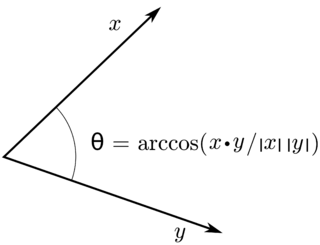
In mathematics, an inner product space is a real vector space or a complex vector space with an operation called an inner product. The inner product of two vectors in the space is a scalar, often denoted with angle brackets such as in . Inner products allow formal definitions of intuitive geometric notions, such as lengths, angles, and orthogonality of vectors. Inner product spaces generalize Euclidean vector spaces, in which the inner product is the dot product or scalar product of Cartesian coordinates. Inner product spaces of infinite dimension are widely used in functional analysis. Inner product spaces over the field of complex numbers are sometimes referred to as unitary spaces. The first usage of the concept of a vector space with an inner product is due to Giuseppe Peano, in 1898.
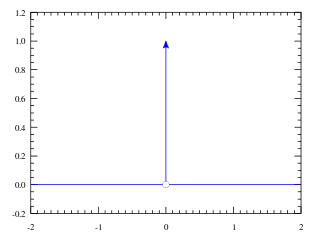
In mathematical analysis, the Dirac delta function, also known as the unit impulse, is a generalized function on the real numbers, whose value is zero everywhere except at zero, and whose integral over the entire real line is equal to one. Since there is no function having this property, to model the delta "function" rigorously involves the use of limits or, as is common in mathematics, measure theory and the theory of distributions.
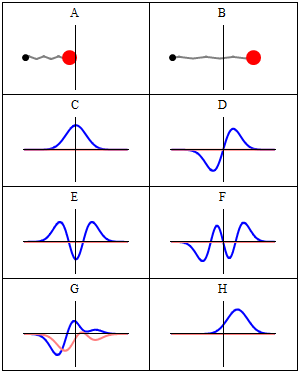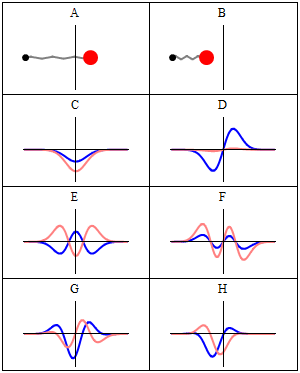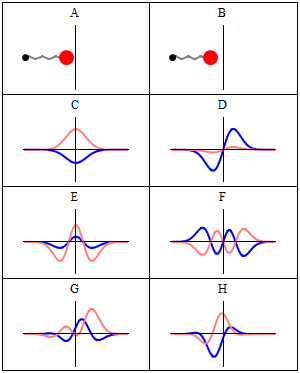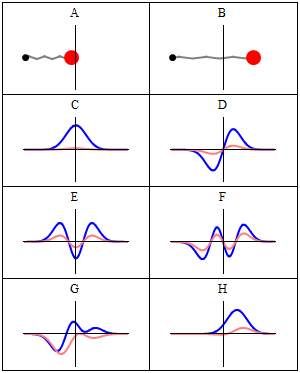
In quantum physics, a wave function is a mathematical description of the quantum state of an isolated quantum system. The most common symbols for a wave function are the Greek letters ψ and Ψ. Wave functions are complex-valued. For example, a wave function might assign a complex number to each point in a region of space. The Born rule provides the means to turn these complex probability amplitudes into actual probabilities. In one common form, it says that the squared modulus of a wave function that depends upon position is the probability density of measuring a particle as being at a given place. The integral of a wavefunction's squared modulus over all the system's degrees of freedom must be equal to 1, a condition called normalization. Since the wave function is complex-valued, only its relative phase and relative magnitude can be measured; its value does not, in isolation, tell anything about the magnitudes or directions of measurable observables. One has to apply quantum operators, whose eigenvalues correspond to sets of possible results of measurements, to the wave function ψ and calculate the statistical distributions for measurable quantities.
In mathematics, a linear form is a linear map from a vector space to its field of scalars.
In physics, an operator is a function over a space of physical states onto another space of physical states. The simplest example of the utility of operators is the study of symmetry. Because of this, they are useful tools in classical mechanics. Operators are even more important in quantum mechanics, where they form an intrinsic part of the formulation of the theory.
In mathematics, the Hodge star operator or Hodge star is a linear map defined on the exterior algebra of a finite-dimensional oriented vector space endowed with a nondegenerate symmetric bilinear form. Applying the operator to an element of the algebra produces the Hodge dual of the element. This map was introduced by W. V. D. Hodge.

In linear algebra and functional analysis, a projection is a linear transformation from a vector space to itself such that . That is, whenever is applied twice to any vector, it gives the same result as if it were applied once. It leaves its image unchanged. This definition of "projection" formalizes and generalizes the idea of graphical projection. One can also consider the effect of a projection on a geometrical object by examining the effect of the projection on points in the object.

In physics, the Rabi cycle is the cyclic behaviour of a two-level quantum system in the presence of an oscillatory driving field. A great variety of physical processes belonging to the areas of quantum computing, condensed matter, atomic and molecular physics, and nuclear and particle physics can be conveniently studied in terms of two-level quantum mechanical systems, and exhibit Rabi flopping when coupled to an optical driving field. The effect is important in quantum optics, magnetic resonance and quantum computing, and is named after Isidor Isaac Rabi.
In physics, the S-matrix or scattering matrix relates the initial state and the final state of a physical system undergoing a scattering process. It is used in quantum mechanics, scattering theory and quantum field theory (QFT).
The name paravector is used for the combination of a scalar and a vector in any Clifford algebra, known as geometric algebra among physicists.

In electromagnetism, charge density is the amount of electric charge per unit length, surface area, or volume. Volume charge density is the quantity of charge per unit volume, measured in the SI system in coulombs per cubic meter (C⋅m−3), at any point in a volume. Surface charge density (σ) is the quantity of charge per unit area, measured in coulombs per square meter (C⋅m−2), at any point on a surface charge distribution on a two dimensional surface. Linear charge density (λ) is the quantity of charge per unit length, measured in coulombs per meter (C⋅m−1), at any point on a line charge distribution. Charge density can be either positive or negative, since electric charge can be either positive or negative.
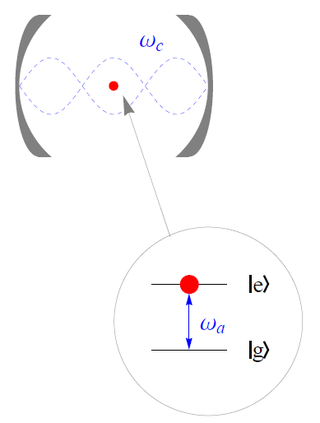
The Jaynes–Cummings model is a theoretical model in quantum optics. It describes the system of a two-level atom interacting with a quantized mode of an optical cavity, with or without the presence of light. It was originally developed to study the interaction of atoms with the quantized electromagnetic field in order to investigate the phenomena of spontaneous emission and absorption of photons in a cavity.
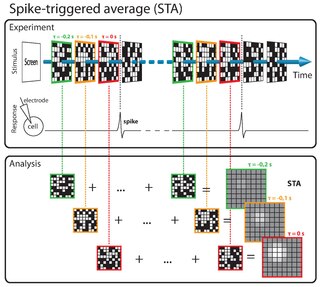
The spike-triggered averaging (STA) is a tool for characterizing the response properties of a neuron using the spikes emitted in response to a time-varying stimulus. The STA provides an estimate of a neuron's linear receptive field. It is a useful technique for the analysis of electrophysiological data.
In mathematics, a dissipative operator is a linear operator A defined on a linear subspace D(A) of Banach space X, taking values in X such that for all λ > 0 and all x ∈ D(A)
In mathematics, the Skorokhod integral, also named Hitsuda–Skorokhod integral, often denoted , is an operator of great importance in the theory of stochastic processes. It is named after the Ukrainian mathematician Anatoliy Skorokhod and Japanese mathematician Masuyuki Hitsuda. Part of its importance is that it unifies several concepts:
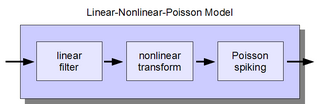
The linear-nonlinear-Poisson (LNP) cascade model is a simplified functional model of neural spike responses. It has been successfully used to describe the response characteristics of neurons in early sensory pathways, especially the visual system. The LNP model is generally implicit when using reverse correlation or the spike-triggered average to characterize neural responses with white-noise stimuli.
Entanglement distillation is the transformation of N copies of an arbitrary entangled state into some number of approximately pure Bell pairs, using only local operations and classical communication.
Spike-triggered covariance (STC) analysis is a tool for characterizing a neuron's response properties using the covariance of stimuli that elicit spikes from a neuron. STC is related to the spike-triggered average (STA), and provides a complementary tool for estimating linear filters in a linear-nonlinear-Poisson (LNP) cascade model. Unlike STA, the STC can be used to identify a multi-dimensional feature space in which a neuron computes its response.
In statistical mechanics, the mean squared displacement is a measure of the deviation of the position of a particle with respect to a reference position over time. It is the most common measure of the spatial extent of random motion, and can be thought of as measuring the portion of the system "explored" by the random walker. In the realm of biophysics and environmental engineering, the Mean Squared Displacement is measured over time to determine if a particle is spreading slowly due to diffusion, or if an advective force is also contributing. Another relevant concept, the variance-related diameter, is also used in studying the transportation and mixing phenomena in the realm of environmental engineering. It prominently appears in the Debye–Waller factor and in the Langevin equation.
In pure and applied mathematics, quantum mechanics and computer graphics, a tensor operator generalizes the notion of operators which are scalars and vectors. A special class of these are spherical tensor operators which apply the notion of the spherical basis and spherical harmonics. The spherical basis closely relates to the description of angular momentum in quantum mechanics and spherical harmonic functions. The coordinate-free generalization of a tensor operator is known as a representation operator.





















