
Probability theory is the branch of mathematics concerned with probability. Although there are several different probability interpretations, probability theory treats the concept in a rigorous mathematical manner by expressing it through a set of axioms. Typically these axioms formalise probability in terms of a probability space, which assigns a measure taking values between 0 and 1, termed the probability measure, to a set of outcomes called the sample space. Any specified subset of the sample space is called an event. Central subjects in probability theory include discrete and continuous random variables, probability distributions, and stochastic processes . Although it is not possible to perfectly predict random events, much can be said about their behavior. Two major results in probability theory describing such behaviour are the law of large numbers and the central limit theorem.
In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events.
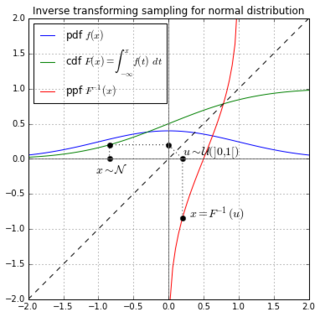
Inverse transform sampling is a basic method for pseudo-random number sampling, i.e., for generating sample numbers at random from any probability distribution given its cumulative distribution function.
Tournament selection is a method of selecting an individual from a population of individuals in a genetic algorithm. Tournament selection involves running several "tournaments" among a few individuals chosen at random from the population. The winner of each tournament is selected for crossover. Selection pressure, a probabilistic measure of a chromosome's likelihood of participation in the tournament based on the participant selection pool size, is easily adjusted by changing the tournament size. The reason is that if the tournament size is larger, weak individuals have a smaller chance to be selected, because, if a weak individual is selected to be in a tournament, there is a higher probability that a stronger individual is also in that tournament.
In computer programming, gene expression programming (GEP) is an evolutionary algorithm that creates computer programs or models. These computer programs are complex tree structures that learn and adapt by changing their sizes, shapes, and composition, much like a living organism. And like living organisms, the computer programs of GEP are also encoded in simple linear chromosomes of fixed length. Thus, GEP is a genotype–phenotype system, benefiting from a simple genome to keep and transmit the genetic information and a complex phenotype to explore the environment and adapt to it.
Selection is the stage of a genetic algorithm or more general evolutionary algorithm in which individual genomes are chosen from a population for later breeding.

A mating pool is a concept used in evolutionary computation, which refers to a family of algorithms used to solve optimization and search problems.

The secretary problem demonstrates a scenario involving optimal stopping theory that is studied extensively in the fields of applied probability, statistics, and decision theory. It is also known as the marriage problem, the sultan's dowry problem, the fussy suitor problem, the googol game, and the best choice problem.

In probability theory and machine learning, the multi-armed bandit problem is a problem in which a fixed limited set of resources must be allocated between competing (alternative) choices in a way that maximizes their expected gain, when each choice's properties are only partially known at the time of allocation, and may become better understood as time passes or by allocating resources to the choice. This is a classic reinforcement learning problem that exemplifies the exploration–exploitation tradeoff dilemma. The name comes from imagining a gambler at a row of slot machines, who has to decide which machines to play, how many times to play each machine and in which order to play them, and whether to continue with the current machine or try a different machine. The multi-armed bandit problem also falls into the broad category of stochastic scheduling.
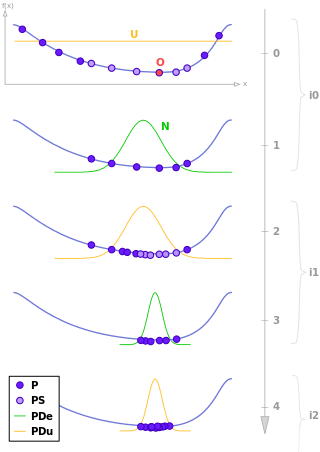
Estimation of distribution algorithms (EDAs), sometimes called probabilistic model-building genetic algorithms (PMBGAs), are stochastic optimization methods that guide the search for the optimum by building and sampling explicit probabilistic models of promising candidate solutions. Optimization is viewed as a series of incremental updates of a probabilistic model, starting with the model encoding an uninformative prior over admissible solutions and ending with the model that generates only the global optima.
In probability theory, the Gillespie algorithm generates a statistically correct trajectory of a stochastic equation system for which the reaction rates are known. It was created by Joseph L. Doob and others, presented by Dan Gillespie in 1976, and popularized in 1977 in a paper where he uses it to simulate chemical or biochemical systems of reactions efficiently and accurately using limited computational power. As computers have become faster, the algorithm has been used to simulate increasingly complex systems. The algorithm is particularly useful for simulating reactions within cells, where the number of reagents is low and keeping track of the position and behaviour of individual molecules is computationally feasible. Mathematically, it is a variant of a dynamic Monte Carlo method and similar to the kinetic Monte Carlo methods. It is used heavily in computational systems biology.
A stochastic simulation is a simulation of a system that has variables that can change stochastically (randomly) with individual probabilities.
Covariance matrix adaptation evolution strategy (CMA-ES) is a particular kind of strategy for numerical optimization. Evolution strategies (ES) are stochastic, derivative-free methods for numerical optimization of non-linear or non-convex continuous optimization problems. They belong to the class of evolutionary algorithms and evolutionary computation. An evolutionary algorithm is broadly based on the principle of biological evolution, namely the repeated interplay of variation and selection: in each generation (iteration) new individuals are generated by variation, usually in a stochastic way, of the current parental individuals. Then, some individuals are selected to become the parents in the next generation based on their fitness or objective function value . Like this, over the generation sequence, individuals with better and better -values are generated.
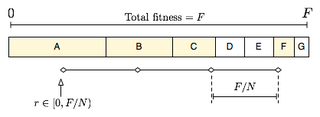
Stochastic universal sampling (SUS) is a technique used in genetic algorithms for selecting potentially useful solutions for recombination. It was introduced by James Baker.
Stochastic approximation methods are a family of iterative methods typically used for root-finding problems or for optimization problems. The recursive update rules of stochastic approximation methods can be used, among other things, for solving linear systems when the collected data is corrupted by noise, or for approximating extreme values of functions which cannot be computed directly, but only estimated via noisy observations.
In computer science and operations research, the artificial bee colony algorithm (ABC) is an optimization algorithm based on the intelligent foraging behaviour of honey bee swarm, proposed by Derviş Karaboğa in 2005.
Reward-based selection is a technique used in evolutionary algorithms for selecting potentially useful solutions for recombination. The probability of being selected for an individual is proportional to the cumulative reward obtained by the individual. The cumulative reward can be computed as a sum of the individual reward and the reward, inherited from parents.
Biogeography-based optimization (BBO) is an evolutionary algorithm (EA) that optimizes a function by stochastically and iteratively improving candidate solutions with regard to a given measure of quality, or fitness function. BBO belongs to the class of metaheuristics since it includes many variations, and since it does not make any assumptions about the problem and can therefore be applied to a wide class of problems.
Mean-field particle methods are a broad class of interacting type Monte Carlo algorithms for simulating from a sequence of probability distributions satisfying a nonlinear evolution equation. These flows of probability measures can always be interpreted as the distributions of the random states of a Markov process whose transition probabilities depends on the distributions of the current random states. A natural way to simulate these sophisticated nonlinear Markov processes is to sample a large number of copies of the process, replacing in the evolution equation the unknown distributions of the random states by the sampled empirical measures. In contrast with traditional Monte Carlo and Markov chain Monte Carlo methods these mean-field particle techniques rely on sequential interacting samples. The terminology mean-field reflects the fact that each of the samples interacts with the empirical measures of the process. When the size of the system tends to infinity, these random empirical measures converge to the deterministic distribution of the random states of the nonlinear Markov chain, so that the statistical interaction between particles vanishes. In other words, starting with a chaotic configuration based on independent copies of initial state of the nonlinear Markov chain model, the chaos propagates at any time horizon as the size the system tends to infinity; that is, finite blocks of particles reduces to independent copies of the nonlinear Markov process. This result is called the propagation of chaos property. The terminology "propagation of chaos" originated with the work of Mark Kac in 1976 on a colliding mean-field kinetic gas model.







