Related Research Articles

In computer science, heapsort is a comparison-based sorting algorithm. Heapsort can be thought of as an improved selection sort: like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to more quickly find the largest element in each step.

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
In computer science, radix sort is a non-comparative sorting algorithm. It avoids comparison by creating and distributing elements into buckets according to their radix. For elements with more than one significant digit, this bucketing process is repeated for each digit, while preserving the ordering of the prior step, until all digits have been considered. For this reason, radix sort has also been called bucket sort and digital sort.
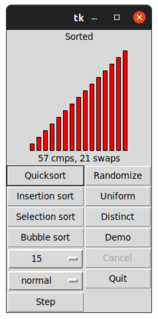
In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.
In computer science, best, worst, and average cases of a given algorithm express what the resource usage is at least, at most and on average, respectively. Usually the resource being considered is running time, i.e. time complexity, but could also be memory or other resource. Best case is the function which performs the minimum number of steps on input data of n elements. Worst case is the function which performs the maximum number of steps on input data of size n. Average case is the function which performs an average number of steps on input data of n elements.
In computer science, divide and conquer is an algorithm design paradigm. A divide-and-conquer algorithm recursively breaks down a problem into two or more sub-problems of the same or related type, until these become simple enough to be solved directly. The solutions to the sub-problems are then combined to give a solution to the original problem.
Introsort or introspective sort is a hybrid sorting algorithm that provides both fast average performance and (asymptotically) optimal worst-case performance. It begins with quicksort, it switches to heapsort when the recursion depth exceeds a level based on the number of elements being sorted and it switches to insertion sort when the number of elements is below some threshold. This combines the good parts of the three algorithms, with practical performance comparable to quicksort on typical data sets and worst-case O(n log n) runtime due to the heap sort. Since the three algorithms it uses are comparison sorts, it is also a comparison sort.
In computer science, a selection algorithm is an algorithm for finding the kth smallest number in a list or array; such a number is called the kth order statistic. This includes the cases of finding the minimum, maximum, and median elements. There are O(n)-time selection algorithms, and sublinear performance is possible for structured data; in the extreme, O(1) for an array of sorted data. Selection is a subproblem of more complex problems like the nearest neighbor and shortest path problems. Many selection algorithms are derived by generalizing a sorting algorithm, and conversely some sorting algorithms can be derived as repeated application of selection.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key and creating point clouds. k-d trees are a special case of binary space partitioning trees.
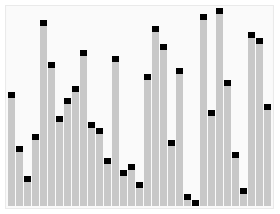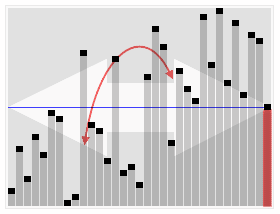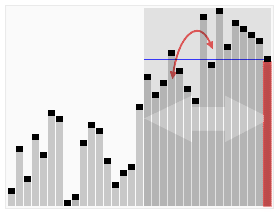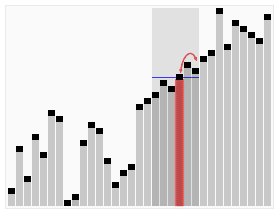
In computer science, quickselect is a selection algorithm to find the kth smallest element in an unordered list. It is related to the quicksort sorting algorithm. Like quicksort, it was developed by Tony Hoare, and thus is also known as Hoare's selection algorithm. Like quicksort, it is efficient in practice and has good average-case performance, but has poor worst-case performance. Quickselect and its variants are the selection algorithms most often used in efficient real-world implementations.

A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list. The only requirement is that the operator forms a total preorder over the data, with:
- if a ≤ b and b ≤ c then a ≤ c (transitivity)
- for all a and b, a ≤ b or b ≤ a (connexity).

Quicksort is an in-place sorting algorithm. Developed by British computer scientist Tony Hoare in 1959 and published in 1961, it is still a commonly used algorithm for sorting. When implemented well, it can be somewhat faster than merge sort and about two or three times faster than heapsort.
sort is a generic function in the C++ Standard Library for doing comparison sorting. The function originated in the Standard Template Library (STL).

A tree sort is a sort algorithm that builds a binary search tree from the elements to be sorted, and then traverses the tree (in-order) so that the elements come out in sorted order. Its typical use is sorting elements online: after each insertion, the set of elements seen so far is available in sorted order.
Spreadsort is a sorting algorithm invented by Steven J. Ross in 2002. It combines concepts from distribution-based sorts, such as radix sort and bucket sort, with partitioning concepts from comparison sorts such as quicksort and mergesort. In experimental results it was shown to be highly efficient, often outperforming traditional algorithms such as quicksort, particularly on distributions exhibiting structure and string sorting. There is an open-source implementation with performance analysis and benchmarks, and HTML documentation .
David "Dave" Musser is a professor emeritus of computer science at the Rensselaer Polytechnic Institute in Troy, New York, United States.
In computer science, partial sorting is a relaxed variant of the sorting problem. Total sorting is the problem of returning a list of items such that its elements all appear in order, while partial sorting is returning a list of the k smallest elements in order. The other elements may also be sorted, as in an in-place partial sort, or may be discarded, which is common in streaming partial sorts. A common practical example of partial sorting is computing the "Top 100" of some list.
In computer science, the median of medians is an approximate (median) selection algorithm, frequently used to supply a good pivot for an exact selection algorithm, mainly the quickselect, that selects the kth smallest element of an initially unsorted array. Median of medians finds an approximate median in linear time only, which is limited but an additional overhead for quickselect. When this approximate median is used as an improved pivot, the worst-case complexity of quickselect reduces significantly from quadratic to linear, which is also the asymptotically optimal worst-case complexity of any selection algorithm. In other words, the median of medians is an approximate median-selection algorithm that helps building an asymptotically optimal, exact general selection algorithm, by producing good pivot elements.
A hybrid algorithm is an algorithm that combines two or more other algorithms that solve the same problem, and is mostly used in programming languages like C++, either choosing one, or switching between them over the course of the algorithm. This is generally done to combine desired features of each, so that the overall algorithm is better than the individual components.
References
- Musser, David R. (1997). "Introspective Sorting and Selection Algorithms". Software: Practice and Experience. 27 (8): 983–993. doi:10.1002/(SICI)1097-024X(199708)27:8<983::AID-SPE117>3.0.CO;2-#.