Related Research Articles

In computer science and operations research, a genetic algorithm (GA) is a metaheuristic inspired by the process of natural selection that belongs to the larger class of evolutionary algorithms (EA). Genetic algorithms are commonly used to generate high-quality solutions to optimization and search problems by relying on biologically inspired operators such as mutation, crossover and selection. Some examples of GA applications include optimizing decision trees for better performance, solving sudoku puzzles, hyperparameter optimization, causal inference, etc.
In computational intelligence (CI), an evolutionary algorithm (EA) is a subset of evolutionary computation, a generic population-based metaheuristic optimization algorithm. An EA uses mechanisms inspired by biological evolution, such as reproduction, mutation, recombination, and selection. Candidate solutions to the optimization problem play the role of individuals in a population, and the fitness function determines the quality of the solutions. Evolution of the population then takes place after the repeated application of the above operators.
In computer science, evolutionary computation is a family of algorithms for global optimization inspired by biological evolution, and the subfield of artificial intelligence and soft computing studying these algorithms. In technical terms, they are a family of population-based trial and error problem solvers with a metaheuristic or stochastic optimization character.
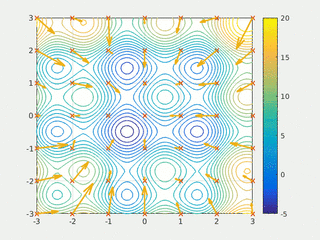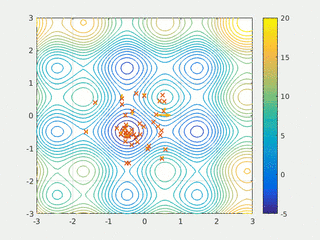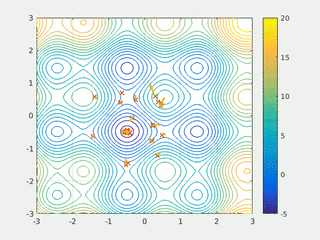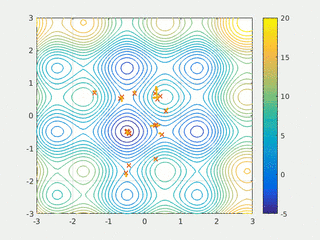
In computational science, particle swarm optimization (PSO) is a computational method that optimizes a problem by iteratively trying to improve a candidate solution with regard to a given measure of quality. It solves a problem by having a population of candidate solutions, here dubbed particles, and moving these particles around in the search-space according to simple mathematical formula over the particle's position and velocity. Each particle's movement is influenced by its local best known position, but is also guided toward the best known positions in the search-space, which are updated as better positions are found by other particles. This is expected to move the swarm toward the best solutions.
A fitness function is a particular type of objective function that is used to summarise, as a single figure of merit, how close a given design solution is to achieving the set aims. Fitness functions are used in evolutionary algorithms (EA), such as genetic programming and genetic algorithms to guide simulations towards optimal design solutions.
Neuroevolution, or neuro-evolution, is a form of artificial intelligence that uses evolutionary algorithms to generate artificial neural networks (ANN), parameters, and rules. It is most commonly applied in artificial life, general game playing and evolutionary robotics. The main benefit is that neuroevolution can be applied more widely than supervised learning algorithms, which require a syllabus of correct input-output pairs. In contrast, neuroevolution requires only a measure of a network's performance at a task. For example, the outcome of a game can be easily measured without providing labeled examples of desired strategies. Neuroevolution is commonly used as part of the reinforcement learning paradigm, and it can be contrasted with conventional deep learning techniques that use gradient descent on a neural network with a fixed topology.
In genetic algorithms and evolutionary computation, crossover, also called recombination, is a genetic operator used to combine the genetic information of two parents to generate new offspring. It is one way to stochastically generate new solutions from an existing population, and is analogous to the crossover that happens during sexual reproduction in biology. Solutions can also be generated by cloning an existing solution, which is analogous to asexual reproduction. Newly generated solutions may be mutated before being added to the population.
Mutation is a genetic operator used to maintain genetic diversity of the chromosomes of a population of a genetic or, more generally, an evolutionary algorithm (EA). It is analogous to biological mutation.
In genetic algorithms (GA), or more general, evolutionary algorithms (EA), a chromosome is a set of parameters which define a proposed solution of the problem that the evolutionary algorithm is trying to solve. The set of all solutions, also called individuals according to the biological model, is known as the population. The genome of an individual consists of one, more rarely of several, chromosomes and corresponds to the genetic representation of the task to be solved. A chromosome is composed of a set of genes, where a gene consists of one or more semantically connected parameters, which are often also called decision variables. They determine one or more phenotypic characteristics of the individual or at least have an influence on them. In the basic form of genetic algorithms, the chromosome is represented as a binary string, while in later variants and in EAs in general, a wide variety of other data structures are used.
In computer science and mathematical optimization, a metaheuristic is a higher-level procedure or heuristic designed to find, generate, tune, or select a heuristic that may provide a sufficiently good solution to an optimization problem or a machine learning problem, especially with incomplete or imperfect information or limited computation capacity. Metaheuristics sample a subset of solutions which is otherwise too large to be completely enumerated or otherwise explored. Metaheuristics may make relatively few assumptions about the optimization problem being solved and so may be usable for a variety of problems.

Learning classifier systems, or LCS, are a paradigm of rule-based machine learning methods that combine a discovery component with a learning component. Learning classifier systems seek to identify a set of context-dependent rules that collectively store and apply knowledge in a piecewise manner in order to make predictions. This approach allows complex solution spaces to be broken up into smaller, simpler parts.
Selection is the stage of a genetic algorithm or more general evolutionary algorithm in which individual genomes are chosen from a population for later breeding. Selection mechanisms are also used to choose candidate solutions (individuals) for the next generation. Retaining the best individuals in a generation unchanged in the next generation, is called elitism or elitist selection. It is a successful (slight) variant of the general process of constructing a new population.
In evolutionary algorithms (EA), the term of premature convergence means that a population for an optimization problem converged too early, resulting in being suboptimal. In this context, the parental solutions, through the aid of genetic operators, are not able to generate offspring that are superior to, or outperform, their parents. Premature convergence is a common problem found in evolutionary algorithms in general and genetic algorithms in particular, as it leads to a loss, or convergence of, a large number of alleles, subsequently making it very difficult to search for a specific gene in which the alleles were present. An allele is considered lost if, in a population, a gene is present, where all individuals are sharing the same value for that particular gene. An allele is, as defined by De Jong, considered to be a converged allele, when 95% of a population share the same value for a certain gene.
The expression computational intelligence (CI) usually refers to the ability of a computer to learn a specific task from data or experimental observation. Even though it is commonly considered a synonym of soft computing, there is still no commonly accepted definition of computational intelligence.
In artificial intelligence, artificial immune systems (AIS) are a class of computationally intelligent, rule-based machine learning systems inspired by the principles and processes of the vertebrate immune system. The algorithms are typically modeled after the immune system's characteristics of learning and memory for use in problem-solving.
A memetic algorithm (MA) in computer science and operations research, is an extension of the traditional genetic algorithm (GA) or more general evolutionary algorithm (EA). It may provide a sufficiently good solution to an optimization problem. It uses a suitable heuristic or local search technique to improve the quality of solutions generated by the EA and to reduce the likelihood of premature convergence.
Grammatical evolution (GE) is an evolutionary computation and, more specifically, a genetic programming (GP) technique (or approach) pioneered by Conor Ryan, JJ Collins and Michael O'Neill in 1998 at the BDS Group in the University of Limerick.
Lee Altenberg is an American theoretical biologist. He is on the faculty of the Departments of Information and Computer Sciences and of Mathematics at the University of Hawaiʻi at Mānoa. He is best known for his work that helped establish the evolution of evolvability and modularity in the genotype–phenotype map as areas of investigation in evolutionary biology, for moving theoretical concepts between the fields of evolutionary biology and evolutionary computation, and for his mathematical unification and generalization of modifier gene models for the evolution of biological information transmission, putting under a single mathematical framework the evolution of mutation rates, recombination rates, sexual reproduction rates, and dispersal rates.
This is a chronological table of metaheuristic algorithms that only contains fundamental algorithms. Hybrid algorithms and multi-objective algorithms are not listed in the table below.
The population model of an evolutionary algorithm (EA) describes the structural properties of its population to which its members are subject. A population is the set of all proposed solutions of an EA considered in one iteration, which are also called individuals according to the biological role model. The individuals of a population can generate further individuals as offspring with the help of the genetic operators of the procedure.
References
- ↑ Eiben, A.E.; Smith, J.E. (2015). Introduction to Evolutionary Computing. Natural Computing Series. Berlin, Heidelberg: Springer. p. 40. doi:10.1007/978-3-662-44874-8. ISBN 978-3-662-44873-1. S2CID 20912932.
- ↑ Rothlauf, Franz (2002). Representations for Genetic and Evolutionary Algorithms. Studies in Fuzziness and Soft Computing. Vol. 104. Heidelberg: Physica-Verlag HD. p. 31. doi:10.1007/978-3-642-88094-0. ISBN 978-3-642-88096-4.
- ↑ Eiben, A.E.; Smith, J.E. (2015). "Representation and the Roles of Variation Operators". Introduction to Evolutionary Computing. Natural Computing Series. Berlin, Heidelberg: Springer. pp. 49–51. doi:10.1007/978-3-662-44874-8. ISBN 978-3-662-44873-1. S2CID 20912932.
- ↑ Eiben, A.E.; Smith, J.E. (2015). "Popular Evolutionary Algorithm Variants". Introduction to Evolutionary Computing. Natural Computing Series. Berlin, Heidelberg: Springer. pp. 99–118. doi:10.1007/978-3-662-44874-8. ISBN 978-3-662-44873-1. S2CID 20912932.
- ↑ Fogel, D.B. (1995). "Phenotypes, genotypes, and operators in evolutionary computation". Proceedings of 1995 IEEE International Conference on Evolutionary Computation. Vol. 1. Perth, WA, Australia: IEEE. pp. 193–198. doi:10.1109/ICEC.1995.489143. ISBN 978-0-7803-2759-7. S2CID 17755853.
- ↑ Tomáš Kuthan and Jan Lánský. "Genetic Algorithms in Syllable-Based Text Compression". 2007. p. 26.
- ↑ Eiben, A.E.; Smith, J.E. (2015). "Representation, Mutation, and Recombination". Introduction to Evolutionary Computing. Natural Computing Series. Berlin, Heidelberg: Springer. pp. 49–78. doi:10.1007/978-3-662-44874-8. ISBN 978-3-662-44873-1. S2CID 20912932.
- ↑ Goldberg, David E. (1989). Genetic algorithms in search, optimization, and machine learning. Reading, Mass.: Addison-Wesley. ISBN 0-201-15767-5. OCLC 17674450.
- ↑ Michalewicz, Zbigniew (1996). Genetic Algorithms + Data Structures = Evolution Programs. 3rd, revised and extended edition. Berlin, Heidelberg: Springer. ISBN 978-3-662-03315-9. OCLC 851375253.
- 1 2 Whitley, Darrell (1994). "A genetic algorithm tutorial". Statistics and Computing. 4 (2). doi:10.1007/BF00175354. ISSN 0960-3174. S2CID 3447126.
- ↑ Herrera, F.; Lozano, M.; Verdegay, J.L. (1998). "Tackling Real-Coded Genetic Algorithms: Operators and Tools for Behavioural Analysis". Artificial Intelligence Review. 12 (4): 265–319. doi:10.1023/A:1006504901164. S2CID 6798965.
- ↑ Blume, Christian; Jakob, Wilfried (2002), "GLEAM - An Evolutionary Algorithm for Planning and Control Based on Evolution Strategy", Conf. Proc. of Genetic and Evolutionary Computation Conference (GECCO 2002), vol. Late Breaking Papers, pp. 31–38, retrieved 2023-01-01
- ↑ Hitomi, Nozomi; Selva, Daniel (2018), "Constellation optimization using an evolutionary algorithm with a variable-length chromosome", 2018 IEEE Aerospace Conference, IEEE, pp. 1–12, doi:10.1109/AERO.2018.8396743, ISBN 978-1-5386-2014-4, S2CID 49541423
- ↑ De Jong, Kenneth A. (2006). "Representation". Evolutionary computation : a unified approach. New Delhi: Prentice-Hall of India. pp. 72–75. ISBN 978-81-203-3002-3. OCLC 276452339.
- ↑ Pawar, Sunil Nilkanth; Bichkar, Rajankumar Sadashivrao (2015). "Genetic algorithm with variable length chromosomes for network intrusion detection". International Journal of Automation and Computing. 12 (3): 337–342. doi: 10.1007/s11633-014-0870-x . ISSN 1476-8186. S2CID 255346767.
- ↑ Schwefel, Hans-Paul (1995). Evolution and Optimum Seeking. New York: Wiley & Sons. ISBN 0-471-57148-2. OCLC 30701094.
- ↑ Koza, John R. (1989), Sridharan, N.S. (ed.), "Hierarchical genetic algorithms operating on populations of computer programs", Proceedings of the Eleventh International Joint Conference on Artificial Intelligence IJCAI-89, San Mateo, CA, USA: Morgan Kaufmann, vol. 1, pp. 768–774
- ↑ Rothlauf, Franz (2002). Representations for Genetic and Evolutionary Algorithms. Studies in Fuzziness and Soft Computing. Vol. 104. Heidelberg: Physica-Verlag HD. doi:10.1007/978-3-642-88094-0. ISBN 978-3-642-88096-4.
- ↑ Whigham, Peter A.; Dick, Grant; Maclaurin, James (2017). "On the mapping of genotype to phenotype in evolutionary algorithms". Genetic Programming and Evolvable Machines. 18 (3): 353–361. doi:10.1007/s10710-017-9288-x. ISSN 1389-2576. S2CID 254510517.
- ↑ Caruana, Richard A.; Schaffer, J. David (1988), "Representation and Hidden Bias: Gray vs. Binary Coding for Genetic Algorithms", Machine Learning Proceedings 1988, Elsevier, pp. 153–161, doi:10.1016/b978-0-934613-64-4.50021-9, ISBN 978-0-934613-64-4 , retrieved 2023-01-19
- ↑ Liepins, Gunar E.; Vose, Michael D. (1990). "Representational issues in genetic optimization". Journal of Experimental & Theoretical Artificial Intelligence. 2 (2): 101–115. doi:10.1080/09528139008953717. ISSN 0952-813X.
- ↑ Coli, M.; Palazzari, P. (1995), "Searching for the optimal coding in genetic algorithms", Proceedings of 1995 IEEE International Conference on Evolutionary Computation, IEEE, doi:10.1109/ICEC.1995, ISBN 978-0-7803-2759-7
- ↑ Eiben, Agoston E. (2015). "Representation (Definition of Individuals)". Introduction to evolutionary computing. J. E. Smith (2nd ed.). Berlin, Heidelberg: Springer. pp. 28–30. ISBN 978-3-662-44874-8. OCLC 913232837.
- ↑ Rothlauf, Franz (2006). "Three Elements of a Theory of Representations". Representations for genetic and evolutionary algorithms (2nd ed.). Heidelberg: Springer. pp. 33–96. ISBN 978-3-540-32444-7. OCLC 262692044.
- ↑ Galván-López, Edgar; Dignum, Stephen; Poli, Riccardo (2008), O’Neill, Michael; Vanneschi, Leonardo; Gustafson, Steven; Esparcia Alcázar, Anna Isabel (eds.), "The Effects of Constant Neutrality on Performance and Problem Hardness in GP", Genetic Programming, Lecture Notes in Computer Science, Berlin, Heidelberg: Springer, vol. 4971, pp. 312–324, doi:10.1007/978-3-540-78671-9_27, ISBN 978-3-540-78670-2, S2CID 6803107 , retrieved 2023-01-21
- ↑ Galván-López, Edgar; Poli, Riccardo; Kattan, Ahmed; O’Neill, Michael; Brabazon, Anthony (2011). "Neutrality in evolutionary algorithms… What do we know?". Evolving Systems. 2 (3): 145–163. doi:10.1007/s12530-011-9030-5. hdl: 10197/3532 . ISSN 1868-6478. S2CID 15951086.
- ↑ Knowles, Joshua D.; Watson, Richard A. (2002), Guervós, Juan Julián Merelo; Adamidis, Panagiotis; Beyer, Hans-Georg; Schwefel, Hans-Paul (eds.), "On the Utility of Redundant Encodings in Mutation-Based Evolutionary Search", Parallel Problem Solving from Nature — PPSN VII, Berlin, Heidelberg: Springer, vol. 2439, pp. 88–98, doi:10.1007/3-540-45712-7_9, ISBN 978-3-540-44139-7 , retrieved 2023-01-21
- ↑ Eiben, A.E.; Smith, J.E. (2015). "Hybridisation During Genotype to Phenotype Mapping". Introduction to Evolutionary Computing. Natural Computing Series. Berlin, Heidelberg: Springer. pp. 177–178. doi:10.1007/978-3-662-44874-8. ISBN 978-3-662-44873-1. S2CID 20912932.
- ↑ Hart, Emma; Ross, Peter; Nelson, Jeremy (1998). "Solving a Real-World Problem Using an Evolving Heuristically Driven Schedule Builder". Evolutionary Computation. 6 (1): 61–80. doi:10.1162/evco.1998.6.1.61. ISSN 1063-6560. PMID 10021741. S2CID 6898505.
- ↑ Eiben, A.E.; Smith, J.E. (2015). "Permutation Representation". Introduction to Evolutionary Computing. Natural Computing Series. Berlin, Heidelberg: Springer. pp. 67–74. doi:10.1007/978-3-662-44874-8. ISBN 978-3-662-44873-1. S2CID 20912932.
- ↑ Larrañaga, P.; Kuijpers, C.M.H.; Murga, R.H.; Inza, I.; Dizdarevic, S. (1999). "Genetic Algorithms for the Travelling Salesman Problem: A Review of Representations and Operators". Artificial Intelligence Review. 13 (2): 129–170. doi:10.1023/A:1006529012972. S2CID 10284682.
- ↑ Bruns, Ralf (1997-01-01). "Evolutionary computation approaches for scheduling". In Baeck, Thomas; Fogel, D.B; Michalewicz, Z (eds.). Handbook of Evolutionary Computation. CRC Press. doi:10.1201/9780367802486. ISBN 978-0-367-80248-6.
- 1 2 Jakob, Wilfried; Strack, Sylvia; Quinte, Alexander; Bengel, Günther; Stucky, Karl-Uwe; Süß, Wolfgang (2013-04-22). "Fast Rescheduling of Multiple Workflows to Constrained Heterogeneous Resources Using Multi-Criteria Memetic Computing". Algorithms. 6 (2): 245–277. doi: 10.3390/a6020245 . ISSN 1999-4893.
- ↑ Brucker, Peter (2007). Scheduling Algorithms. Berlin, Heidelberg: Springer. doi:10.1007/978-3-540-69516-5. ISBN 978-3-540-69515-8.
- ↑ Sakellariou, Rizos; Zhao, Henan; Tsiakkouri, Eleni; Dikaiakos, Marios D. (2007), Gorlatch, Sergei; Danelutto, Marco (eds.), "Scheduling Workflows with Budget Constraints", Integrated Research in GRID Computing, Boston, MA: Springer US, pp. 189–202, doi:10.1007/978-0-387-47658-2_14, ISBN 978-0-387-47656-8 , retrieved 2023-01-20
- ↑ Fujita, Kikuo; Akagi, Shinsuke; Hirokawa, Noriyasu (1993-09-19). "Hybrid Approach for Optimal Nesting Using a Genetic Algorithm and a Local Minimization Algorithm". Proceedings of the ASME 1993 Design Technical Conferences. 19th Design Automation Conference: Volume 1 — Mechanical System Dynamics; Concurrent and Robust Design; Design for Assembly and Manufacture; Genetic Algorithms in Design and Structural Optimization. Albuquerque, New Mexico, USA: American Society of Mechanical Engineers. pp. 477–484. doi:10.1115/DETC1993-0337. ISBN 978-0-7918-1181-8.
- ↑ Jakob, Wilfried (2021), "Layout Planning as an Example for Smart Handling of Complex Constraints", Applying Evolutionary Algorithms Successfully - A Guide Gained from Real-world Applications., KIT Scientific Working Papers, vol.170, Karlsruhe: KIT Scientific Publishing, pp. 12–14, arXiv: 2107.11300 , doi:10.5445/IR/1000135763, S2CID 236318422