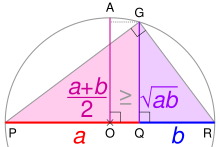
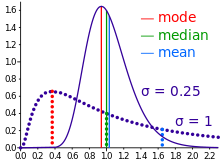
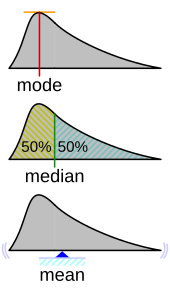
In mathematics and statistics, the arithmetic mean, arithmetic average, or just the mean or average is the sum of a collection of numbers divided by the count of numbers in the collection. The collection is often a set of results from an experiment, an observational study, or a survey. The term "arithmetic mean" is preferred in some mathematics and statistics contexts because it helps distinguish it from other types of means, such as geometric and harmonic.

The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.

In probability theory, the expected value is a generalization of the weighted average. Informally, the expected value is the arithmetic mean of the possible values a random variable can take, weighted by the probability of those outcomes. Since it is obtained through arithmetic, the expected value sometimes may not even be included in the sample data set; it is not the value you would "expect" to get in reality.

In mathematics, the geometric mean is a mean or average which indicates a central tendency of a finite set of real numbers by using the product of their values. The geometric mean is defined as the nth root of the product of n numbers, i.e., for a set of numbers a1, a2, ..., an, the geometric mean is defined as

In mathematics, generalized means are a family of functions for aggregating sets of numbers. These include as special cases the Pythagorean means.
In mathematics, the harmonic mean is one of several kinds of average, and in particular, one of the Pythagorean means. It is sometimes appropriate for situations when the average rate is desired.

In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In statistics, the standard deviation is a measure of the amount of variation of a random variable expected about its mean. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range. The standard deviation is commonly used in the determination of what constitutes an outlier and what does not.

In probability theory and statistics, variance is the expected value of the squared deviation from the mean of a random variable. The standard deviation (SD) is obtained as the square root of the variance. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. It is the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .
In probability theory, the central limit theorem (CLT) states that, under appropriate conditions, the distribution of a normalized version of the sample mean converges to a standard normal distribution. This holds even if the original variables themselves are not normally distributed. There are several versions of the CLT, each applying in the context of different conditions.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).

In probability theory and statistics, the chi-squared distribution with degrees of freedom is the distribution of a sum of the squares of independent standard normal random variables. The chi-squared distribution is a special case of the gamma distribution and is one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing and in construction of confidence intervals. This distribution is sometimes called the central chi-squared distribution, a special case of the more general noncentral chi-squared distribution.
In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the average of the results obtained from a large number of independent and identical random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
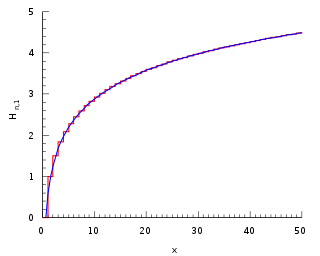
In mathematics, the n-th harmonic number is the sum of the reciprocals of the first n natural numbers:

In statistics, the Pearson correlation coefficient (PCC) is a correlation coefficient that measures linear correlation between two sets of data. It is the ratio between the covariance of two variables and the product of their standard deviations; thus, it is essentially a normalized measurement of the covariance, such that the result always has a value between −1 and 1. As with covariance itself, the measure can only reflect a linear correlation of variables, and ignores many other types of relationships or correlations. As a simple example, one would expect the age and height of a sample of teenagers from a high school to have a Pearson correlation coefficient significantly greater than 0, but less than 1.

In probability theory and statistics, the continuous uniform distributions or rectangular distributions are a family of symmetric probability distributions. Such a distribution describes an experiment where there is an arbitrary outcome that lies between certain bounds. The bounds are defined by the parameters, and which are the minimum and maximum values. The interval can either be closed or open. Therefore, the distribution is often abbreviated where stands for uniform distribution. The difference between the bounds defines the interval length; all intervals of the same length on the distribution's support are equally probable. It is the maximum entropy probability distribution for a random variable under no constraint other than that it is contained in the distribution's support.
In mathematics, a contraharmonic mean is a function complementary to the harmonic mean. The contraharmonic mean is a special case of the Lehmer mean, , where p = 2.
The sample mean or empirical mean, and the sample covariance or empirical covariance are statistics computed from a sample of data on one or more random variables.

A geometric progression, also known as a geometric sequence, is a mathematical sequence of non-zero numbers where each term after the first is found by multiplying the previous one by a fixed, non-zero number called the common ratio. For example, the sequence 2, 6, 18, 54, ... is a geometric progression with common ratio 3. Similarly 10, 5, 2.5, 1.25, ... is a geometric sequence with common ratio 1/2.