Information retrieval (IR) in computing and information science is the task of identifying and retrieving information system resources that are relevant to an information need. The information need can be specified in the form of a search query. In the case of document retrieval, queries can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
In computing, a search engine is an information retrieval software system designed to help find information stored on one or more computer systems. Search engines discover, crawl, transform, and store information for retrieval and presentation in response to user queries. The search results are usually presented in a list and are commonly called hits. The most widely used type of search engine is a web search engine, which searches for information on the World Wide Web.
A query language, also known as data query language or database query language (DQL), is a computer language used to make queries in databases and information systems. In database systems, query languages rely on strict theory to retrieve information. A well known example is the Structured Query Language (SQL).

A metasearch engine is an online information retrieval tool that uses the data of a web search engine to produce its own results. Metasearch engines take input from a user and immediately query search engines for results. Sufficient data is gathered, ranked, and presented to the users.
Document retrieval is defined as the matching of some stated user query against a set of free-text records. These records could be any type of mainly unstructured text, such as newspaper articles, real estate records or paragraphs in a manual. User queries can range from multi-sentence full descriptions of an information need to a few words.
Stop words are the words in a stop list which are filtered out before or after processing of natural language data (text) because they are deemed insignificant. There is no single universal list of stop words used by all natural language processing tools, nor any agreed upon rules for identifying stop words, and indeed not all tools even use such a list. Therefore, any group of words can be chosen as the stop words for a given purpose. The "general trend in [information retrieval] systems over time has been from standard use of quite large stop lists to very small stop lists to no stop list whatsoever".

The Text REtrieval Conference (TREC) is an ongoing series of workshops focusing on a list of different information retrieval (IR) research areas, or tracks. It is co-sponsored by the National Institute of Standards and Technology (NIST) and the Intelligence Advanced Research Projects Activity, and began in 1992 as part of the TIPSTER Text program. Its purpose is to support and encourage research within the information retrieval community by providing the infrastructure necessary for large-scale evaluation of text retrieval methodologies and to increase the speed of lab-to-product transfer of technology.
In computer science, an inverted index is a database index storing a mapping from content, such as words or numbers, to its locations in a table, or in a document or a set of documents. The purpose of an inverted index is to allow fast full-text searches, at a cost of increased processing when a document is added to the database. The inverted file may be the database file itself, rather than its index. It is the most popular data structure used in document retrieval systems, used on a large scale for example in search engines. Additionally, several significant general-purpose mainframe-based database management systems have used inverted list architectures, including ADABAS, DATACOM/DB, and Model 204.
A search engine is a software system that provides hyperlinks to web pages and other relevant information on the Web in response to a user's query. The user inputs a query within a web browser or a mobile app, and the search results are often a list of hyperlinks, accompanied by textual summaries and images. Users also have the option of limiting the search to a specific type of results, such as images, videos, or news.
Search engine indexing is the collecting, parsing, and storing of data to facilitate fast and accurate information retrieval. Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science. An alternate name for the process, in the context of search engines designed to find web pages on the Internet, is web indexing.
Query expansion (QE) is the process of reformulating a given query to improve retrieval performance in information retrieval operations, particularly in the context of query understanding. In the context of search engines, query expansion involves evaluating a user's input and expanding the search query to match additional documents. Query expansion involves techniques such as:
A web query or web search query is a query that a user enters into a web search engine to satisfy their information needs. Web search queries are distinctive in that they are often plain text and boolean search directives are rarely used. They vary greatly from standard query languages, which are governed by strict syntax rules as command languages with keyword or positional parameters.
Enterprise search is software technology for searching data sources internal to a company, typically intranet and database content. The search is generally offered only to users internal to the company. Enterprise search can be contrasted with web search, which applies search technology to documents on the open web, and desktop search, which applies search technology to the content on a single computer.
Subject indexing is the act of describing or classifying a document by index terms, keywords, or other symbols in order to indicate what different documents are about, to summarize their contents or to increase findability. In other words, it is about identifying and describing the subject of documents. Indexes are constructed, separately, on three distinct levels: terms in a document such as a book; objects in a collection such as a library; and documents within a field of knowledge.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
Ranking of query is one of the fundamental problems in information retrieval (IR), the scientific/engineering discipline behind search engines. Given a query q and a collection D of documents that match the query, the problem is to rank, that is, sort, the documents in D according to some criterion so that the "best" results appear early in the result list displayed to the user. Ranking in terms of information retrieval is an important concept in computer science and is used in many different applications such as search engine queries and recommender systems. A majority of search engines use ranking algorithms to provide users with accurate and relevant results.
Vector space model or term vector model is an algebraic model for representing text documents as vectors such that the distance between vectors represents the relevance between the documents. It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Legal information retrieval is the science of information retrieval applied to legal text, including legislation, case law, and scholarly works. Accurate legal information retrieval is important to provide access to the law to laymen and legal professionals. Its importance has increased because of the vast and quickly increasing amount of legal documents available through electronic means. Legal information retrieval is a part of the growing field of legal informatics.
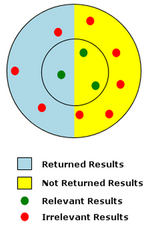
Evaluation measures for an information retrieval (IR) system assess how well an index, search engine, or database returns results from a collection of resources that satisfy a user's query. They are therefore fundamental to the success of information systems and digital platforms.
Query understanding is the process of inferring the intent of a search engine user by extracting semantic meaning from the searcher’s keywords. Query understanding methods generally take place before the search engine retrieves and ranks results. It is related to natural language processing but specifically focused on the understanding of search queries. Query understanding is at the heart of technologies like Amazon Alexa, Apple's Siri. Google Assistant, IBM's Watson, and Microsoft's Cortana.