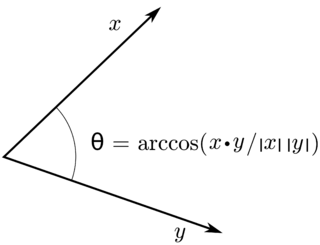
Definition
Suppose a pair  takes values in
takes values in  , where
, where  is the class label of an element whose features are given by
is the class label of an element whose features are given by  . Assume that the conditional distribution of X, given that the label Y takes the value r is given by
. Assume that the conditional distribution of X, given that the label Y takes the value r is given by
 for
for 
where " " means "is distributed as", and where
" means "is distributed as", and where  denotes a probability distribution.
denotes a probability distribution.
A classifier is a rule that assigns to an observation X=x a guess or estimate of what the unobserved label Y=r actually was. In theoretical terms, a classifier is a measurable function  , with the interpretation that C classifies the point x to the class C(x). The probability of misclassification, or risk, of a classifier C is defined as
, with the interpretation that C classifies the point x to the class C(x). The probability of misclassification, or risk, of a classifier C is defined as

The Bayes classifier is

In practice, as in most of statistics, the difficulties and subtleties are associated with modeling the probability distributions effectively—in this case,  . The Bayes classifier is a useful benchmark in statistical classification.
. The Bayes classifier is a useful benchmark in statistical classification.
The excess risk of a general classifier  (possibly depending on some training data) is defined as
(possibly depending on some training data) is defined as  Thus this non-negative quantity is important for assessing the performance of different classification techniques. A classifier is said to be consistent if the excess risk converges to zero as the size of the training data set tends to infinity. [2]
Thus this non-negative quantity is important for assessing the performance of different classification techniques. A classifier is said to be consistent if the excess risk converges to zero as the size of the training data set tends to infinity. [2]
Considering the components  of
of  to be mutually independent, we get the naive bayes classifier, where
to be mutually independent, we get the naive bayes classifier, where 
Properties
Proof that the Bayes classifier is optimal and Bayes error rate is minimal proceeds as follows.
Define the variables: Risk  , Bayes risk
, Bayes risk  , all possible classes to which the points can be classified
, all possible classes to which the points can be classified  . Let the posterior probability of a point belonging to class 1 be
. Let the posterior probability of a point belonging to class 1 be  . Define the classifier
. Define the classifier  as
as

Then we have the following results:
(a)  , i.e.
, i.e.  is a Bayes classifier,
is a Bayes classifier,
(b) For any classifier  , the excess risk satisfies
, the excess risk satisfies 
(c) 
(d) 
Proof of (a): For any classifier , we have

 (due to Fubini's theorem)
(due to Fubini's theorem)

Notice that is minimised by taking  ,
,

Therefore the minimum possible risk is the Bayes risk,  .
.
Proof of (b):

Proof of (c):

Proof of (d):

General case
The general case that the Bayes classifier minimises classification error when each element can belong to either of n categories proceeds by towering expectations as follows.

This is minimised by simultaneously minimizing all the terms of the expectation using the classifier
for each observation x.