
In the theory of computation, a branch of theoretical computer science, a pushdown automaton (PDA) is a type of automaton that employs a stack.
In the mathematical field of real analysis, the monotone convergence theorem is any of a number of related theorems proving the convergence of monotonic sequences that are also bounded. Informally, the theorems state that if a sequence is increasing and bounded above by a supremum, then the sequence will converge to the supremum; in the same way, if a sequence is decreasing and is bounded below by an infimum, it will converge to the infimum.
In mathematics, computer science, and logic, rewriting covers a wide range of methods of replacing subterms of a formula with other terms. Such methods may be achieved by rewriting systems. In their most basic form, they consist of a set of objects, plus relations on how to transform those objects.
In econometrics, the autoregressive conditional heteroskedasticity (ARCH) model is a statistical model for time series data that describes the variance of the current error term or innovation as a function of the actual sizes of the previous time periods' error terms; often the variance is related to the squares of the previous innovations. The ARCH model is appropriate when the error variance in a time series follows an autoregressive (AR) model; if an autoregressive moving average (ARMA) model is assumed for the error variance, the model is a generalized autoregressive conditional heteroskedasticity (GARCH) model.
In automata theory, a finite-state machine is called a deterministic finite automaton (DFA), if
In linear algebra and functional analysis, the min-max theorem, or variational theorem, or Courant–Fischer–Weyl min-max principle, is a result that gives a variational characterization of eigenvalues of compact Hermitian operators on Hilbert spaces. It can be viewed as the starting point of many results of similar nature.
In information theory, Shannon's source coding theorem establishes the statistical limits to possible data compression for data whose source is an independent identically-distributed random variable, and the operational meaning of the Shannon entropy.
In theoretical computer science and mathematical logic a string rewriting system (SRS), historically called a semi-Thue system, is a rewriting system over strings from a alphabet. Given a binary relation between fixed strings over the alphabet, called rewrite rules, denoted by , an SRS extends the rewriting relation to all strings in which the left- and right-hand side of the rules appear as substrings, that is , where , , , and are strings.
In set theory, -induction, also called epsilon-induction or set-induction, is a principle that can be used to prove that all sets satisfy a given property. Considered as an axiomatic principle, it is called the axiom schema of set induction.

In mathematics, an upper set of a partially ordered set is a subset with the following property: if s is in S and if x in X is larger than s, then x is in S. In other words, this means that any x element of X that is to some element of S is necessarily also an element of S. The term lower set is defined similarly as being a subset S of X with the property that any element x of X that is to some element of S is necessarily also an element of S.
In automata theory, a deterministic pushdown automaton is a variation of the pushdown automaton. The class of deterministic pushdown automata accepts the deterministic context-free languages, a proper subset of context-free languages.
In information theory, information dimension is an information measure for random vectors in Euclidean space, based on the normalized entropy of finely quantized versions of the random vectors. This concept was first introduced by Alfréd Rényi in 1959.
In theoretical computer science, a small-bias sample space is a probability distribution that fools parity functions. In other words, no parity function can distinguish between a small-bias sample space and the uniform distribution with high probability, and hence, small-bias sample spaces naturally give rise to pseudorandom generators for parity functions.
The Anderson impurity model, named after Philip Warren Anderson, is a Hamiltonian that is used to describe magnetic impurities embedded in metals. It is often applied to the description of Kondo effect-type problems, such as heavy fermion systems and Kondo insulators. In its simplest form, the model contains a term describing the kinetic energy of the conduction electrons, a two-level term with an on-site Coulomb repulsion that models the impurity energy levels, and a hybridization term that couples conduction and impurity orbitals. For a single impurity, the Hamiltonian takes the form
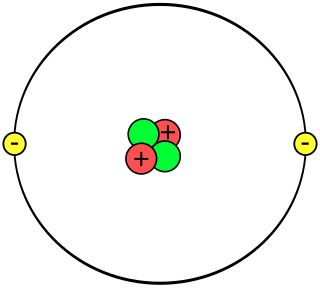
A helium atom is an atom of the chemical element helium. Helium is composed of two electrons bound by the electromagnetic force to a nucleus containing two protons along with either one or two neutrons, depending on the isotope, held together by the strong force. Unlike for hydrogen, a closed-form solution to the Schrödinger equation for the helium atom has not been found. However, various approximations, such as the Hartree–Fock method, can be used to estimate the ground state energy and wavefunction of the atom.
The Stoner criterion is a condition to be fulfilled for the ferromagnetic order to arise in a simplified model of a solid. It is named after Edmund Clifton Stoner.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
Generalized relative entropy is a measure of dissimilarity between two quantum states. It is a "one-shot" analogue of quantum relative entropy and shares many properties of the latter quantity.
In mathematics, the injective tensor product of two topological vector spaces (TVSs) was introduced by Alexander Grothendieck and was used by him to define nuclear spaces. An injective tensor product is in general not necessarily complete, so its completion is called the completed injective tensor products. Injective tensor products have applications outside of nuclear spaces. In particular, as described below, up to TVS-isomorphism, many TVSs that are defined for real or complex valued functions, for instance, the Schwartz space or the space of continuously differentiable functions, can be immediately extended to functions valued in a Hausdorff locally convex TVS without any need to extend definitions from real/complex-valued functions to -valued functions.
In mathematics, a convergence space, also called a generalized convergence, is a set together with a relation called a convergence that satisfies certain properties relating elements of X with the family of filters on X. Convergence spaces generalize the notions of convergence that are found in point-set topology, including metric convergence and uniform convergence. Every topological space gives rise to a canonical convergence but there are convergences, known as non-topological convergences, that do not arise from any topological space. Examples of convergences that are in general non-topological include convergence in measure and almost everywhere convergence. Many topological properties have generalizations to convergence spaces.

















































