In evolutionary biology and population genetics, the error threshold (or critical mutation rate) is a limit on the number of base pairs a self-replicating molecule may have before mutation will destroy the information in subsequent generations of the molecule. The error threshold is crucial to understanding "Eigen's paradox".
The error threshold is a concept in the origins of life (abiogenesis), in particular of very early life, before the advent of DNA. It is postulated that the first self-replicating molecules might have been small ribozyme-like RNA molecules. These molecules consist of strings of base pairs or "digits", and their order is a code that directs how the molecule interacts with its environment. All replication is subject to mutation error. During the replication process, each digit has a certain probability of being replaced by some other digit, which changes the way the molecule interacts with its environment, and may increase or decrease its fitness, or ability to reproduce, in that environment.
It was noted by Manfred Eigen in his 1971 paper (Eigen 1971) that this mutation process places a limit on the number of digits a molecule may have. If a molecule exceeds this critical size, the effect of the mutations becomes overwhelming and a runaway mutation process will destroy the information in subsequent generations of the molecule. The error threshold is also controlled by the "fitness landscape" for the molecules. The fitness landscape is characterized by the two concepts of height (=fitness) and distance (=number of mutations). Similar molecules are "close" to each other, and molecules that are fitter than others and more likely to reproduce, are "higher" in the landscape.
If a particular sequence and its neighbors have a high fitness, they will form a quasispecies and will be able to support longer sequence lengths than a fit sequence with few fit neighbors, or a less fit neighborhood of sequences. Also, it was noted by Wilke (Wilke 2005) that the error threshold concept does not apply in portions of the landscape where there are lethal mutations, in which the induced mutation yields zero fitness and prohibits the molecule from reproducing.
Eigen's paradox
Eigen's paradox is one of the most intractable puzzles in the study of the origins of life. It is thought that the error threshold concept described above limits the size of self replicating molecules to perhaps a few hundred digits, yet almost all life on earth requires much longer molecules to encode their genetic information. This problem is handled in living cells by enzymes that repair mutations, allowing the encoding molecules to reach sizes on the order of millions of base pairs. These large molecules must, of course, encode the very enzymes that repair them, and herein lies Eigen's paradox, first put forth by Manfred Eigen in his 1971 paper (Eigen 1971).[1] Simply stated, Eigen's paradox amounts to the following:
Without error correction enzymes, the maximum size of a replicating molecule is about 100 base pairs.
For a replicating molecule to encode error correction enzymes, it must be substantially larger than 100 bases.
This is a chicken-or-egg kind of a paradox, with an even more difficult solution. Which came first, the large genome or the error correction enzymes? A number of solutions to this paradox have been proposed:
Stochastic corrector model (Szathmáry & Maynard Smith, 1995). In this proposed solution, a number of primitive molecules of say, two different types, are associated with each other in some way, perhaps by a capsule or "cell wall". If their reproductive success is enhanced by having, say, equal numbers in each cell, and reproduction occurs by division in which each of various types of molecules are randomly distributed among the "children", the process of selection will promote such equal representation in the cells, even though one of the molecules may have a selective advantage over the other.
Relaxed error threshold (Kun et al., 2005) - Studies of actual ribozymes indicate that the mutation rate can be substantially less than first expected - on the order of 0.001 per base pair per replication. This may allow sequence lengths of the order of 7-8 thousand base pairs, sufficient to incorporate rudimentary error correction enzymes.
A simple mathematical model
Consider a 3-digit molecule [A,B,C] where A, B, and C can take on the values 0 and 1. There are eight such sequences ([000], [001], [010], [011], [100], [101], [110], and [111]). Let's say that the [000] molecule is the most fit; upon each replication it produces an average of copies, where . This molecule is called the "master sequence". The other seven sequences are less fit; they each produce only 1 copy per replication. The replication of each of the three digits is done with a mutation rate of μ. In other words, at every replication of a digit of a sequence, there is a probability that it will be erroneous; 0 will be replaced by 1 or vice versa. Let's ignore double mutations and the death of molecules (the population will grow infinitely), and divide the eight molecules into three classes depending on their Hamming distance from the master sequence:
Hamming distance
Sequence(s)
0
[000]
1
[001] [010] [100]
2
[110] [101] [011]
3
[111]
Note that the number of sequences for distance d is just the binomial coefficient for L=3, and that each sequence can be visualized as the vertex of an L=3 dimensional cube, with each edge of the cube specifying a mutation path in which the change Hamming distance is either zero or ±1. It can be seen that, for example, one third of the mutations of the [001] molecules will produce [000] molecules, while the other two thirds will produce the class 2 molecules [011] and [101]. We can now write the expression for the child populations of class i in terms of the parent populations .
where the matrix 'w’ that incorporates natural selection and mutation, according to quasispecies model, is given by:
where is the probability that an entire molecule will be replicated successfully. The eigenvectors of the w matrix will yield the equilibrium population numbers for each class. For example, if the mutation rate μ is zero, we will have Q=1, and the equilibrium concentrations will be . The master sequence, being the fittest will be the only one to survive. If we have a replication fidelity of Q=0.95 and genetic advantage of a=1.05, then the equilibrium concentrations will be roughly . It can be seen that the master sequence is not as dominant; nevertheless, sequences with low Hamming distance are in majority. If we have a replication fidelity of Q approaching 0, then the equilibrium concentrations will be roughly . This is a population with equal number of each of 8 sequences. (If we had perfectly equal population of all sequences, we would have populations of [1,3,3,1]/8.)
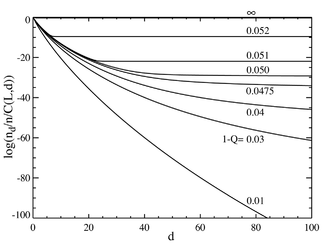
If we now go to the case where the number of base pairs is large, say L=100, we obtain behavior that resembles a phase transition. The plot below on the left shows a series of equilibrium concentrations divided by the binomial coefficient . (This multiplication will show the population for an individual sequence at that distance, and will yield a flat line for an equal distribution.) The selective advantage of the master sequence is set at a=1.05. The horizontal axis is the Hamming distance d. The various curves are for various total mutation rates . It is seen that for low values of the total mutation rate, the population consists of a quasispecies gathered in the neighborhood of the master sequence. Above a total mutation rate of about 1-Q=0.05, the distribution quickly spreads out to populate all sequences equally. The plot below on the right shows the fractional population of the master sequence as a function of the total mutation rate. Again it is seen that below a critical mutation rate of about 1-Q=0.05, the master sequence contains most of the population, while above this rate, it contains only about of the total population.
Population numbers as a function of Hamming distance d and mutation rate (1-Q). The horizontal axis d is the Hamming distance of the molecular sequences from the master sequence. The vertical axis is the logarithm of population for any sequence at that distance divided by total population (thus the division of nd by the binomial coefficient). The total number of digits per sequence is L=100, and the master sequence has a selective advantage of a=1.05.The population of the master sequence as a fraction of the total population (n) as a function of overall mutation rate (1-Q). The total number of digits per sequence is L=100, and the master sequence has a selective advantage of a=1.05. The "phase transition" is seen to occur at roughly 1-Q=0.05.
It can be seen that there is a sharp transition at a value of 1-Q just a bit larger than 0.05. For mutation rates above this value, the population of the master sequence drops to practically zero. Above this value, it dominates.
In the limit as L approaches infinity, the system does in fact have a phase transition at a critical value of Q: . One could think of the overall mutation rate (1-Q) as a sort of "temperature", which "melts" the fidelity of the molecular sequences above the critical "temperature" of . For faithful replication to occur, the information must be "frozen" into the genome.
In a chemical reaction, chemical equilibrium is the state in which both the reactants and products are present in concentrations which have no further tendency to change with time, so that there is no observable change in the properties of the system. This state results when the forward reaction proceeds at the same rate as the reverse reaction. The reaction rates of the forward and backward reactions are generally not zero, but they are equal. Thus, there are no net changes in the concentrations of the reactants and products. Such a state is known as dynamic equilibrium.
The quasispecies model is a description of the process of the Darwinian evolution of certain self-replicating entities within the framework of physical chemistry. A quasispecies is a large group or "cloud" of related genotypes that exist in an environment of high mutation rate, where a large fraction of offspring are expected to contain one or more mutations relative to the parent. This is in contrast to a species, which from an evolutionary perspective is a more-or-less stable single genotype, most of the offspring of which will be genetically accurate copies.
Molecular evolution is the process of change in the sequence composition of cellular molecules such as DNA, RNA, and proteins across generations. The field of molecular evolution uses principles of evolutionary biology and population genetics to explain patterns in these changes. Major topics in molecular evolution concern the rates and impacts of single nucleotide changes, neutral evolution vs. natural selection, origins of new genes, the genetic nature of complex traits, the genetic basis of speciation, the evolution of development, and ways that evolutionary forces influence genomic and phenotypic changes.
The neutral theory of molecular evolution holds that most evolutionary changes occur at the molecular level, and most of the variation within and between species are due to random genetic drift of mutant alleles that are selectively neutral. The theory applies only for evolution at the molecular level, and is compatible with phenotypic evolution being shaped by natural selection as postulated by Charles Darwin. The neutral theory allows for the possibility that most mutations are deleterious, but holds that because these are rapidly removed by natural selection, they do not make significant contributions to variation within and between species at the molecular level. A neutral mutation is one that does not affect an organism's ability to survive and reproduce. The neutral theory assumes that most mutations that are not deleterious are neutral rather than beneficial. Because only a fraction of gametes are sampled in each generation of a species, the neutral theory suggests that a mutant allele can arise within a population and reach fixation by chance, rather than by selective advantage.
In thermodynamics, the chemical potential of a species is the energy that can be absorbed or released due to a change of the particle number of the given species, e.g. in a chemical reaction or phase transition. The chemical potential of a species in a mixture is defined as the rate of change of free energy of a thermodynamic system with respect to the change in the number of atoms or molecules of the species that are added to the system. Thus, it is the partial derivative of the free energy with respect to the amount of the species, all other species' concentrations in the mixture remaining constant. When both temperature and pressure are held constant, and the number of particles is expressed in moles, the chemical potential is the partial molar Gibbs free energy. At chemical equilibrium or in phase equilibrium, the total sum of the product of chemical potentials and stoichiometric coefficients is zero, as the free energy is at a minimum. In a system in diffusion equilibrium, the chemical potential of any chemical species is uniformly the same everywhere throughout the system.
In mathematics, a measure-preserving dynamical system is an object of study in the abstract formulation of dynamical systems, and ergodic theory in particular. Measure-preserving systems obey the Poincaré recurrence theorem, and are a special case of conservative systems. They provide the formal, mathematical basis for a broad range of physical systems, and, in particular, many systems from classical mechanics as well as systems in thermodynamic equilibrium.
In computer science, an evolution strategy (ES) is an optimization technique based on ideas of evolution. It belongs to the general class of evolutionary computation or artificial evolution methodologies.
Compartmental models are a very general modelling technique. They are often applied to the mathematical modelling of infectious diseases. The population is assigned to compartments with labels – for example, S, I, or R,. People may progress between compartments. The order of the labels usually shows the flow patterns between the compartments; for example SEIS means susceptible, exposed, infectious, then susceptible again.
In numerical analysis, the order of convergence and the rate of convergence of a convergent sequence are quantities that represent how quickly the sequence approaches its limit. A sequence that converges to is said to have order of convergence and rate of convergence if
The equilibrium constant of a chemical reaction is the value of its reaction quotient at chemical equilibrium, a state approached by a dynamic chemical system after sufficient time has elapsed at which its composition has no measurable tendency towards further change. For a given set of reaction conditions, the equilibrium constant is independent of the initial analytical concentrations of the reactant and product species in the mixture. Thus, given the initial composition of a system, known equilibrium constant values can be used to determine the composition of the system at equilibrium. However, reaction parameters like temperature, solvent, and ionic strength may all influence the value of the equilibrium constant.
Mutation–selection balance is an equilibrium in the number of deleterious alleles in a population that occurs when the rate at which deleterious alleles are created by mutation equals the rate at which deleterious alleles are eliminated by selection. The majority of genetic mutations are neutral or deleterious; beneficial mutations are relatively rare. The resulting influx of deleterious mutations into a population over time is counteracted by negative selection, which acts to purge deleterious mutations. Setting aside other factors, the equilibrium number of deleterious alleles is then determined by a balance between the deleterious mutation rate and the rate at which selection purges those mutations.
Error catastrophe refers to the cumulative loss of genetic information in a lineage of organisms due to high mutation rates. The mutation rate above which error catastrophe occurs is called the error threshold. Both terms were coined by Manfred Eigen in his mathematical evolutionary theory of the quasispecies.
The principle of detailed balance can be used in kinetic systems which are decomposed into elementary processes. It states that at equilibrium, each elementary process is in equilibrium with its reverse process.
A viral quasispecies is a population structure of viruses with a large number of variant genomes. Quasispecies result from high mutation rates as mutants arise continually and change in relative frequency as viral replication and selection proceeds.
A number of different Markov models of DNA sequence evolution have been proposed. These substitution models differ in terms of the parameters used to describe the rates at which one nucleotide replaces another during evolution. These models are frequently used in molecular phylogenetic analyses. In particular, they are used during the calculation of likelihood of a tree and they are used to estimate the evolutionary distance between sequences from the observed differences between the sequences.
Tajima's D is a population genetic test statistic created by and named after the Japanese researcher Fumio Tajima. Tajima's D is computed as the difference between two measures of genetic diversity: the mean number of pairwise differences and the number of segregating sites, each scaled so that they are expected to be the same in a neutrally evolving population of constant size.
The Langmuir adsorption model explains adsorption by assuming an adsorbate behaves as an ideal gas at isothermal conditions. According to the model, adsorption and desorption are reversible processes. This model even explains the effect of pressure i.e. at these conditions the adsorbate's partial pressure, , is related to the volume of it, V, adsorbed onto a solid adsorbent. The adsorbent, as indicated in the figure, is assumed to be an ideal solid surface composed of a series of distinct sites capable of binding the adsorbate. The adsorbate binding is treated as a chemical reaction between the adsorbate gaseous molecule and an empty sorption site, S. This reaction yields an adsorbed species with an associated equilibrium constant :
Equilibrium chemistry is concerned with systems in chemical equilibrium. The unifying principle is that the free energy of a system at equilibrium is the minimum possible, so that the slope of the free energy with respect to the reaction coordinate is zero. This principle, applied to mixtures at equilibrium provides a definition of an equilibrium constant. Applications include acid–base, host–guest, metal–complex, solubility, partition, chromatography and redox equilibria.
In chemistry, a hypercycle is an abstract model of organization of self-replicating molecules connected in a cyclic, autocatalytic manner. It was introduced in an ordinary differential equation (ODE) form by the Nobel Prize in Chemistry winner Manfred Eigen in 1971 and subsequently further extended in collaboration with Peter Schuster. It was proposed as a solution to the error threshold problem encountered during modelling of replicative molecules that hypothetically existed on the primordial Earth. As such, it explained how life on Earth could have begun using only relatively short genetic sequences, which in theory were too short to store all essential information. The hypercycle is a special case of the replicator equation. The most important properties of hypercycles are autocatalytic growth competition between cycles, once-for-ever selective behaviour, utilization of small selective advantage, rapid evolvability, increased information capacity, and selection against parasitic branches.
In evolutionary biology, the GARD model is a general kinetic model for homeostatic-growth and fission of compositional-assemblies, with specific application towards lipids.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.