In computer science, all-pairs testing or pairwise testing is a combinatorial method of software testing that, for each pair of input parameters to a system (typically, a softwarealgorithm), tests all possible discrete combinations of those parameters. Using carefully chosen test vectors, this can be done much faster than an exhaustive search of all combinations of all parameters by "parallelizing" the tests of parameter pairs.[1]
In most cases, a single input parameter or an interaction between two parameters is what causes a program's bugs.[2] Bugs involving interactions between three or more parameters are both progressively less common [3] and also progressively more expensive to find---such testing has as its limit the testing of all possible inputs.[4] Thus, a combinatorial technique for picking test cases like all-pairs testing is a useful cost-benefit compromise that enables a significant reduction in the number of test cases without drastically compromising functional coverage.[5]
More rigorously, if we assume that a test case has parameters given in a set . The range of the parameters are given by . Let's assume that . We note that the number of all possible test cases is a . Imagining that the code deals with the conditions taking only two parameters at a time, might reduce the number of needed test cases.[clarification needed]
To demonstrate, suppose there are X,Y,Z parameters. We can use a predicate of the form of order 3, which takes all 3 as input, or rather three different order 2 predicates of the form . can be written in an equivalent form of where comma denotes any combination. If the code is written as conditions taking "pairs" of parameters, then the set of choices of ranges can be a multiset[clarification needed], because there can be multiple parameters having same number of choices.
is one of the maximum of the multiset The number of pair-wise test cases on this test function would be:-
Therefore, if the and then the number of tests is typically O(nm), where n and m are the number of possibilities for each of the two parameters with the most choices, and it can be quite a lot less than the exhaustive ·
N-wise testing
N-wise testing can be considered the generalized form of pair-wise testing.[citation needed]
The idea is to apply sorting to the set so that gets ordered too. Let the sorted set be a tuple:-
Now we can take the set and call it the pairwise testing. Generalizing further we can take the set and call it the 3-wise testing. Eventually, we can say T-wise testing.
The N-wise testing then would just be, all possible combinations from the above formula.
Example
Consider the parameters shown in the table below.
Parameter name
Value 1
Value 2
Value 3
Value 4
Enabled
True
False
-
-
Choice type
1
2
3
-
Category
a
b
c
d
'Enabled', 'Choice Type' and 'Category' have a choice range of 2, 3 and 4, respectively. An exhaustive test would involve 24 tests (2 x 3 x 4). Multiplying the two largest values (3 and 4) indicates that a pair-wise tests would involve 12 tests. The pairwise test cases, generated by Microsoft's "pict" tool, are shown below.
↑ IEEE 12. Proceedings from the 5th International Conference on Software Testing and Validation (ICST). Software Competence Center Hagenberg. "Test Design: Lessons Learned and Practical Implications. July 18, 2008. pp.1–150. doi:10.1109/IEEESTD.2008.4578383. ISBN978-0-7381-5746-7.{{cite book}}: |journal= ignored (help)
In mathematics, the binomial coefficients are the positive integers that occur as coefficients in the binomial theorem. Commonly, a binomial coefficient is indexed by a pair of integers n ≥ k ≥ 0 and is written It is the coefficient of the xk term in the polynomial expansion of the binomial power (1 + x)n; this coefficient can be computed by the multiplicative formula
In number theory, two integers a and b are coprime, relatively prime or mutually prime if the only positive integer that is a divisor of both of them is 1. Consequently, any prime number that divides a does not divide b, and vice versa. This is equivalent to their greatest common divisor (GCD) being 1. One says also ais prime tob or ais coprime withb.
In mathematics, the Chinese remainder theorem states that if one knows the remainders of the Euclidean division of an integer n by several integers, then one can determine uniquely the remainder of the division of n by the product of these integers, under the condition that the divisors are pairwise coprime.
In theoretical computer science, communication complexity studies the amount of communication required to solve a problem when the input to the problem is distributed among two or more parties. The study of communication complexity was first introduced by Andrew Yao in 1979, while studying the problem of computation distributed among several machines. The problem is usually stated as follows: two parties each receive a -bit string and . The goal is for Alice to compute the value of a certain function, , that depends on both and , with the least amount of communication between them.
In computer science and optimization theory, the max-flow min-cut theorem states that in a flow network, the maximum amount of flow passing from the source to the sink is equal to the total weight of the edges in a minimum cut, i.e., the smallest total weight of the edges which if removed would disconnect the source from the sink.
Additive white Gaussian noise (AWGN) is a basic noise model used in information theory to mimic the effect of many random processes that occur in nature. The modifiers denote specific characteristics:
In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
In probability theory and statistics, the Gumbel distribution is used to model the distribution of the maximum of a number of samples of various distributions.
In signal processing, a finite impulse response (FIR) filter is a filter whose impulse response is of finite duration, because it settles to zero in finite time. This is in contrast to infinite impulse response (IIR) filters, which may have internal feedback and may continue to respond indefinitely.
In probability theory, a pairwise independent collection of random variables is a set of random variables any two of which are independent. Any collection of mutually independent random variables is pairwise independent, but some pairwise independent collections are not mutually independent. Pairwise independent random variables with finite variance are uncorrelated.
In mathematics, a pairing function is a process to uniquely encode two natural numbers into a single natural number.
In combinatorial mathematics, a block design is an incidence structure consisting of a set together with a family of subsets known as blocks, chosen such that frequency of the elements satisfies certain conditions making the collection of blocks exhibit symmetry (balance). Block designs have applications in many areas, including experimental design, finite geometry, physical chemistry, software testing, cryptography, and algebraic geometry.
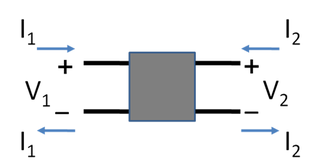
In electronics, a two-port network is an electrical network or device with two pairs of terminals to connect to external circuits. Two terminals constitute a port if the currents applied to them satisfy the essential requirement known as the port condition: the current entering one terminal must equal the current emerging from the other terminal on the same port. The ports constitute interfaces where the network connects to other networks, the points where signals are applied or outputs are taken. In a two-port network, often port 1 is considered the input port and port 2 is considered the output port.
In mathematics, the Schwartz–Zippel lemma is a tool commonly used in probabilistic polynomial identity testing, i.e. in the problem of determining whether a given multivariate polynomial is the 0-polynomial. It was discovered independently by Jack Schwartz, Richard Zippel, and Richard DeMillo and Richard J. Lipton, although DeMillo and Lipton's version was shown a year prior to Schwartz and Zippel's result. The finite field version of this bound was proved by Øystein Ore in 1922.
An attenuator is an electronic device that reduces the power of a signal without appreciably distorting its waveform.
In economics, discrete choice models, or qualitative choice models, describe, explain, and predict choices between two or more discrete alternatives, such as entering or not entering the labor market, or choosing between modes of transport. Such choices contrast with standard consumption models in which the quantity of each good consumed is assumed to be a continuous variable. In the continuous case, calculus methods can be used to determine the optimum amount chosen, and demand can be modeled empirically using regression analysis. On the other hand, discrete choice analysis examines situations in which the potential outcomes are discrete, such that the optimum is not characterized by standard first-order conditions. Thus, instead of examining "how much" as in problems with continuous choice variables, discrete choice analysis examines "which one". However, discrete choice analysis can also be used to examine the chosen quantity when only a few distinct quantities must be chosen from, such as the number of vehicles a household chooses to own and the number of minutes of telecommunications service a customer decides to purchase. Techniques such as logistic regression and probit regression can be used for empirical analysis of discrete choice.
A complex Hadamard matrix is any complex matrix satisfying two conditions:
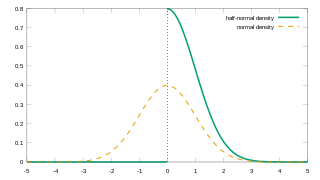
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
Perspective-n-Point is the problem of estimating the pose of a calibrated camera given a set of n 3D points in the world and their corresponding 2D projections in the image. The camera pose consists of 6 degrees-of-freedom (DOF) which are made up of the rotation and 3D translation of the camera with respect to the world. This problem originates from camera calibration and has many applications in computer vision and other areas, including 3D pose estimation, robotics and augmented reality. A commonly used solution to the problem exists for n = 3 called P3P, and many solutions are available for the general case of n ≥ 3. A solution for n = 2 exists if feature orientations are available at the two points. Implementations of these solutions are also available in open source software.
A persistence module is a mathematical structure in persistent homology and topological data analysis that formally captures the persistence of topological features of an object across a range of scale parameters. A persistence module often consists of a collection of homology groups corresponding to a filtration of topological spaces, and a collection of linear maps induced by the inclusions of the filtration. The concept of a persistence module was first introduced in 2005 as an application of graded modules over polynomial rings, thus importing well-developed algebraic ideas from classical commutative algebra theory to the setting of persistent homology. Since then, persistence modules have been one of the primary algebraic structures studied in the field of applied topology.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.