Dimensionality reduction, or dimension reduction, is the transformation of data from a high-dimensional space into a low-dimensional space so that the low-dimensional representation retains some meaningful properties of the original data, ideally close to its intrinsic dimension. Working in high-dimensional spaces can be undesirable for many reasons; raw data are often sparse as a consequence of the curse of dimensionality, and analyzing the data is usually computationally intractable. Dimensionality reduction is common in fields that deal with large numbers of observations and/or large numbers of variables, such as signal processing, speech recognition, neuroinformatics, and bioinformatics.
Automatic summarization is the process of shortening a set of data computationally, to create a subset that represents the most important or relevant information within the original content. Artificial intelligence algorithms are commonly developed and employed to achieve this, specialized for different types of data.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.

Content-based image retrieval, also known as query by image content (QBIC) and content-based visual information retrieval (CBVIR), is the application of computer vision techniques to the image retrieval problem, that is, the problem of searching for digital images in large databases. Content-based image retrieval is opposed to traditional concept-based approaches.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.
In statistics, the k-nearest neighbors algorithm (k-NN) is a non-parametric supervised learning method first developed by Evelyn Fix and Joseph Hodges in 1951, and later expanded by Thomas Cover. It is used for classification and regression. In both cases, the input consists of the k closest training examples in a data set. The output depends on whether k-NN is used for classification or regression:
Nearest neighbor search (NNS), as a form of proximity search, is the optimization problem of finding the point in a given set that is closest to a given point. Closeness is typically expressed in terms of a dissimilarity function: the less similar the objects, the larger the function values.
In computer science, locality-sensitive hashing (LSH) is an algorithmic technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
In mathematics, a graph partition is the reduction of a graph to a smaller graph by partitioning its set of nodes into mutually exclusive groups. Edges of the original graph that cross between the groups will produce edges in the partitioned graph. If the number of resulting edges is small compared to the original graph, then the partitioned graph may be better suited for analysis and problem-solving than the original. Finding a partition that simplifies graph analysis is a hard problem, but one that has applications to scientific computing, VLSI circuit design, and task scheduling in multiprocessor computers, among others. Recently, the graph partition problem has gained importance due to its application for clustering and detection of cliques in social, pathological and biological networks. For a survey on recent trends in computational methods and applications see Buluc et al. (2013). Two common examples of graph partitioning are minimum cut and maximum cut problems.
Similarity search is the most general term used for a range of mechanisms which share the principle of searching spaces of objects where the only available comparator is the similarity between any pair of objects. This is becoming increasingly important in an age of large information repositories where the objects contained do not possess any natural order, for example large collections of images, sounds and other sophisticated digital objects.
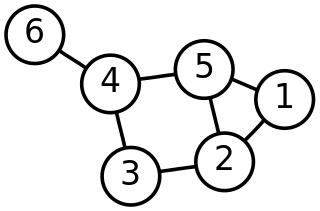
In multivariate statistics, spectral clustering techniques make use of the spectrum (eigenvalues) of the similarity matrix of the data to perform dimensionality reduction before clustering in fewer dimensions. The similarity matrix is provided as an input and consists of a quantitative assessment of the relative similarity of each pair of points in the dataset.
In computer vision, the bag-of-words model sometimes called bag-of-visual-words model can be applied to image classification or retrieval, by treating image features as words. In document classification, a bag of words is a sparse vector of occurrence counts of words; that is, a sparse histogram over the vocabulary. In computer vision, a bag of visual words is a vector of occurrence counts of a vocabulary of local image features.
The image segmentation problem is concerned with partitioning an image into multiple regions according to some homogeneity criterion. This article is primarily concerned with graph theoretic approaches to image segmentation applying graph partitioning via minimum cut or maximum cut. Segmentation-based object categorization can be viewed as a specific case of spectral clustering applied to image segmentation.
SimRank is a general similarity measure, based on a simple and intuitive graph-theoretic model. SimRank is applicable in any domain with object-to-object relationships, that measures similarity of the structural context in which objects occur, based on their relationships with other objects. Effectively, SimRank is a measure that says "two objects are considered to be similar if they are referenced by similar objects." Although SimRank is widely adopted, it may output unreasonable similarity scores which are influenced by different factors, and can be solved in several ways, such as introducing an evidence weight factor, inserting additional terms that are neglected by SimRank or using PageRank-based alternatives.

PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. It is named after both the term "web page" and co-founder Larry Page. PageRank is a way of measuring the importance of website pages. According to Google:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
Locally Optimal Block Preconditioned Conjugate Gradient (LOBPCG) is a matrix-free method for finding the largest eigenvalues and the corresponding eigenvectors of a symmetric generalized eigenvalue problem
In computer science and data mining, MinHash is a technique for quickly estimating how similar two sets are. The scheme was invented by Andrei Broder (1997), and initially used in the AltaVista search engine to detect duplicate web pages and eliminate them from search results. It has also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words.
Similarity learning is an area of supervised machine learning in artificial intelligence. It is closely related to regression and classification, but the goal is to learn a similarity function that measures how similar or related two objects are. It has applications in ranking, in recommendation systems, visual identity tracking, face verification, and speaker verification.
A 3D Content Retrieval system is a computer system for browsing, searching and retrieving three dimensional digital contents from a large database of digital images. The most original way of doing 3D content retrieval uses methods to add description text to 3D content files such as the content file name, link text, and the web page title so that related 3D content can be found through text retrieval. Because of the inefficiency of manually annotating 3D files, researchers have investigated ways to automate the annotation process and provide a unified standard to create text descriptions for 3D contents. Moreover, the increase in 3D content has demanded and inspired more advanced ways to retrieve 3D information. Thus, shape matching methods for 3D content retrieval have become popular. Shape matching retrieval is based on techniques that compare and contrast similarities between 3D models.



