The log–linear type of a semi-log graph, defined by a logarithmic scale on the y-axis (vertical), and a linear scale on the x-axis (horizontal). Plotted lines are: y=10(red), y=x(green), y=log(x)(blue).The linear–log type of a semi-log graph, defined by a logarithmic scale on the x axis, and a linear scale on the y axis. Plotted lines are: y=10(red), y=x (green), y=log(x)(blue).
All equations of the form form straight lines when plotted semi-logarithmically, since taking logs of both sides gives
This is a line with slope and vertical intercept. The logarithmic scale is usually labeled in base 10; occasionally in base 2:
A log–linear (sometimes log–lin) plot has the logarithmic scale on the y-axis, and a linear scale on the x-axis; a linear–log (sometimes lin–log) is the opposite. The naming is output–input (y–x), the opposite order from (x, y).
On a semi-log plot the spacing of the scale on the y-axis (or x-axis) is proportional to the logarithm of the number, not the number itself. It is equivalent to converting the y values (or x values) to their log, and plotting the data on linear scales. A log–log plot uses the logarithmic scale for both axes, and hence is not a semi-log plot.
Equations
The equation of a line on a linear–log plot, where the abscissa axis is scaled logarithmically (with a logarithmic base of n), would be
The equation for a line on a log–linear plot, with an ordinate axis logarithmically scaled (with a logarithmic base of n), would be:
Finding the function from the semi–log plot
Linear–log plot
On a linear–log plot, pick some fixed point (x0, F0), where F0 is shorthand for F(x0), somewhere on the straight line in the above graph, and further some other arbitrary point (x1, F1) on the same graph. The slope formula of the plot is:
which leads to
or
which means that
In other words, F is proportional to the logarithm of x times the slope of the straight line of its lin–log graph, plus a constant. Specifically, a straight line on a lin–log plot containing points (F0,x0) and (F1,x1) will have the function:
log–linear plot
On a log–linear plot (logarithmic scale on the y-axis), pick some fixed point (x0, F0), where F0 is shorthand for F(x0), somewhere on the straight line in the above graph, and further some other arbitrary point (x1, F1) on the same graph. The slope formula of the plot is:
which leads to
Notice that nlogn(F1) = F1. Therefore, the logs can be inverted to find:
or
This can be generalized for any point, instead of just F1:
Real-world examples
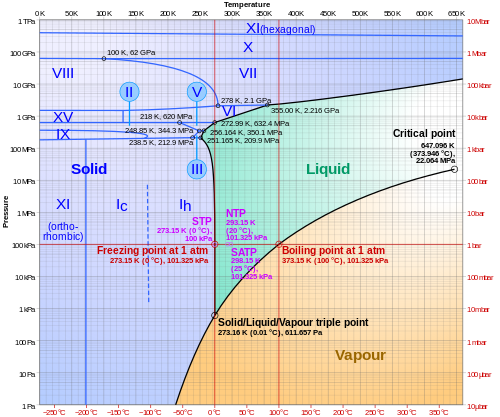
Phase diagram of water
In physics and chemistry, a plot of logarithm of pressure against temperature can be used to illustrate the various phases of a substance, as in the following for water:
Notice that while the horizontal (time) axis is linear, with the dates evenly spaced, the vertical (cases) axis is logarithmic, with the evenly spaced divisions being labelled with successive powers of two. The semi-log plot makes it easier to see when the infection has stopped spreading at its maximum rate, i.e. the straight line on this exponential plot, and starts to curve to indicate a slower rate. This might indicate that some form of mitigation action is working, e.g. social distancing.
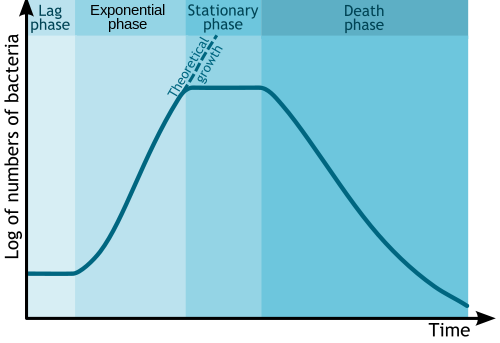
Microbial growth
In biology and biological engineering, the change in numbers of microbes due to asexual reproduction and nutrient exhaustion is commonly illustrated by a semi-log plot. Time is usually the independent axis, with the logarithm of the number or mass of bacteria or other microbe as the dependent variable. This forms a plot with four distinct phases, as shown below.
Bacterial growth curve
See also
Nomogram, a diagram designed to approximate a function graphically
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.