelism called instruction-level parallelism within a single processor. In contrast to a scalar processor, which can execute at most one single instruction per clock cycle, a superscalar processor can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows more throughput than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor, but an execution resource within a single CPU such as an arithmetic logic unit.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
The Message Passing Interface (MPI) is a portable message-passing standard designed to function on parallel computing architectures. The MPI standard defines the syntax and semantics of library routines that are useful to a wide range of users writing portable message-passing programs in C, C++, and Fortran. There are several open-source MPI implementations, which fostered the development of a parallel software industry, and encouraged development of portable and scalable large-scale parallel applications.
Simultaneous multithreading (SMT) is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better use the resources provided by modern processor architectures.

OpenMP is an application programming interface (API) that supports multi-platform shared-memory multiprocessing programming in C, C++, and Fortran, on many platforms, instruction-set architectures and operating systems, including Solaris, AIX, FreeBSD, HP-UX, Linux, macOS, and Windows. It consists of a set of compiler directives, library routines, and environment variables that influence run-time behavior.
In computing, single program, multiple data (SPMD) is a term that has been used to refer to computational models for exploiting parallelism where-by multiple processors cooperate in the execution of a program in order to obtain results faster.
Automatic parallelization, also auto parallelization, or autoparallelization refers to converting sequential code into multi-threaded and/or vectorized code in order to use multiple processors simultaneously in a shared-memory multiprocessor (SMP) machine. Fully automatic parallelization of sequential programs is a challenge because it requires complex program analysis and the best approach may depend upon parameter values that are not known at compilation time.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.

Binary Modular Dataflow Machine (BMDFM) is a software package that enables running an application in parallel on shared memory symmetric multiprocessing (SMP) computers using the multiple processors to speed up the execution of single applications. BMDFM automatically identifies and exploits parallelism due to the static and mainly dynamic scheduling of the dataflow instruction sequences derived from the formerly sequential program.

A multi-core processor (MCP) is a microprocessor on a single integrated circuit (IC) with two or more separate central processing units (CPUs), called cores to emphasize their multiplicity. Each core reads and executes program instructions, specifically ordinary CPU instructions. However, the MCP can run instructions on separate cores at the same time, increasing overall speed for programs that support multithreading or other parallel computing techniques. Manufacturers typically integrate the cores onto a single IC die, known as a chip multiprocessor (CMP), or onto multiple dies in a single chip package. As of 2024, the microprocessors used in almost all new personal computers are multi-core.

In computer architecture, Gustafson's law gives the speedup in the execution time of a task that theoretically gains from parallel computing, using a hypothetical run of the task on a single-core machine as the baseline. To put it another way, it is the theoretical "slowdown" of an already parallelized task if running on a serial machine. It is named after computer scientist John L. Gustafson and his colleague Edwin H. Barsis, and was presented in the article Reevaluating Amdahl's Law in 1988.

Data parallelism is parallelization across multiple processors in parallel computing environments. It focuses on distributing the data across different nodes, which operate on the data in parallel. It can be applied on regular data structures like arrays and matrices by working on each element in parallel. It contrasts to task parallelism as another form of parallelism.
oneAPI Threading Building Blocks is a C++ template library developed by Intel for parallel programming on multi-core processors. Using TBB, a computation is broken down into tasks that can run in parallel. The library manages and schedules threads to execute these tasks.
Explicit Multi-Threading (XMT) is a computer science paradigm for building and programming parallel computers designed around the parallel random-access machine (PRAM) parallel computational model. A more direct explanation of XMT starts with the rudimentary abstraction that made serial computing simple: that any single instruction available for execution in a serial program executes immediately. A consequence of this abstraction is a step-by-step (inductive) explication of the instruction available next for execution. The rudimentary parallel abstraction behind XMT, dubbed Immediate Concurrent Execution (ICE) in Vishkin (2011), is that indefinitely many instructions available for concurrent execution execute immediately. A consequence of ICE is a step-by-step (inductive) explication of the instructions available next for concurrent execution. Moving beyond the serial von Neumann computer, the aspiration of XMT is that computer science will again be able to augment mathematical induction with a simple one-line computing abstraction.
For several years parallel hardware was only available for distributed computing but recently it is becoming available for the low end computers as well. Hence it has become inevitable for software programmers to start writing parallel applications. It is quite natural for programmers to think sequentially and hence they are less acquainted with writing multi-threaded or parallel processing applications. Parallel programming requires handling various issues such as synchronization and deadlock avoidance. Programmers require added expertise for writing such applications apart from their expertise in the application domain. Hence programmers prefer to write sequential code and most of the popular programming languages support it. This allows them to concentrate more on the application. Therefore, there is a need to convert such sequential applications to parallel applications with the help of automated tools. The need is also non-trivial because large amount of legacy code written over the past few decades needs to be reused and parallelized.
SequenceL is a general purpose functional programming language and auto-parallelizing compiler and tool set, whose primary design objectives are performance on multi-core processor hardware, ease of programming, platform portability/optimization, and code clarity and readability. Its main advantage is that it can be used to write straightforward code that automatically takes full advantage of all the processing power available, without programmers needing to be concerned with identifying parallelisms, specifying vectorization, avoiding race conditions, and other challenges of manual directive-based programming approaches such as OpenMP.
In parallel computing, work stealing is a scheduling strategy for multithreaded computer programs. It solves the problem of executing a dynamically multithreaded computation, one that can "spawn" new threads of execution, on a statically multithreaded computer, with a fixed number of processors. It does so efficiently in terms of execution time, memory usage, and inter-processor communication.
In parallel computing, granularity of a task is a measure of the amount of work which is performed by that task.