
In molecular biology, a transcription factor (TF) is a protein that controls the rate of transcription of genetic information from DNA to messenger RNA, by binding to a specific DNA sequence. The function of TFs is to regulate—turn on and off—genes in order to make sure that they are expressed in the desired cells at the right time and in the right amount throughout the life of the cell and the organism. Groups of TFs function in a coordinated fashion to direct cell division, cell growth, and cell death throughout life; cell migration and organization during embryonic development; and intermittently in response to signals from outside the cell, such as a hormone. There are 1500-1600 TFs in the human genome. Transcription factors are members of the proteome as well as regulome.
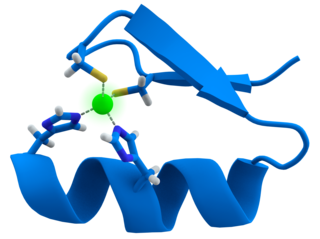
A zinc finger is a small protein structural motif that is characterized by the coordination of one or more zinc ions (Zn2+) which stabilizes the fold. It was originally coined to describe the finger-like appearance of a hypothesized structure from the African clawed frog (Xenopus laevis) transcription factor IIIA. However, it has been found to encompass a wide variety of differing protein structures in eukaryotic cells. Xenopus laevis TFIIIA was originally demonstrated to contain zinc and require the metal for function in 1983, the first such reported zinc requirement for a gene regulatory protein followed soon thereafter by the Krüppel factor in Drosophila. It often appears as a metal-binding domain in multi-domain proteins.
In a chain-like biological molecule, such as a protein or nucleic acid, a structural motif is a common three-dimensional structure that appears in a variety of different, evolutionarily unrelated molecules. A structural motif does not have to be associated with a sequence motif; it can be represented by different and completely unrelated sequences in different proteins or RNA.

DNA-binding proteins are proteins that have DNA-binding domains and thus have a specific or general affinity for single- or double-stranded DNA. Sequence-specific DNA-binding proteins generally interact with the major groove of B-DNA, because it exposes more functional groups that identify a base pair.

Helix-turn-helix is a DNA-binding protein (DBP). The helix-turn-helix (HTH) is a major structural motif capable of binding DNA. Each monomer incorporates two α helices, joined by a short strand of amino acids, that bind to the major groove of DNA. The HTH motif occurs in many proteins that regulate gene expression. It should not be confused with the helix–loop–helix motif.

A leucine zipper is a common three-dimensional structural motif in proteins. They were first described by Landschulz and collaborators in 1988 when they found that an enhancer binding protein had a very characteristic 30-amino acid segment and the display of these amino acid sequences on an idealized alpha helix revealed a periodic repetition of leucine residues at every seventh position over a distance covering eight helical turns. The polypeptide segments containing these periodic arrays of leucine residues were proposed to exist in an alpha-helical conformation and the leucine side chains from one alpha helix interdigitate with those from the alpha helix of a second polypeptide, facilitating dimerization.
Therapeutic gene modulation refers to the practice of altering the expression of a gene at one of various stages, with a view to alleviate some form of ailment. It differs from gene therapy in that gene modulation seeks to alter the expression of an endogenous gene whereas gene therapy concerns the introduction of a gene whose product aids the recipient directly.
Artificial transcription factors (ATFs) are engineered individual or multi molecule transcription factors that either activate or repress gene transcription (biology).

The restriction endonuclease Fok1, naturally found in Flavobacterium okeanokoites, is a bacterial type IIS restriction endonuclease consisting of an N-terminal DNA-binding domain and a non sequence-specific DNA cleavage domain at the C-terminal. Once the protein is bound to duplex DNA via its DNA-binding domain at the 5'-GGATG-3' recognition site, the DNA cleavage domain is activated and cleaves the DNA at two locations, regardless of the nucleotide sequence at the cut site. The DNA is cut 9 nucleotides downstream of the motif on the forward strand, and 13 nucleotides downstream of the motif on the reverse strand, producing two sticky ends with 4-bp overhangs.
Zinc finger protein chimera are chimeric proteins composed of a DNA-binding zinc finger protein domain and another domain through which the protein exerts its effect. The effector domain may be a transcriptional activator (A) or repressor (R), a methylation domain (M) or a nuclease (N).
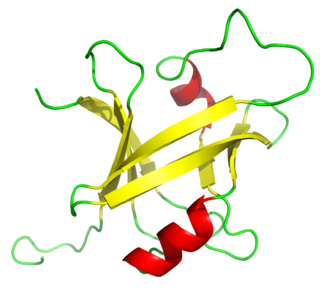
The B3 DNA binding domain (DBD) is a highly conserved domain found exclusively in transcription factors combined with other domains. It consists of 100-120 residues, includes seven beta strands and two alpha helices that form a DNA-binding pseudobarrel protein fold ; it interacts with the major groove of DNA.

Pho4 is a protein with a basic helix-loop-helix (bHLH) transcription factor. It is found in S. cerevisiae and other yeasts. It functions as a transcription factor to regulate phosphate responsive genes located in yeast cells. The Pho4 protein homodimer is able to do this by binding to DNA sequences containing the bHLH binding site 5'-CACGTG-3'. This sequence is found in the promoters of genes up-regulated in response to phosphate availability such as the PHO5 gene.
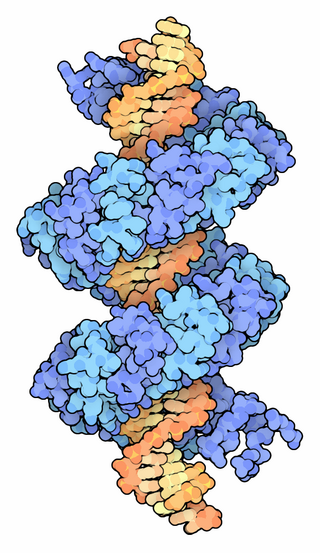
TALeffectors are proteins secreted by some β- and γ-proteobacteria. Most of these are Xanthomonads. Plant pathogenic Xanthomonas bacteria are especially known for TALEs, produced via their type III secretion system. These proteins can bind promoter sequences in the host plant and activate the expression of plant genes that aid bacterial infection. The TALE domain responsible for binding to DNA is known to have 1.5 to 33.5 short sequences that are repeated multiple times. Each of these repeats was found to be specific for a certain base pair of the DNA. These repeats also have repeat variable residues (RVD) that can detect specific DNA base pairs. They recognize plant DNA sequences through a central repeat domain consisting of a variable number of ~34 amino acid repeats. There appears to be a one-to-one correspondence between the identity of two critical amino acids in each repeat and each DNA base in the target sequence. These proteins are interesting to researchers both for their role in disease of important crop species and the relative ease of retargeting them to bind new DNA sequences. Similar proteins can be found in the pathogenic bacterium Ralstonia solanacearum and Burkholderia rhizoxinica, as well as yet unidentified marine microorganisms. The term TALE-likes is used to refer to the putative protein family encompassing the TALEs and these related proteins.

Transcription activator-like effector nucleases (TALEN) are restriction enzymes that can be engineered to cut specific sequences of DNA. They are made by fusing a TAL effector DNA-binding domain to a DNA cleavage domain. Transcription activator-like effectors (TALEs) can be engineered to bind to practically any desired DNA sequence, so when combined with a nuclease, DNA can be cut at specific locations. The restriction enzymes can be introduced into cells, for use in gene editing or for genome editing in situ, a technique known as genome editing with engineered nucleases. Alongside zinc finger nucleases and CRISPR/Cas9, TALEN is a prominent tool in the field of genome editing.
The RNA-binding Proteins Database (RBPDB) is a biological database of RNA-binding protein specificities that includes experimental observations of RNA-binding sites. The experimental results included are both in vitro and in vivo from primary literature. It includes four metazoan species, which are Homo sapiens, Mus musculus, Drosophila melanogaster, and Caenorhabditis elegans. RNA-binding domains included in this database are RNA recognition motif, K homology, CCCH zinc finger, and more domains. As of 2021, the latest RBPDB release includes 1,171 RNA-binding proteins.

Genome editing, or genome engineering, or gene editing, is a type of genetic engineering in which DNA is inserted, deleted, modified or replaced in the genome of a living organism. Unlike early genetic engineering techniques that randomly inserts genetic material into a host genome, genome editing targets the insertions to site-specific locations. The basic mechanism involved in genetic manipulations through programmable nucleases is the recognition of target genomic loci and binding of effector DNA-binding domain (DBD), double-strand breaks (DSBs) in target DNA by the restriction endonucleases, and the repair of DSBs through homology-directed recombination (HDR) or non-homologous end joining (NHEJ).

The WRKY domain is found in the WRKY transcription factor family, a class of transcription factors. The WRKY domain is found almost exclusively in plants although WRKY genes appear present in some diplomonads, social amoebae and other amoebozoa, and fungi incertae sedis. They appear absent in other non-plant species. WRKY transcription factors have been a significant area of plant research for the past 20 years. The WRKY DNA-binding domain recognizes the W-box (T)TGAC(C/T) cis-regulatory element.

Cas9 is a 160 kilodalton protein which plays a vital role in the immunological defense of certain bacteria against DNA viruses and plasmids, and is heavily utilized in genetic engineering applications. Its main function is to cut DNA and thereby alter a cell's genome. The CRISPR-Cas9 genome editing technique was a significant contributor to the Nobel Prize in Chemistry in 2020 being awarded to Emmanuelle Charpentier and Jennifer Doudna.
Transcription Activator-Like Effector-Likes (TALE-likes) are a group of bacterial DNA binding proteins named for the first and still best-studied group, the TALEs of Xanthomonas bacteria. TALEs are important factors in the plant diseases caused by Xanthomonas bacteria, but are known primarily for their role in biotechnology as programmable DNA binding proteins, particularly in the context of TALE nucleases. TALE-likes have additionally been found in many strains of the Ralstonia solanacearum bacterial species complex, in Paraburkholderia rhizoxinica strain HKI 454, and in two unknown marine bacteria. Whether or not all these proteins form a single phylogenetic grouping is as yet unclear.

PBX/Knotted 1 Homeobox 2 (PKNOX2) protein belongs to the three amino acid loop extension (TALE) class of homeodomain proteins, and is encoded by PKNOX2 gene in humans. The protein regulates the transcription of other genes and affects anatomical development.


