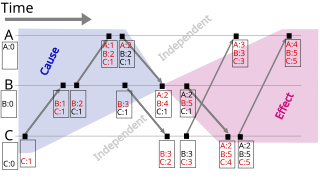
Algorithm used to determine the order of events in a distributed computer system
The Lamport timestamp algorithm is a simple logical clock algorithm used to determine the order of events in a distributed computer system. As different nodes or processes will typically not be perfectly synchronized, this algorithm is used to provide a partial ordering of events with minimal overhead, and conceptually provide a starting point for the more advanced vector clock method. The algorithm is named after its creator, Leslie Lamport.
Distributed algorithms such as resource synchronization often depend on some method of ordering events to function. For example, consider a system with two processes and a disk. The processes send messages to each other, and also send messages to the disk requesting access. The disk grants access in the order the messages were received. For example process sends a message to the disk requesting write access, and then sends a read instruction message to process . Process receives the message, and as a result sends its own read request message to the disk. If there is a timing delay causing the disk to receive both messages at the same time, it can determine which message happened-before the other: happens-before if one can get from to by a sequence of moves of two types: moving forward while remaining in the same process, and following a message from its sending to its reception. A logical clock algorithm provides a mechanism to determine facts about the order of such events. Note that if two events happen in different processes that do not exchange messages directly or indirectly via third-party processes, then we say that the two processes are concurrent, that is, nothing can be said about the ordering of the two events.[1]
Lamport invented a simple mechanism by which the happened-before ordering can be captured numerically. A Lamport logical clock is a numerical software counter value maintained in each process.
Conceptually, this logical clock can be thought of as a clock that only has meaning in relation to messages moving between processes. When a process receives a message, it re-synchronizes its logical clock with that sender. The above-mentioned vector clock is a generalization of the idea into the context of an arbitrary number of parallel, independent processes.
Algorithm
The algorithm follows some simple rules:
A process increments its counter before each local event (e.g., message sending event);
When a process sends a message, it includes its counter value with the message after executing step 1;
On receiving a message, the counter of the recipient is updated, if necessary, to the greater of its current counter and the timestamp in the received message. The counter is then incremented by 1 before the message is considered received.[2]
# event is known time = time + 1; # event happens send(message, time);
The algorithm for receiving a message is:
(message, time_stamp) = receive(); time = max(time_stamp, time) + 1;
Considerations
For every two different events and occurring in the same process, and being the timestamp for a certain event , it is necessary that never equals .
Therefore it is necessary that:
The logical clock be set so that there is a minimum of one clock "tick" (increment of the counter) between events and ;
In a multi-process or multi-threaded environment, it might be necessary to attach the process ID (PID) or any other unique ID to the timestamp so that it is possible to differentiate between events and which may occur simultaneously in different processes.
Causal ordering
For any two events, and , if there’s any way that could have influenced , then the Lamport timestamp of will be less than the Lamport timestamp of . It’s also possible to have two events where we can’t say which came first; when that happens, it means that they couldn’t have affected each other. If and can’t have any effect on each other, then it doesn’t matter which one came first.
Implications
A Lamport clock may be used to create a partial ordering of events between processes. Given a logical clock following these rules, the following relation is true: if then , where means happened-before.
This relation only goes one way, and is called the clock consistency condition: if one event comes before another, then that event's logical clock comes before the other's. The strong clock consistency condition, which is two way (if then ), can be obtained by other techniques such as vector clocks. Using only a simple Lamport clock, only a partial causal ordering can be inferred from the clock.
However, via the contrapositive, it's true that implies . So, for example, if then cannot have happened-before.
Another way of putting this is that means that may have happened-before, or be incomparable with in the happened-before ordering, but did not happen after .
Nevertheless, Lamport timestamps can be used to create a total ordering of events in a distributed system by using some arbitrary mechanism to break ties (e.g., the ID of the process). The caveat is that this ordering is artificial and cannot be depended on to imply a causal relationship.
Lamport's logical clock in distributed systems
In a distributed system, it is not possible in practice to synchronize time across entities (typically thought of as processes) within the system; hence, the entities can use the concept of a logical clock based on the events through which they communicate.
If two entities do not exchange any messages, then they probably do not need to share a common clock; events occurring on those entities are termed as concurrent events.
Among the processes on the same local machine we can order the events based on the local clock of the system.
When two entities communicate by message passing, then the send event is said to happen-before the receive event, and the logical order can be established among the events.
A distributed system is said to have partial order if we can have a partial order relationship among the events in the system. If 'totality', i.e., causal relationship among all events in the system, can be established, then the system is said to have total order.
A single entity cannot have two events occur simultaneously. If the system has total order we can determine the order among all events in the system. If the system has partial order between processes, which is the type of order Lamport's logical clock provides, then we can only tell the ordering between entities that interact. Lamport addressed ordering two events with the same timestamp (or counter): "To break ties, we use any arbitrary total ordering of the processes."[2] Thus two timestamps or counters may be the same within a distributed system, but in applying the logical clocks algorithm events that occur will always maintain at least a strict partial ordering.
Lamport clocks lead to a situation where all events in a distributed system are totally ordered. That is, if , then we can say actually happened before .
Note that with Lamport’s clocks, nothing can be said about the actual time of and . If the logical clock says , that does not mean in reality that actually happened before in terms of real time.
Lamport clocks show non-causality, but do not capture all causality. Knowing and shows did not cause or but we cannot say which initiated .
This kind of information can be important when trying to replay events in a distributed system (such as when trying to recover after a crash). If one node goes down, and we know the causal relationships between messages, then we can replay those messages and respect the causal relationship to get that node back up to the state it needs to be in.[3]
Alternatives to Potential Causality
The happened-before relation captures potential causality, not true causality. In 2011-12, Munindar Singh proposed a declarative, multiagent approach based on true causality called information protocols. An information protocol specifies the constraints on communications between the agents that constitute a distributed system.[4] However, instead of specifying message ordering (e.g., via a state machine, a common way of representing protocols in computing), an information protocol specifies the information dependencies between the communications that agents (the protocol's endpoints) may send. An agent may send a communication in a local state (its communication history) only if the communication and the state together satisfy the relevant information dependencies. For example, an information protocol for an e-commerce application may specify that to send a Quote with parameters ID (a uniquifier), item, and price, Seller must already know the ID and item from its state but can generate whatever price it wants. A remarkable thing about information protocols is that although emissions are constrained, receptions are not. Specifically, agents may receive communications in any order whatsoever -- receptions simply bring information and there is no point delaying them. This means that information protocols can be enacted over unordered communication services such as User Datagram Protocol.
The bigger idea is that of application semantics, the idea of designing distributed systems based on the content of the messages, an idea implicated in the end-to-end principle. Current approaches largely ignore semantics and focus on providing application-agnostic ("syntactic") message delivery and ordering guarantees in communication services, which is where ideas like potential causality help. But if we had a suitable way of doing application semantics, then we wouldn't need such communication services. An unordered, unreliable communication service would suffice. The real value of information protocols approach is that it provides the foundations for an application semantics approach.
Leslie B. Lamport is an American computer scientist and mathematician. Lamport is best known for his seminal work in distributed systems, and as the initial developer of the document preparation system LaTeX and the author of its first manual.
In computer science, communicating sequential processes (CSP) is a formal language for describing patterns of interaction in concurrent systems. It is a member of the family of mathematical theories of concurrency known as process algebras, or process calculi, based on message passing via channels. CSP was highly influential in the design of the occam programming language and also influenced the design of programming languages such as Limbo, RaftLib, Erlang, Go, Crystal, and Clojure's core.async.
In computer science, the happened-before relation is a relation between the result of two events, such that if one event should happen before another event, the result must reflect that, even if those events are in reality executed out of order. This involves ordering events based on the potential causal relationship of pairs of events in a concurrent system, especially asynchronous distributed systems. It was formulated by Leslie Lamport.
The Needham–Schroeder protocol is one of the two key transport protocols intended for use over an insecure network, both proposed by Roger Needham and Michael Schroeder. These are:
Clock synchronization is a topic in computer science and engineering that aims to coordinate otherwise independent clocks. Even when initially set accurately, real clocks will differ after some amount of time due to clock drift, caused by clocks counting time at slightly different rates. There are several problems that occur as a result of clock rate differences and several solutions, some being more acceptable than others in certain contexts.
A vector clock is a data structure used for determining the partial ordering of events in a distributed system and detecting causality violations. Just as in Lamport timestamps, inter-process messages contain the state of the sending process's logical clock. A vector clock of a system of N processes is an array/vector of N logical clocks, one clock per process; a local "largest possible values" copy of the global clock-array is kept in each process.
A logical clock is a mechanism for capturing chronological and causal relationships in a distributed system. Often, distributed systems may have no physically synchronous global clock. In many applications, if two processes never interact, the lack of synchronization is unobservable and in these applications it is enough for the processes to agree on the event ordering rather than the wall-clock time. The first logical clock implementation, the Lamport timestamps, was proposed by Leslie Lamport in 1978.
In distributed computing, the bully algorithm is a method for dynamically electing a coordinator or leader from a group of distributed computer processes. The process with the highest process ID number from amongst the non-failed processes is selected as the coordinator.
The Precision Time Protocol (PTP) is a protocol used to synchronize clocks throughout a computer network. On a local area network, it achieves clock accuracy in the sub-microsecond range, making it suitable for measurement and control systems. PTP is employed to synchronize financial transactions, mobile phone tower transmissions, sub-sea acoustic arrays, and networks that require precise timing but lack access to satellite navigation signals.
The Ricart–Agrawala algorithm is an algorithm for mutual exclusion on a distributed system. This algorithm is an extension and optimization of Lamport's Distributed Mutual Exclusion Algorithm, by removing the need for messages. It was developed by computer scientists Glenn Ricart and Ashok Agrawala.
Maekawa's algorithm is an algorithm for mutual exclusion on a distributed system. The basis of this algorithm is a quorum-like approach where any one site needs only to seek permissions from a subset of other sites.
Causal consistency is one of the major memory consistency models. In concurrent programming, where concurrent processes are accessing a shared memory, a consistency model restricts which accesses are legal. This is useful for defining correct data structures in distributed shared memory or distributed transactions.
A fundamental problem in distributed computing and multi-agent systems is to achieve overall system reliability in the presence of a number of faulty processes. This often requires coordinating processes to reach consensus, or agree on some data value that is needed during computation. Example applications of consensus include agreeing on what transactions to commit to a database in which order, state machine replication, and atomic broadcasts. Real-world applications often requiring consensus include cloud computing, clock synchronization, PageRank, opinion formation, smart power grids, state estimation, control of UAVs, load balancing, blockchain, and others.
In computer science, state machine replication (SMR) or state machine approach is a general method for implementing a fault-tolerant service by replicating servers and coordinating client interactions with server replicas. The approach also provides a framework for understanding and designing replication management protocols.
Paxos is a family of protocols for solving consensus in a network of unreliable or fallible processors. Consensus is the process of agreeing on one result among a group of participants. This problem becomes difficult when the participants or their communications may experience failures.
Operational transformation (OT) is a technology for supporting a range of collaboration functionalities in advanced collaborative software systems. OT was originally invented for consistency maintenance and concurrency control in collaborative editing of plain text documents. Its capabilities have been extended and its applications expanded to include group undo, locking, conflict resolution, operation notification and compression, group-awareness, HTML/XML and tree-structured document editing, collaborative office productivity tools, application-sharing, and collaborative computer-aided media design tools. In 2009 OT was adopted as a core technique behind the collaboration features in Apache Wave and Google Docs.
Byzantine fault tolerant protocols are algorithms that are robust to arbitrary types of failures in distributed algorithms. The Byzantine agreement protocol is an essential part of this task. The constant-time quantum version of the Byzantine protocol, is described below.
Event-driven SOA is a form of service-oriented architecture (SOA), combining the intelligence and proactiveness of event-driven architecture with the organizational capabilities found in service offerings. Before event-driven SOA, the typical SOA platform orchestrated services centrally, through pre-defined business processes, assuming that what should have already been triggered is defined in a business process. This older approach does not account for events that occur across, or outside of, specific business processes. Thus complex events, in which a pattern of activities—both non-scheduled and scheduled—should trigger a set of services is not accounted for in traditional SOA 1.0 architecture.
The Neuman–Stubblebine protocol is a computer network authentication protocol designed for use on insecure networks. It allows individuals communicating over such a network to prove their identity to each other. This protocol utilizes time stamps, but does not depend on synchronized clocks.
A version vector is a mechanism for tracking changes to data in a distributed system, where multiple agents might update the data at different times. The version vector allows the participants to determine if one update preceded another (happened-before), followed it, or if the two updates happened concurrently. In this way, version vectors enable causality tracking among data replicas and are a basic mechanism for optimistic replication. In mathematical terms, the version vector generates a preorder that tracks the events that precede, and may therefore influence, later updates.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.