First-order logic—also known as predicate logic, quantificational logic, and first-order predicate calculus—is a collection of formal systems used in mathematics, philosophy, linguistics, and computer science. First-order logic uses quantified variables over non-logical objects and allows the use of sentences that contain variables, so that rather than propositions such as Socrates is a man one can have expressions in the form "there exists x such that x is Socrates and x is a man" and there exists is a quantifier while x is a variable. This distinguishes it from propositional logic, which does not use quantifiers or relations; in this sense, propositional logic is the foundation of first-order logic.
The relational model (RM) for database management is an approach to managing data using a structure and language consistent with first-order predicate logic, first described in 1969 by English computer scientist Edgar F. Codd, where all data is represented in terms of tuples, grouped into relations. A database organized in terms of the relational model is a relational database.
In software engineering and computer science, abstraction is:
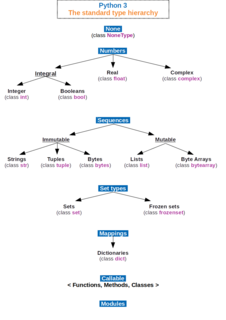
In computer science and computer programming, a data type or simply type is an attribute of data which tells the compiler or interpreter how the programmer intends to use the data. Most programming languages support basic data types of integer numbers, Floating-point numbers, characters and booleans. A data type constrains the values that an expression, such as a variable or a function, might take. This data type defines the operations that can be done on the data, the meaning of the data, and the way values of that type can be stored. A data type provides a set of values from which an expression may take its values.
In logic and mathematics, a truth value, sometimes called a logical value, is a value indicating the relation of a proposition to truth.
ABAP is a high-level programming language created by the German software company SAP SE. It is extracted from the base computing languages Java, C, C++ and Python. It is currently positioned, alongside Java, as the language for programming the SAP NetWeaver Application Server, which is part of the SAP NetWeaver platform for building business applications.
In computer science, data that has several parts, known as a record, can be divided into fields. Relational databases arrange data as sets of database records,so called rows. Each record consists of several fields; the fields of all records form the columns. Examples of fields: name, gender, hair colour.

A dichotomy is a partition of a whole into two parts (subsets). In other words, this couple of parts must be
In computer science, a record is a basic data structure. Records in a database or spreadsheet are usually called "rows".
The High Level Architecture (HLA) is a standard for distributed simulation, used when building a simulation for a larger purpose by combining (federating) several simulations. The standard was developed in the 90’s under the leadership of the US Department of Defense and was later transitioned to become an open international IEEE standard. It is a recommended standard within NATO through STANAG 4603. Today the HLA is used in a number of domains including defense and security and civilian applications.
Granular computing (GrC) is an emerging computing paradigm of information processing that concerns the processing of complex information entities called "information granules", which arise in the process of data abstraction and derivation of knowledge from information or data. Generally speaking, information granules are collections of entities that usually originate at the numeric level and are arranged together due to their similarity, functional or physical adjacency, indistinguishability, coherency, or the like.
In the analysis of multivariate observations designed to assess subjects with respect to an attribute, a Guttman Scale is a single (unidimensional) ordinal scale for the assessment of the attribute, from which the original observations may be reproduced. The discovery of a Guttman Scale in data depends on their multivariate distribution's conforming to a particular structure. Hence, a Guttman Scale is a hypothesis about the structure of the data, formulated with respect to a specified attribute and a specified population and cannot be constructed for any given set of observations. Contrary to a widespread belief, a Guttman Scale is not limited to dichotomous variables and does not necessarily determine an order among the variables. But if variables are all dichotomous, the variables are indeed ordered by their sensitivity in recording the assessed attribute, as illustrated by Example 1.
Binary data is data whose unit can take on only two possible states, traditionally labeled as 0 and 1 in accordance with the binary numeral system and Boolean algebra.
This glossary of Unified Modeling Language terms covers all versions of UML. Individual entries will point out any distinctions that exist between versions.
Entity–attribute–value model (EAV) is a data model to encode, in a space-efficient manner, entities where the number of attributes that can be used to describe them is potentially vast, but the number that will actually apply to a given entity is relatively modest. Such entities correspond to the mathematical notion of a sparse matrix.

EXPRESS is a standard data modeling language for product data. EXPRESS is formalized in the ISO Standard for the Exchange of Product model STEP, and standardized as ISO 10303-11.

Core architecture data model (CADM) in enterprise architecture is a logical data model of information used to describe and build architectures.
InfinityDB is an all-Java embedded database engine and client/server DBMS with an extended java.util.concurrent.ConcurrentNavigableMap interface that is deployed in handheld devices, on servers, on workstations, and in distributed settings. The design is based on a proprietary lockless, concurrent, B-tree architecture that enables client programmers to reach high levels of performance without risk of failures.
A characteristic-based product configurator is a product configurator extension which uses a set of discrete variables, called characteristics, to define all possible product variations.
The Mivar-based approach is a mathematical tool for designing artificial intelligence (AI) systems. Mivar was developed by combining production and Petri nets. The Mivar-based approach was developed for semantic analysis and adequate representation of humanitarian epistemological and axiological principles in the process of developing artificial intelligence. The Mivar-based approach incorporates computer science, informatics and discrete mathematics, databases, expert systems, graph theory, matrices and inference systems. The Mivar-based approach involves two technologies: