Related Research Articles

In computer science, heapsort is a comparison-based sorting algorithm which can be thought of as "an implementation of selection sort using the right data structure." Like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to efficiently find the largest element in each step.

Insertion sort is a simple sorting algorithm that builds the final sorted array (or list) one item at a time by comparisons. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
In computer science, radix sort is a non-comparative sorting algorithm. It avoids comparison by creating and distributing elements into buckets according to their radix. For elements with more than one significant digit, this bucketing process is repeated for each digit, while preserving the ordering of the prior step, until all digits have been considered. For this reason, radix sort has also been called bucket sort and digital sort.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.

Bucket sort, or bin sort, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a distribution sort, a generalization of pigeonhole sort that allows multiple keys per bucket, and is a cousin of radix sort in the most-to-least significant digit flavor. Bucket sort can be implemented with comparisons and therefore can also be considered a comparison sort algorithm. The computational complexity depends on the algorithm used to sort each bucket, the number of buckets to use, and whether the input is uniformly distributed.
In computer science, an in-place algorithm is an algorithm that operates directly on the input data structure without requiring extra space proportional to the input size. In other words, it modifies the input in place, without creating a separate copy of the data structure. An algorithm which is not in-place is sometimes called not-in-place or out-of-place.

In computer science, a self-balancing binary search tree (BST) is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions. These operations when designed for a self-balancing binary search tree, contain precautionary measures against boundlessly increasing tree height, so that these abstract data structures receive the attribute "self-balancing".
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .
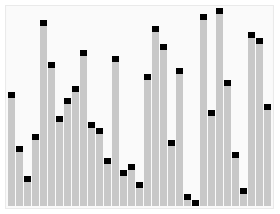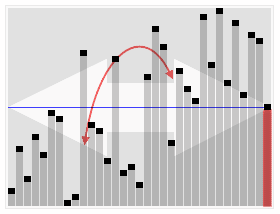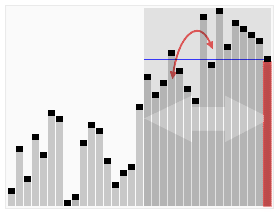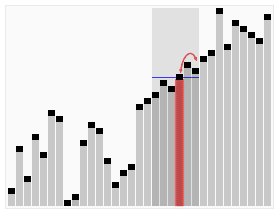
In computer science, quickselect is a selection algorithm to find the kth smallest element in an unordered list, also known as the kth order statistic. Like the related quicksort sorting algorithm, it was developed by Tony Hoare, and thus is also known as Hoare's selection algorithm. Like quicksort, it is efficient in practice and has good average-case performance, but has poor worst-case performance. Quickselect and its variants are the selection algorithms most often used in efficient real-world implementations.

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
sort is a generic function in the C++ Standard Library for doing comparison sorting. The function originated in the Standard Template Library (STL).
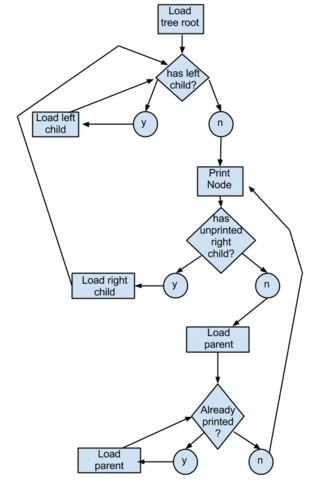
A tree sort is a sort algorithm that builds a binary search tree from the elements to be sorted, and then traverses the tree (in-order) so that the elements come out in sorted order. Its typical use is sorting elements online: after each insertion, the set of elements seen so far is available in sorted order.
Spreadsort is a sorting algorithm invented by Steven J. Ross in 2002. It combines concepts from distribution-based sorts, such as radix sort and bucket sort, with partitioning concepts from comparison sorts such as quicksort and mergesort. In experimental results it was shown to be highly efficient, often outperforming traditional algorithms such as quicksort, particularly on distributions exhibiting structure and string sorting. There is an open-source implementation with performance analysis and benchmarks, and HTML documentation .
In computer science, introselect is a selection algorithm that is a hybrid of quickselect and median of medians which has fast average performance and optimal worst-case performance. Introselect is related to the introsort sorting algorithm: these are analogous refinements of the basic quickselect and quicksort algorithms, in that they both start with the quick algorithm, which has good average performance and low overhead, but fall back to an optimal worst-case algorithm if the quick algorithm does not progress rapidly enough. Both algorithms were introduced by David Musser in, with the purpose of providing generic algorithms for the C++ Standard Library that have both fast average performance and optimal worst-case performance, thus allowing the performance requirements to be tightened.
Flashsort is a distribution sorting algorithm showing linear computational complexity O(n) for uniformly distributed data sets and relatively little additional memory requirement. The original work was published in 1998 by Karl-Dietrich Neubert.
In computer science, partial sorting is a relaxed variant of the sorting problem. Total sorting is the problem of returning a list of items such that its elements all appear in order, while partial sorting is returning a list of the k smallest elements in order. The other elements may also be sorted, as in an in-place partial sort, or may be discarded, which is common in streaming partial sorts. A common practical example of partial sorting is computing the "Top 100" of some list.
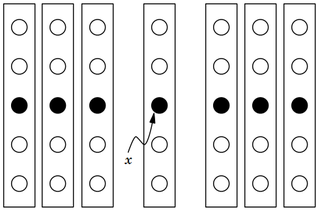
In computer science, the median of medians is an approximate median selection algorithm, frequently used to supply a good pivot for an exact selection algorithm, most commonly quickselect, that selects the kth smallest element of an initially unsorted array. Median of medians finds an approximate median in linear time. Using this approximate median as an improved pivot, the worst-case complexity of quickselect reduces from quadratic to linear, which is also the asymptotically optimal worst-case complexity of any selection algorithm. In other words, the median of medians is an approximate median-selection algorithm that helps building an asymptotically optimal, exact general selection algorithm, by producing good pivot elements.
Multi-key quicksort, also known as three-way radix quicksort, is an algorithm for sorting strings. This hybrid of quicksort and radix sort was originally suggested by P. Shackleton, as reported in one of C.A.R. Hoare's seminal papers on quicksort; its modern incarnation was developed by Jon Bentley and Robert Sedgewick in the mid-1990s. The algorithm is designed to exploit the property that in many problems, strings tend to have shared prefixes.
Proportion extend sort is an in-place, comparison-based sorting algorithm which attempts to improve on the performance, particularly the worst-case performance, of quicksort.
References
- ↑ "Generic Algorithms", David Musser
- ↑ libstdc++ Documentation: Sorting Algorithms
- ↑ libc++ source code: sort
- ↑ Kutenin, Danila (20 April 2022). "Changing std::sort at Google's Scale and Beyond". Experimental chill.
- ↑ Array.Sort Method (Array)
- ↑ Go 1.20.3 source code
- ↑ Java 14 source code
- ↑ Peters, Orson R. L. (2021). "orlp/pdqsort: Pattern-defeating quicksort". GitHub. arXiv: 2106.05123 .
- ↑ "slice.sort_unstable(&mut self)". Rust.
The current algorithm is based on pattern-defeating quicksort by Orson Peters, which combines the fast average case of randomized quicksort with the fast worst case of heapsort, while achieving linear time on slices with certain patterns. It uses some randomization to avoid degenerate cases, but with a fixed seed to always provide deterministic behavior.
- ↑ Lammich, Peter (2020). Efficient Verified Implementation of Introsort and Pdqsort. IJCAR 2020: Automated Reasoning. Vol. 12167. pp. 307–323. doi: 10.1007/978-3-030-51054-1_18 .
General
- Musser, David R. (1997). "Introspective Sorting and Selection Algorithms". Software: Practice and Experience. 27 (8): 983–993. doi:10.1002/(SICI)1097-024X(199708)27:8<983::AID-SPE117>3.0.CO;2-#. Archived from the original on 7 March 2023.
- Niklaus Wirth. Algorithms and Data Structures. Prentice-Hall, Inc., 1985. ISBN 0-13-022005-1.