In information theory, the cross-entropy between two probability distributions and , over the same underlying set of events, measures the average number of bits needed to identify an event drawn from the set when the coding scheme used for the set is optimized for an estimated probability distribution , rather than the true distribution .
For discrete probability distributions and with the same support, this means
.
(Eq.1)
The situation for continuous distributions is analogous. We have to assume that and are absolutely continuous with respect to some reference measure (usually is a Lebesgue measure on a Borelσ-algebra). Let and be probability density functions of and with respect to . Then
and therefore
.
(Eq.2)
NB: The notation is also used for a different concept, the joint entropy of and .
Motivation
In information theory, the Kraft–McMillan theorem establishes that any directly decodable coding scheme for coding a message to identify one value out of a set of possibilities can be seen as representing an implicit probability distribution over , where is the length of the code for in bits. Therefore, cross-entropy can be interpreted as the expected message-length per datum when a wrong distribution is assumed while the data actually follows a distribution . That is why the expectation is taken over the true probability distribution and not . Indeed the expected message-length under the true distribution is
Estimation
There are many situations where cross-entropy needs to be measured but the distribution of is unknown. An example is language modeling, where a model is created based on a training set , and then its cross-entropy is measured on a test set to assess how accurate the model is in predicting the test data. In this example, is the true distribution of words in any corpus, and is the distribution of words as predicted by the model. Since the true distribution is unknown, cross-entropy cannot be directly calculated. In these cases, an estimate of cross-entropy is calculated using the following formula:
where is the size of the test set, and is the probability of event estimated from the training set. In other words, is the probability estimate of the model that the i-th word of the text is . The sum is averaged over the words of the test. This is a Monte Carlo estimate of the true cross-entropy, where the test set is treated as samples from [citation needed].
Relation to maximum likelihood
The cross entropy arises in classification problems when introducing a logarithm in the guise of the log-likelihood function.
The section is concerned with the subject of estimation of the probability of different possible discrete outcomes. To this end, denote a parametrized family of distributions by , with subject to the optimization effort. Consider a given finite sequence of values from a training set, obtained from conditionally independent sampling. The likelihood assigned to any considered parameter of the model is then given by the product over all probabilities . Repeated occurrences are possible, leading to equal factors in the product. If the count of occurrences of the value equal to (for some index ) is denoted by , then the frequency of that value equals . Denote the latter by , as it may be understood as empirical approximation to the probability distribution underlying the scenario. Further denote by the perplexity, which can be seen to equal by the calculation rules for the logarithm, and where the product is over the values without double counting. So
Cross-entropy minimization is frequently used in optimization and rare-event probability estimation. When comparing a distribution against a fixed reference distribution , cross-entropy and KL divergence are identical up to an additive constant (since is fixed): According to the Gibbs' inequality, both take on their minimal values when , which is for KL divergence, and for cross-entropy. In the engineering literature, the principle of minimizing KL divergence (Kullback's "Principle of Minimum Discrimination Information") is often called the Principle of Minimum Cross-Entropy (MCE), or Minxent.
However, as discussed in the article Kullback–Leibler divergence, sometimes the distribution is the fixed prior reference distribution, and the distribution is optimized to be as close to as possible, subject to some constraint. In this case the two minimizations are not equivalent. This has led to some ambiguity in the literature, with some authors attempting to resolve the inconsistency by restating cross-entropy to be , rather than . In fact, cross-entropy is another name for relative entropy; see Cover and Thomas[1] and Good.[2] On the other hand, does not agree with the literature and can be misleading.
Cross-entropy loss function and logistic regression
Cross-entropy can be used to define a loss function in machine learning and optimization. The true probability is the true label, and the given distribution is the predicted value of the current model. This is also known as the log loss (or logarithmic loss[3] or logistic loss);[4] the terms "log loss" and "cross-entropy loss" are used interchangeably.[5]
More specifically, consider a binary regression model which can be used to classify observations into two possible classes (often simply labelled and ). The output of the model for a given observation, given a vector of input features , can be interpreted as a probability, which serves as the basis for classifying the observation. In logistic regression, the probability is modeled using the logistic function where is some function of the input vector , commonly just a linear function. The probability of the output is given by
where the vector of weights is optimized through some appropriate algorithm such as gradient descent. Similarly, the complementary probability of finding the output is simply given by
Having set up our notation, and , we can use cross-entropy to get a measure of dissimilarity between and :
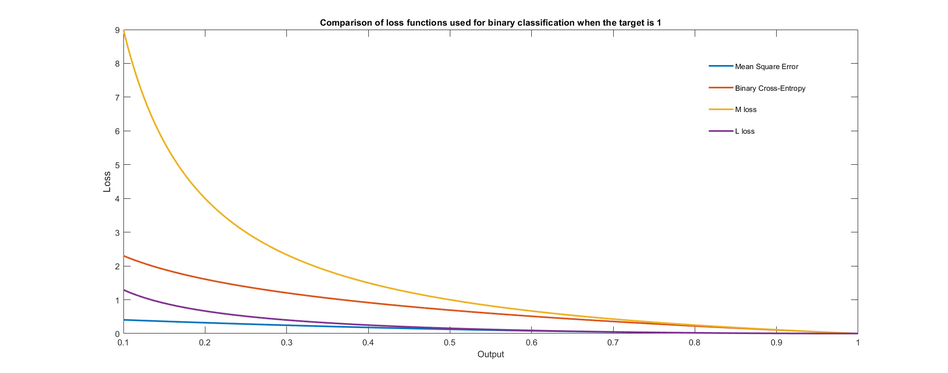
Plot shows different loss functions that can be used to train a binary classifier. Only the case where the target output is 1 is shown. It is observed that the loss is zero when the target is equal to the output and increases as the output becomes increasingly incorrect.
Logistic regression typically optimizes the log loss for all the observations on which it is trained, which is the same as optimizing the average cross-entropy in the sample. Other loss functions that penalize errors differently can be also used for training, resulting in models with different final test accuracy.[6] For example, suppose we have samples with each sample indexed by . The average of the loss function is then given by:
where , with the logistic function as before.
The logistic loss is sometimes called cross-entropy loss. It is also known as log loss.[duplication?] (In this case, the binary label is often denoted by {−1,+1}.[7])
Remark: The gradient of the cross-entropy loss for logistic regression is the same as the gradient of the squared-error loss for linear regression. That is, define
Then we have the result
The proof is as follows. For any , we have
In a similar way, we eventually obtain the desired result.
Amended Cross-Entropy Cost: An Approach for Encouraging Diversity in Classification Ensemble
In some cases one would like to train an ensemble of models that have diversity so when we combine them it would provide best results.[8][9] Assuming we use a simple ensemble of averaging classifiers. Then the Amended Cross-Entropy Cost is
where is the cost function of the classifier, is the probability of the classifier, is the true probability that we need to estimate and is a parameter between 0 and 1 that define the diversity that we would like to establish. When we want each classifier to do its best regardless of the ensemble and when we would like the classifier to be as diverse as possible.
The likelihood function is the joint probability mass of observed data viewed as a function of the parameters of a statistical model. Intuitively, the likelihood function is the probability of observing data assuming is the actual parameter.
In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.
In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
In probability theory and statistics, the gamma distribution is a versatile two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
With a shape parameter k and a scale parameter θ
With a shape parameter and an inverse scale parameter , called a rate parameter.
In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
In physics, a partition function describes the statistical properties of a system in thermodynamic equilibrium. Partition functions are functions of the thermodynamic state variables, such as the temperature and volume. Most of the aggregate thermodynamic variables of the system, such as the total energy, free energy, entropy, and pressure, can be expressed in terms of the partition function or its derivatives. The partition function is dimensionless.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In mathematical statistics, the Kullback–Leibler (KL) divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model instead of P when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods are primarily used for two purposes:
To provide an analytical approximation to the posterior probability of the unobserved variables, in order to do statistical inference over these variables.
To derive a lower bound for the marginal likelihood of the observed data. This is typically used for performing model selection, the general idea being that a higher marginal likelihood for a given model indicates a better fit of the data by that model and hence a greater probability that the model in question was the one that generated the data.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.
In probability theory and statistics, the inverse gamma distribution is a two-parameter family of continuous probability distributions on the positive real line, which is the distribution of the reciprocal of a variable distributed according to the gamma distribution.
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.
In statistics, Poisson regression is a generalized linear model form of regression analysis used to model count data and contingency tables. Poisson regression assumes the response variable Y has a Poisson distribution, and assumes the logarithm of its expected value can be modeled by a linear combination of unknown parameters. A Poisson regression model is sometimes known as a log-linear model, especially when used to model contingency tables.
In directional statistics, the von Mises–Fisher distribution, is a probability distribution on the -sphere in . If the distribution reduces to the von Mises distribution on the circle.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.
The hyperbolastic functions, also known as hyperbolastic growth models, are mathematical functions that are used in medical statistical modeling. These models were originally developed to capture the growth dynamics of multicellular tumor spheres, and were introduced in 2005 by Mohammad Tabatabai, David Williams, and Zoran Bursac. The precision of hyperbolastic functions in modeling real world problems is somewhat due to their flexibility in their point of inflection. These functions can be used in a wide variety of modeling problems such as tumor growth, stem cell proliferation, pharma kinetics, cancer growth, sigmoid activation function in neural networks, and epidemiological disease progression or regression.
In machine learning, diffusion models, also known as diffusion probabilistic models or score-based generative models, are a class of latent variable generative models. A diffusion model consists of three major components: the forward process, the reverse process, and the sampling procedure. The goal of diffusion models is to learn a diffusion process that generates a probability distribution for a given dataset from which we can then sample new images. They learn the latent structure of a dataset by modeling the way in which data points diffuse through their latent space.
References
↑ Thomas M. Cover, Joy A. Thomas, Elements of Information Theory, 2nd Edition, Wiley, p. 80
↑ I. J. Good, Maximum entropy for hypothesis formulation, especially for multidimensional contingency tables, Ann. of Math. Statistics, 1963
↑ The Mathematics of Information Coding, Extraction and Distribution, by George Cybenko, Dianne P. O'Leary, Jorma Rissanen, 1999, p. 82
↑ Probability for Machine Learning: Discover How To Harness Uncertainty With Python, Jason Brownlee, 2019, p. 220: "Logistic loss refers to the loss function commonly used to optimize a logistic regression model. It may also be referred to as logarithmic loss (which is confusing) or simply log loss."
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.