Related Research Articles
Processor design is a subfield of computer engineering and electronics engineering (fabrication) that deals with creating a processor, a key component of computer hardware.

A field-programmable gate array (FPGA) is an integrated circuit designed to be configured by a customer or a designer after manufacturing – hence the term field-programmable. The FPGA configuration is generally specified using a hardware description language (HDL), similar to that used for an application-specific integrated circuit (ASIC). Circuit diagrams were previously used to specify the configuration, but this is increasingly rare due to the advent of electronic design automation tools.
Reconfigurable computing is a computer architecture combining some of the flexibility of software with the high performance of hardware by processing with very flexible high speed computing fabrics like field-programmable gate arrays (FPGAs). The principal difference when compared to using ordinary microprocessors is the ability to make substantial changes to the datapath itself in addition to the control flow. On the other hand, the main difference from custom hardware, i.e. application-specific integrated circuits (ASICs) is the possibility to adapt the hardware during runtime by "loading" a new circuit on the reconfigurable fabric.
Granularity, the condition of existing in granules or grains, refers to the extent to which a material or system is composed of distinguishable pieces. It can either refer to the extent to which a larger entity is subdivided, or the extent to which groups of smaller indistinguishable entities have joined together to become larger distinguishable entities.
ILLIAC was a series of supercomputers built at a variety of locations, some at the University of Illinois at Urbana–Champaign. In all, five computers were built in this series between 1951 and 1974. Some more modern projects also use the name.

In computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.
Nios II is a 32-bit embedded processor architecture designed specifically for the Altera family of field-programmable gate array (FPGA) integrated circuits. Nios II incorporates many enhancements over the original Nios architecture, making it more suitable for a wider range of embedded computing applications, from digital signal processing (DSP) to system-control.
The MicroBlaze is a soft microprocessor core designed for Xilinx field-programmable gate arrays (FPGA). As a soft-core processor, MicroBlaze is implemented entirely in the general-purpose memory and logic fabric of Xilinx FPGAs.

Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.
In computer architecture, a transport triggered architecture (TTA) is a kind of processor design in which programs directly control the internal transport buses of a processor. Computation happens as a side effect of data transports: writing data into a triggering port of a functional unit triggers the functional unit to start a computation. This is similar to what happens in a systolic array. Due to its modular structure, TTA is an ideal processor template for application-specific instruction set processors (ASIP) with customized datapath but without the inflexibility and design cost of fixed function hardware accelerators.
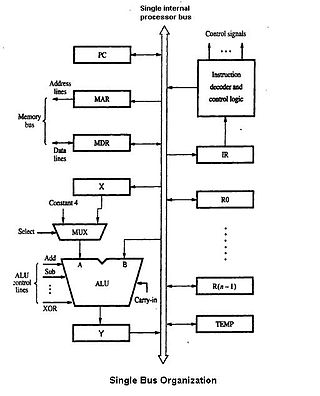
A datapath is a collection of functional units such as arithmetic logic units (ALUs) or multipliers that perform data processing operations, registers, and buses. Along with the control unit it composes the central processing unit (CPU). A larger datapath can be made by joining more than one datapaths using multiplexers.
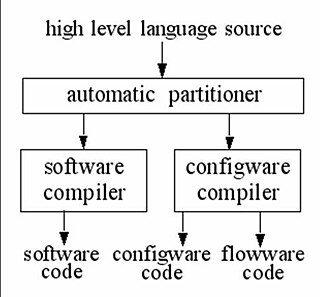
Software/Configware Co-Compilation is used for reconfigurable computing to generate the code for both, an instruction-stream-based microprocessor and a reconfigurable accelerator interfaced to it. Such a co-compiler has a partitioner which accepts input from a high level language source, such as, for instance a programming language, or the output from tools like MATLAB, and automatically partitions it into parallelizable parts suitable for the reconfigurable accelerator and the rest for running on the microprocessor. By loop transformations the partitioner converts the parallelizable parts into a configware source, which is compiled by a Configware Compiler generating configware code for the configuration of the reconfigurable accelerator like, for instance an FPGA, or a coarse-grained reconfigurable array, and flowware code for organizing the data streams going from and to the accelerator.

The history of general-purpose CPUs is a continuation of the earlier history of computing hardware.
LatticeMico32 is a 32-bit microprocessor reduced instruction set computer (RISC) soft core from Lattice Semiconductor optimized for field-programmable gate arrays (FPGAs). It uses a Harvard architecture, which means the instruction and data buses are separate. Bus arbitration logic can be used to combine the two buses, if desired.
This is a glossary of terms used in the field of Reconfigurable computing and reconfigurable computing systems, as opposed to the traditional Von Neumann architecture.
An application-specific instruction set processor (ASIP) is a component used in system on a chip design. The instruction set architecture of an ASIP is tailored to benefit a specific application. This specialization of the core provides a tradeoff between the flexibility of a general purpose central processing unit (CPU) and the performance of an application-specific integrated circuit (ASIC).
Structured ASIC is an intermediate technology between ASIC and FPGA, offering high performance, a characteristic of ASIC, and low NRE cost, a characteristic of FPGA. Using Structured ASIC allows products to be introduced quickly to market, to have lower cost and to be designed with ease.

An array is a systematic arrangement of similar objects, usually in rows and columns.
Computing with Memory refers to computing platforms where function response is stored in memory array, either one or two-dimensional, in the form of lookup tables (LUTs) and functions are evaluated by retrieving the values from the LUTs. These computing platforms can follow either a purely spatial computing model, as in field-programmable gate array (FPGA), or a temporal computing model, where a function is evaluated across multiple clock cycles. The latter approach aims at reducing the overhead of programmable interconnect in FPGA by folding interconnect resources inside a computing element. It uses dense two-dimensional memory arrays to store large multiple-input multiple-output LUTs. Computing with Memory differs from Computing in Memory or processor-in-memory (PIM) concepts, widely investigated in the context of integrating a processor and memory on the same chip to reduce memory latency and increase bandwidth. These architectures seek to reduce the distance the data travels between the processor and the memory. The Berkeley IRAM project is one notable contribution in the area of PIM architectures.
A field-programmable object array (FPOA) is a class of programmable logic devices designed to be modified or programmed after manufacturing. They are designed to bridge the gap between ASIC and FPGA. They contain a grid of programmable silicon objects. Arrix range of FPOA contained three types of silicon objects: arithmetic logic units (ALUs), register files (RFs) and multiply-and-accumulate units (MACs). Both the objects and interconnects are programmable.
References
- 1 2 Field-Programmable Logic: Architectures, Synthesis and Applications, Reiner W. Hartenstein, Springer Science & Business Media, 24-Aug-1994
- 1 2 3 4 5 6 7 8 Compilation Techniques for Reconfigurable Architectures, Springer Science & Business Media, 02-Apr-2011
- ↑ Designing Embedded Processors: A Low Power Perspective, Springer Science & Business Media, 27-Jul-2007
- ↑ Reconfigurable System Design and Verification, CRC Press, 17-Feb-2009