
In computer science, heapsort is a comparison-based sorting algorithm which can be thought of as "an implementation of selection sort using the right data structure." Like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to efficiently find the largest element in each step.

Insertion sort is a simple sorting algorithm that builds the final sorted array (or list) one item at a time by comparisons. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
Merge algorithms are a family of algorithms that take multiple sorted lists as input and produce a single list as output, containing all the elements of the inputs lists in sorted order. These algorithms are used as subroutines in various sorting algorithms, most famously merge sort.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.
In computer science, best, worst, and average cases of a given algorithm express what the resource usage is at least, at most and on average, respectively. Usually the resource being considered is running time, i.e. time complexity, but could also be memory or some other resource. Best case is the function which performs the minimum number of steps on input data of n elements. Worst case is the function which performs the maximum number of steps on input data of size n. Average case is the function which performs an average number of steps on input data of n elements.

Bucket sort, or bin sort, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a distribution sort, a generalization of pigeonhole sort that allows multiple keys per bucket, and is a cousin of radix sort in the most-to-least significant digit flavor. Bucket sort can be implemented with comparisons and therefore can also be considered a comparison sort algorithm. The computational complexity depends on the algorithm used to sort each bucket, the number of buckets to use, and whether the input is uniformly distributed.
Introsort or introspective sort is a hybrid sorting algorithm that provides both fast average performance and (asymptotically) optimal worst-case performance. It begins with quicksort, it switches to heapsort when the recursion depth exceeds a level based on (the logarithm of) the number of elements being sorted and it switches to insertion sort when the number of elements is below some threshold. This combines the good parts of the three algorithms, with practical performance comparable to quicksort on typical data sets and worst-case O(n log n) runtime due to the heap sort. Since the three algorithms it uses are comparison sorts, it is also a comparison sort.
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .
A random permutation is a random ordering of a set of objects, that is, a permutation-valued random variable. The use of random permutations is often fundamental to fields that use randomized algorithms such as coding theory, cryptography, and simulation. A good example of a random permutation is the shuffling of a deck of cards: this is ideally a random permutation of the 52 cards.
Library sort or gapped insertion sort is a sorting algorithm that uses an insertion sort, but with gaps in the array to accelerate subsequent insertions. The name comes from an analogy:
Suppose a librarian were to store their books alphabetically on a long shelf, starting with the As at the left end, and continuing to the right along the shelf with no spaces between the books until the end of the Zs. If the librarian acquired a new book that belongs to the B section, once they find the correct space in the B section, they will have to move every book over, from the middle of the Bs all the way down to the Zs in order to make room for the new book. This is an insertion sort. However, if they were to leave a space after every letter, as long as there was still space after B, they would only have to move a few books to make room for the new one. This is the basic principle of the Library Sort.

A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list. The only requirement is that the operator forms a total preorder over the data, with:
- if a ≤ b and b ≤ c then a ≤ c (transitivity)
- for all a and b, a ≤ b or b ≤ a (connexity).

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
sort is a generic function in the C++ Standard Library for doing comparison sorting. The function originated in the Standard Template Library (STL).
An American flag sort is an efficient, in-place variant of radix sort that distributes items into buckets. Non-comparative sorting algorithms such as radix sort and American flag sort are typically used to sort large objects such as strings, for which comparison is not a unit-time operation. American flag sort iterates through the bits of the objects, considering several bits of each object at a time. For each set of bits, American flag sort makes two passes through the array of objects: first to count the number of objects that will fall in each bin, and second to place each object in its bucket. This works especially well when sorting a byte at a time, using 256 buckets. With some optimizations, it is twice as fast as quicksort for large sets of strings.
The Fisher–Yates shuffle is an algorithm for shuffling a finite sequence. The algorithm takes a list of all the elements of the sequence, and continually determines the next element in the shuffled sequence by randomly drawing an element from the list until no elements remain. The algorithm produces an unbiased permutation: every permutation is equally likely. The modern version of the algorithm takes time proportional to the number of items being shuffled and shuffles them in place.
Samplesort is a sorting algorithm that is a divide and conquer algorithm often used in parallel processing systems. Conventional divide and conquer sorting algorithms partitions the array into sub-intervals or buckets. The buckets are then sorted individually and then concatenated together. However, if the array is non-uniformly distributed, the performance of these sorting algorithms can be significantly throttled. Samplesort addresses this issue by selecting a sample of size s from the n-element sequence, and determining the range of the buckets by sorting the sample and choosing p−1 < s elements from the result. These elements then divide the array into p approximately equal-sized buckets. Samplesort is described in the 1970 paper, "Samplesort: A Sampling Approach to Minimal Storage Tree Sorting", by W. D. Frazer and A. C. McKellar.
Bubble sort, sometimes referred to as sinking sort, is a simple sorting algorithm that repeatedly steps through the input list element by element, comparing the current element with the one after it, swapping their values if needed. These passes through the list are repeated until no swaps have to be performed during a pass, meaning that the list has become fully sorted. The algorithm, which is a comparison sort, is named for the way the larger elements "bubble" up to the top of the list.

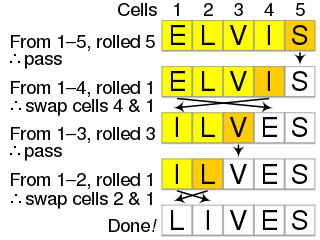
Cycle sort is an in-place, unstable sorting algorithm, a comparison sort that is theoretically optimal in terms of the total number of writes to the original array, unlike any other in-place sorting algorithm. It is based on the idea that the permutation to be sorted can be factored into cycles, which can individually be rotated to give a sorted result.

Heap's algorithm generates all possible permutations of n objects. It was first proposed by B. R. Heap in 1963. The algorithm minimizes movement: it generates each permutation from the previous one by interchanging a single pair of elements; the other n−2 elements are not disturbed. In a 1977 review of permutation-generating algorithms, Robert Sedgewick concluded that it was at that time the most effective algorithm for generating permutations by computer.







