In mathematics, the harmonic mean is one of several kinds of average, and in particular, one of the Pythagorean means. It is sometimes appropriate for situations when the average rate is desired.

In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range.

In probability theory and statistics, variance is the expectation of the squared deviation of a random variable from its population mean or sample mean. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. Variance has a central role in statistics, where some ideas that use it include descriptive statistics, statistical inference, hypothesis testing, goodness of fit, and Monte Carlo sampling. Variance is an important tool in the sciences, where statistical analysis of data is common. The variance is the square of the standard deviation, the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .
In probability theory, the central limit theorem (CLT) establishes that, in many situations, for identically distributed independent samples, the standardized sample mean tends towards the standard normal distribution even if the original variables themselves are not normally distributed.
In statistics, the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero. The errors do not need to be normal, nor do they need to be independent and identically distributed. The requirement that the estimator be unbiased cannot be dropped, since biased estimators exist with lower variance. See, for example, the James–Stein estimator, ridge regression, or simply any degenerate estimator.

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-square distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
- With a shape parameter and a scale parameter .
- With a shape parameter and an inverse scale parameter , called a rate parameter.
In probability theory, a compound Poisson distribution is the probability distribution of the sum of a number of independent identically-distributed random variables, where the number of terms to be added is itself a Poisson-distributed variable. The result can be either a continuous or a discrete distribution.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.

In statistics, simple linear regression is a linear regression model with a single explanatory variable. That is, it concerns two-dimensional sample points with one independent variable and one dependent variable and finds a linear function that, as accurately as possible, predicts the dependent variable values as a function of the independent variable. The adjective simple refers to the fact that the outcome variable is related to a single predictor.
In statistics, the delta method is a result concerning the approximate probability distribution for a function of an asymptotically normal statistical estimator from knowledge of the limiting variance of that estimator.
In probability theory and statistics, partial correlation measures the degree of association between two random variables, with the effect of a set of controlling random variables removed. When determining the numerical relationship between two variables of interest, using their correlation coefficient will give misleading results if there is another confounding variable that is numerically related to both variables of interest. This misleading information can be avoided by controlling for the confounding variable, which is done by computing the partial correlation coefficient. This is precisely the motivation for including other right-side variables in a multiple regression; but while multiple regression gives unbiased results for the effect size, it does not give a numerical value of a measure of the strength of the relationship between the two variables of interest.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.

In probability and statistics, the truncated normal distribution is the probability distribution derived from that of a normally distributed random variable by bounding the random variable from either below or above. The truncated normal distribution has wide applications in statistics and econometrics.
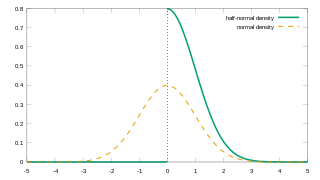
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
Experimental uncertainty analysis is a technique that analyses a derived quantity, based on the uncertainties in the experimentally measured quantities that are used in some form of mathematical relationship ("model") to calculate that derived quantity. The model used to convert the measurements into the derived quantity is usually based on fundamental principles of a science or engineering discipline.
The purpose of this page is to provide supplementary materials for the ordinary least squares article, reducing the load of the main article with mathematics and improving its accessibility, while at the same time retaining the completeness of exposition.

In statistics, errors-in-variables models or measurement error models are regression models that account for measurement errors in the independent variables. In contrast, standard regression models assume that those regressors have been measured exactly, or observed without error; as such, those models account only for errors in the dependent variables, or responses.
In statistics, the variance function is a smooth function which depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.
The generalized functional linear model (GFLM) is an extension of the generalized linear model (GLM) that allows one to regress univariate responses of various types on functional predictors, which are mostly random trajectories generated by a square-integrable stochastic processes. Similarly to GLM, a link function relates the expected value of the response variable to a linear predictor, which in case of GFLM is obtained by forming the scalar product of the random predictor function with a smooth parameter function . Functional Linear Regression, Functional Poisson Regression and Functional Binomial Regression, with the important Functional Logistic Regression included, are special cases of GFLM. Applications of GFLM include classification and discrimination of stochastic processes and functional data.

























