In number theory, an arithmetic, arithmetical, or number-theoretic function is for most authors any function f(n) whose domain is the positive integers and whose range is a subset of the complex numbers. Hardy & Wright include in their definition the requirement that an arithmetical function "expresses some arithmetical property of n".

In theoretical physics, a Feynman diagram is a pictorial representation of the mathematical expressions describing the behavior and interaction of subatomic particles. The scheme is named after American physicist Richard Feynman, who introduced the diagrams in 1948. The interaction of subatomic particles can be complex and difficult to understand; Feynman diagrams give a simple visualization of what would otherwise be an arcane and abstract formula. According to David Kaiser, "Since the middle of the 20th century, theoretical physicists have increasingly turned to this tool to help them undertake critical calculations. Feynman diagrams have revolutionized nearly every aspect of theoretical physics." While the diagrams are applied primarily to quantum field theory, they can also be used in other areas of physics, such as solid-state theory. Frank Wilczek wrote that the calculations that won him the 2004 Nobel Prize in Physics "would have been literally unthinkable without Feynman diagrams, as would [Wilczek's] calculations that established a route to production and observation of the Higgs particle."
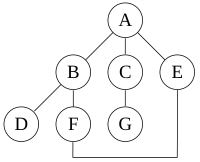
In computer science, a red–black tree is a specialised binary search tree data structure noted for fast storage and retrieval of ordered information, and a guarantee that operations will complete within a known time. Compared to other self-balancing binary search trees, the nodes in a red-black tree hold an extra bit called "color" representing "red" and "black" which is used when re-organising the tree to ensure that it is always approximately balanced.
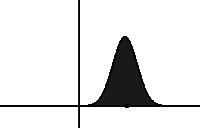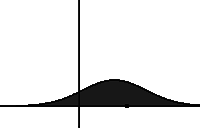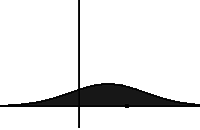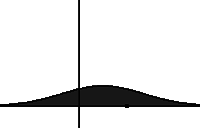
In statistical mechanics and information theory, the Fokker–Planck equation is a partial differential equation that describes the time evolution of the probability density function of the velocity of a particle under the influence of drag forces and random forces, as in Brownian motion. The equation can be generalized to other observables as well. The Fokker-Planck equation has multiple applications in information theory, graph theory, data science, finance, economics etc.
In mathematics, the Kronecker delta is a function of two variables, usually just non-negative integers. The function is 1 if the variables are equal, and 0 otherwise:
In the calculus of variations and classical mechanics, the Euler–Lagrange equations are a system of second-order ordinary differential equations whose solutions are stationary points of the given action functional. The equations were discovered in the 1750s by Swiss mathematician Leonhard Euler and Italian mathematician Joseph-Louis Lagrange.
In mathematics, the Hodge star operator or Hodge star is a linear map defined on the exterior algebra of a finite-dimensional oriented vector space endowed with a nondegenerate symmetric bilinear form. Applying the operator to an element of the algebra produces the Hodge dual of the element. This map was introduced by W. V. D. Hodge.
In bioinformatics, neighbor joining is a bottom-up (agglomerative) clustering method for the creation of phylogenetic trees, created by Naruya Saitou and Masatoshi Nei in 1987. Usually based on DNA or protein sequence data, the algorithm requires knowledge of the distance between each pair of taxa to create the phylogenetic tree.

The path integral formulation is a description in quantum mechanics that generalizes the action principle of classical mechanics. It replaces the classical notion of a single, unique classical trajectory for a system with a sum, or functional integral, over an infinity of quantum-mechanically possible trajectories to compute a quantum amplitude.
A directional derivative is a concept in multivariable calculus that measures the rate at which a function changes in a particular direction at a given point.
In computer science, a topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks. Precisely, a topological sort is a graph traversal in which each node v is visited only after all its dependencies are visited. A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time. Topological sorting has many applications especially in ranking problems such as feedback arc set. Topological sorting is possible even when the DAG has disconnected components.
Mehrotra's predictor–corrector method in optimization is a specific interior point method for linear programming. It was proposed in 1989 by Sanjay Mehrotra.
In numerical analysis, the Crank–Nicolson method is a finite difference method used for numerically solving the heat equation and similar partial differential equations. It is a second-order method in time. It is implicit in time, can be written as an implicit Runge–Kutta method, and it is numerically stable. The method was developed by John Crank and Phyllis Nicolson in the mid 20th century.
In general relativity, the Gibbons–Hawking–York boundary term is a term that needs to be added to the Einstein–Hilbert action when the underlying spacetime manifold has a boundary.
In thermodynamics, the excess chemical potential is defined as the difference between the chemical potential of a given species and that of an ideal gas under the same conditions . The chemical potential of a particle species is therefore given by an ideal part and an excess part.
In nonideal fluid dynamics, the Hagen–Poiseuille equation, also known as the Hagen–Poiseuille law, Poiseuille law or Poiseuille equation, is a physical law that gives the pressure drop in an incompressible and Newtonian fluid in laminar flow flowing through a long cylindrical pipe of constant cross section. It can be successfully applied to air flow in lung alveoli, or the flow through a drinking straw or through a hypodermic needle. It was experimentally derived independently by Jean Léonard Marie Poiseuille in 1838 and Gotthilf Heinrich Ludwig Hagen, and published by Poiseuille in 1840–41 and 1846. The theoretical justification of the Poiseuille law was given by George Stokes in 1845.
In fracture mechanics, the energy release rate, , is the rate at which energy is transformed as a material undergoes fracture. Mathematically, the energy release rate is expressed as the decrease in total potential energy per increase in fracture surface area, and is thus expressed in terms of energy per unit area. Various energy balances can be constructed relating the energy released during fracture to the energy of the resulting new surface, as well as other dissipative processes such as plasticity and heat generation. The energy release rate is central to the field of fracture mechanics when solving problems and estimating material properties related to fracture and fatigue.
The Herschel–Bulkley fluid is a generalized model of a non-Newtonian fluid, in which the strain experienced by the fluid is related to the stress in a complicated, non-linear way. Three parameters characterize this relationship: the consistency k, the flow index n, and the yield shear stress . The consistency is a simple constant of proportionality, while the flow index measures the degree to which the fluid is shear-thinning or shear-thickening. Ordinary paint is one example of a shear-thinning fluid, while oobleck provides one realization of a shear-thickening fluid. Finally, the yield stress quantifies the amount of stress that the fluid may experience before it yields and begins to flow.

Diffusion is the net movement of anything generally from a region of higher concentration to a region of lower concentration. Diffusion is driven by a gradient in Gibbs free energy or chemical potential. It is possible to diffuse "uphill" from a region of lower concentration to a region of higher concentration, as in spinodal decomposition. Diffusion is a stochastic process due to the inherent randomness of the diffusing entity and can be used to model many real-life stochastic scenarios. Therefore, diffusion and the corresponding mathematical models are used in several fields beyond physics, such as statistics, probability theory, information theory, neural networks, finance, and marketing.
A central problem in algorithmic graph theory is the shortest path problem. One of the generalizations of the shortest path problem is known as the single-source-shortest-paths (SSSP) problem, which consists of finding the shortest paths from a source vertex to all other vertices in the graph. There are classical sequential algorithms which solve this problem, such as Dijkstra's algorithm. In this article, however, we present two parallel algorithms solving this problem.