Related Research Articles
In artificial intelligence, genetic programming (GP) is a technique of evolving programs, starting from a population of unfit programs, fit for a particular task by applying operations analogous to natural genetic processes to the population of programs.

In computer science and operations research, a genetic algorithm (GA) is a metaheuristic inspired by the process of natural selection that belongs to the larger class of evolutionary algorithms (EA). Genetic algorithms are commonly used to generate high-quality solutions to optimization and search problems by relying on biologically inspired operators such as mutation, crossover and selection. Some examples of GA applications include optimizing decision trees for better performance, solving sudoku puzzles, hyperparameter optimization, causal inference, etc.

In computational intelligence (CI), an evolutionary algorithm (EA) is a subset of evolutionary computation, a generic population-based metaheuristic optimization algorithm. An EA uses mechanisms inspired by biological evolution, such as reproduction, mutation, recombination, and selection. Candidate solutions to the optimization problem play the role of individuals in a population, and the fitness function determines the quality of the solutions. Evolution of the population then takes place after the repeated application of the above operators.

In computer science, evolutionary computation is a family of algorithms for global optimization inspired by biological evolution, and the subfield of artificial intelligence and soft computing studying these algorithms. In technical terms, they are a family of population-based trial and error problem solvers with a metaheuristic or stochastic optimization character.
Fitness proportionate selection, also known as roulette wheel selection, is a genetic operator used in genetic algorithms for selecting potentially useful solutions for recombination.
A genetic operator is an operator used in genetic algorithms to guide the algorithm towards a solution to a given problem. There are three main types of operators, which must work in conjunction with one another in order for the algorithm to be successful. Genetic operators are used to create and maintain genetic diversity, combine existing solutions into new solutions (crossover) and select between solutions (selection). In his book discussing the use of genetic programming for the optimization of complex problems, computer scientist John Koza has also identified an 'inversion' or 'permutation' operator; however, the effectiveness of this operator has never been conclusively demonstrated and this operator is rarely discussed.
A fitness function is a particular type of objective function that is used to summarise, as a single figure of merit, how close a given design solution is to achieving the set aims. Fitness functions are used in evolutionary algorithms (EA), such as genetic programming and genetic algorithms to guide simulations towards optimal design solutions.
In genetic algorithms and evolutionary computation, crossover, also called recombination, is a genetic operator used to combine the genetic information of two parents to generate new offspring. It is one way to stochastically generate new solutions from an existing population, and is analogous to the crossover that happens during sexual reproduction in biology. Solutions can also be generated by cloning an existing solution, which is analogous to asexual reproduction. Newly generated solutions may be mutated before being added to the population.
Mutation is a genetic operator used to maintain genetic diversity of the chromosomes of a population of a genetic or, more generally, an evolutionary algorithm (EA). It is analogous to biological mutation.
In computer science and mathematical optimization, a metaheuristic is a higher-level procedure or heuristic designed to find, generate, tune, or select a heuristic that may provide a sufficiently good solution to an optimization problem or a machine learning problem, especially with incomplete or imperfect information or limited computation capacity. Metaheuristics sample a subset of solutions which is otherwise too large to be completely enumerated or otherwise explored. Metaheuristics may make relatively few assumptions about the optimization problem being solved and so may be usable for a variety of problems.
In computer programming, gene expression programming (GEP) is an evolutionary algorithm that creates computer programs or models. These computer programs are complex tree structures that learn and adapt by changing their sizes, shapes, and composition, much like a living organism. And like living organisms, the computer programs of GEP are also encoded in simple linear chromosomes of fixed length. Thus, GEP is a genotype–phenotype system, benefiting from a simple genome to keep and transmit the genetic information and a complex phenotype to explore the environment and adapt to it.
Selection is the stage of a genetic algorithm or more general evolutionary algorithm in which individual genomes are chosen from a population for later breeding.

A mating pool is a concept used in evolutionary computation, which refers to a family of algorithms used to solve optimization and search problems.
In evolutionary algorithms (EA), the term of premature convergence means that a population for an optimization problem converged too early, resulting in being suboptimal. In this context, the parental solutions, through the aid of genetic operators, are not able to generate offspring that are superior to, or outperform, their parents. Premature convergence is a common problem found in evolutionary algorithms in general and genetic algorithms in particular, as it leads to a loss, or convergence of, a large number of alleles, subsequently making it very difficult to search for a specific gene in which the alleles were present. An allele is considered lost if, in a population, a gene is present, where all individuals are sharing the same value for that particular gene. An allele is, as defined by De Jong, considered to be a converged allele, when 95% of a population share the same value for a certain gene.
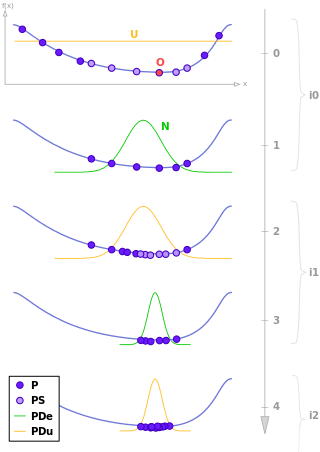
Estimation of distribution algorithms (EDAs), sometimes called probabilistic model-building genetic algorithms (PMBGAs), are stochastic optimization methods that guide the search for the optimum by building and sampling explicit probabilistic models of promising candidate solutions. Optimization is viewed as a series of incremental updates of a probabilistic model, starting with the model encoding an uninformative prior over admissible solutions and ending with the model that generates only the global optima.
A memetic algorithm (MA) in computer science and operations research, is an extension of the traditional genetic algorithm (GA) or more general evolutionary algorithm (EA). It may provide a sufficiently good solution to an optimization problem. It uses a suitable heuristic or local search technique to improve the quality of solutions generated by the EA and to reduce the likelihood of premature convergence.
Kalyanmoy Deb is an Indian computer scientist. Deb is the Herman E. & Ruth J. Koenig Endowed Chair Professor in the Department of Electrical and Computing Engineering at Michigan State University. Deb is also a professor in the Department of Computer Science and Engineering and the Department of Mechanical Engineering at Michigan State University.
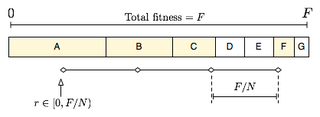
Stochastic universal sampling (SUS) is a technique used in genetic algorithms for selecting potentially useful solutions for recombination. It was introduced by James Baker.
In statistics, a simple random sample is a subset of individuals chosen from a larger set in which a subset of individuals are chosen randomly, all with the same probability. It is a process of selecting a sample in a random way. In SRS, each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals. A simple random sample is an unbiased sampling technique. Simple random sampling is a basic type of sampling and can be a component of other more complex sampling methods.
Reward-based selection is a technique used in evolutionary algorithms for selecting potentially useful solutions for recombination. The probability of being selected for an individual is proportional to the cumulative reward obtained by the individual. The cumulative reward can be computed as a sum of the individual reward and the reward, inherited from parents.
References
- 1 2 Miller, Brad; Goldberg, David (1995). "Genetic Algorithms, Tournament Selection, and the Effects of Noise" (PDF). Complex Systems. 9: 193–212. S2CID 6491320. Archived from the original (PDF) on 2019-08-31.
- ↑ Goldberg, David E.; Korb, Bradley; Deb, Kalyanmoy (1989). "Messy Genetic Algorithms: Motivation, Analysis, and First Results" (PDF). Complex Systems. 3 (5): 493–530.
- ↑ Blickle, Tobias; Thiele, Lothar (December 1996). "A Comparison of Selection Schemes Used in Evolutionary Algorithms". Evolutionary Computation. 4 (4): 361–394. CiteSeerX 10.1.1.15.9584 . doi:10.1162/evco.1996.4.4.361. S2CID 42718510.
- ↑ Cantú-Paz, Erick, ed. (2003). Genetic and Evolutionary Computation -- GECCO 2003 : Genetic and Evolutionary Computation Conference Chicago, IL, USA, July 12-16, 2003 Proceedings, Part II. Berlin, Heidelberg: Springer-Verlag Berlin Heidelberg. ISBN 978-3-540-45110-5.
- ↑ Goldberg, David; Deb, Kalyanmoy (1991). "A comparative analysis of selection schemes used in genetic algorithms" (PDF). Foundations of Genetic Algorithms. 1: 69–93. doi:10.1016/b978-0-08-050684-5.50008-2. ISBN 9780080506845. S2CID 938257. Archived from the original (PDF) on 2018-07-17.