In software engineering, code coverage is a percentage measure of the degree to which the source code of a program is executed when a particular test suite is run. A program with high test coverage has more of its source code executed during testing, which suggests it has a lower chance of containing undetected software bugs compared to a program with low test coverage. Many different metrics can be used to calculate test coverage. Some of the most basic are the percentage of program subroutines and the percentage of program statements called during execution of the test suite.

In computer science, a tree is a widely used abstract data type that represents a hierarchical tree structure with a set of connected nodes. Each node in the tree can be connected to many children, but must be connected to exactly one parent, except for the root node, which has no parent. These constraints mean there are no cycles or "loops", and also that each child can be treated like the root node of its own subtree, making recursion a useful technique for tree traversal. In contrast to linear data structures, many trees cannot be represented by relationships between neighboring nodes in a single straight line.

In computer science, a control-flow graph (CFG) is a representation, using graph notation, of all paths that might be traversed through a program during its execution. The control-flow graph was discovered by Frances E. Allen, who noted that Reese T. Prosser used boolean connectivity matrices for flow analysis before.

Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node and explores as far as possible along each branch before backtracking. Extra memory, usually a stack, is needed to keep track of the nodes discovered so far along a specified branch which helps in backtracking of the graph.

A scene graph is a general data structure commonly used by vector-based graphics editing applications and modern computer games, which arranges the logical and often spatial representation of a graphical scene. It is a collection of nodes in a graph or tree structure. A tree node may have many children but only a single parent, with the effect of a parent applied to all its child nodes; an operation performed on a group automatically propagates its effect to all of its members. In many programs, associating a geometrical transformation matrix at each group level and concatenating such matrices together is an efficient and natural way to process such operations. A common feature, for instance, is the ability to group related shapes and objects into a compound object that can then be manipulated as easily as a single object.
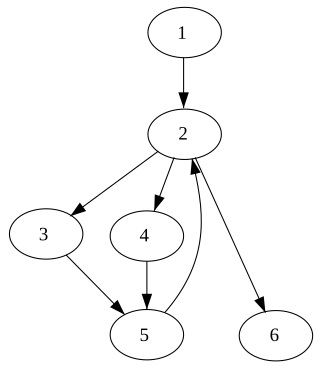
In computer science, a node d of a control-flow graph dominates a node n if every path from the entry node to n must go through d. Notationally, this is written as d dom n. By definition, every node dominates itself.

A flowchart is a type of diagram that represents a workflow or process. A flowchart can also be defined as a diagrammatic representation of an algorithm, a step-by-step approach to solving a task.
In computer science, a binary decision diagram (BDD) or branching program is a data structure that is used to represent a Boolean function. On a more abstract level, BDDs can be considered as a compressed representation of sets or relations. Unlike other compressed representations, operations are performed directly on the compressed representation, i.e. without decompression.
White-box testing is a method of software testing that tests internal structures or workings of an application, as opposed to its functionality. In white-box testing, an internal perspective of the system is used to design test cases. The tester chooses inputs to exercise paths through the code and determine the expected outputs. This is analogous to testing nodes in a circuit, e.g. in-circuit testing (ICT). White-box testing can be applied at the unit, integration and system levels of the software testing process. Although traditional testers tended to think of white-box testing as being done at the unit level, it is used for integration and system testing more frequently today. It can test paths within a unit, paths between units during integration, and between subsystems during a system–level test. Though this method of test design can uncover many errors or problems, it has the potential to miss unimplemented parts of the specification or missing requirements. Where white-box testing is design-driven, that is, driven exclusively by agreed specifications of how each component of software is required to behave, white-box test techniques can accomplish assessment for unimplemented or missing requirements.
Cyclomatic complexity is a software metric used to indicate the complexity of a program. It is a quantitative measure of the number of linearly independent paths through a program's source code. It was developed by Thomas J. McCabe, Sr. in 1976.
In mathematics, and, in particular, in graph theory, a rooted graph is a graph in which one vertex has been distinguished as the root. Both directed and undirected versions of rooted graphs have been studied, and there are also variant definitions that allow multiple roots.
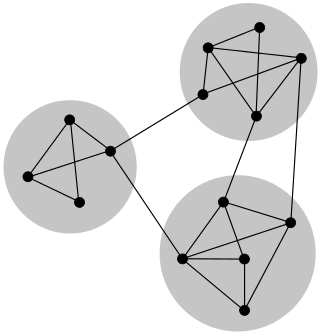
In mathematics and computer science, connectivity is one of the basic concepts of graph theory: it asks for the minimum number of elements that need to be removed to separate the remaining nodes into two or more isolated subgraphs. It is closely related to the theory of network flow problems. The connectivity of a graph is an important measure of its resilience as a network.
Essential complexity is a numerical measure defined by Thomas J. McCabe, Sr., in his highly cited, 1976 paper better known for introducing cyclomatic complexity. McCabe defined essential complexity as the cyclomatic complexity of the reduced CFG after iteratively replacing (reducing) all structured programming control structures, i.e. those having a single entry point and a single exit point with placeholder single statements.
In graph theory, a path decomposition of a graph G is, informally, a representation of G as a "thickened" path graph, and the pathwidth of G is a number that measures how much the path was thickened to form G. More formally, a path-decomposition is a sequence of subsets of vertices of G such that the endpoints of each edge appear in one of the subsets and such that each vertex appears in a contiguous subsequence of the subsets, and the pathwidth is one less than the size of the largest set in such a decomposition. Pathwidth is also known as interval thickness, vertex separation number, or node searching number.
Requirements traceability is a sub-discipline of requirements management within software development and systems engineering. Traceability as a general term is defined by the IEEE Systems and Software Engineering Vocabulary as (1) the degree to which a relationship can be established between two or more products of the development process, especially products having a predecessor-successor or primary-subordinate relationship to one another; (2) the identification and documentation of derivation paths (upward) and allocation or flowdown paths (downward) of work products in the work product hierarchy; (3) the degree to which each element in a software development product establishes its reason for existing; and (4) discernible association among two or more logical entities, such as requirements, system elements, verifications, or tasks.
Linear code sequence and jump (LCSAJ), in the broad sense, is a software analysis method used to identify structural units in code under test. Its primary use is with dynamic software analysis to help answer the question "How much testing is enough?". Dynamic software analysis is used to measure the quality and efficacy of software test data, where the quantification is performed in terms of structural units of the code under test. When used to quantify the structural units exercised by a given set of test data, dynamic analysis is also referred to as structural coverage analysis.

In graph theory, a well-covered graph is an undirected graph in which the minimal vertex covers all have the same size. Here, a vertex cover is a set of vertices that touches all edges, and it is minimal if removing any vertex from it would leave some edge uncovered. Equivalently, well-covered graphs are the graphs in which all maximal independent sets have equal size. Well-covered graphs were defined and first studied by Michael D. Plummer in 1970.
In software engineering, basis path testing, or structured testing, is a white box method for designing test cases. The method analyzes the control-flow graph of a program to find a set of linearly independent paths of execution. The method normally uses McCabe cyclomatic complexity to determine the number of linearly independent paths and then generates test cases for each path thus obtained. Basis path testing guarantees complete branch coverage, but achieves that without covering all possible paths of the control-flow graph – the latter is usually too costly. Basis path testing has been widely used and studied.
Elementary comparison testing (ECT) is a white-box, control-flow, test-design methodology used in software development. The purpose of ECT is to enable detailed testing of complex software. Software code or pseudocode is tested to assess the proper handling of all decision outcomes. As with multiple-condition coverage and basis path testing, coverage of all independent and isolated conditions is accomplished through modified condition/decision coverage (MC/DC). Isolated conditions are aggregated into connected situations creating formal test cases. The independence of a condition is shown by changing the condition value in isolation. Each relevant condition value is covered by test cases.
