In probability theory and statistics, kurtosis is a measure of the "tailedness" of the probability distribution of a real-valued random variable. Like skewness, kurtosis describes a particular aspect of a probability distribution. There are different ways to quantify kurtosis for a theoretical distribution, and there are corresponding ways of estimating it using a sample from a population. Different measures of kurtosis may have different interpretations.
In probability theory and statistics, a central moment is a moment of a probability distribution of a random variable about the random variable's mean; that is, it is the expected value of a specified integer power of the deviation of the random variable from the mean. The various moments form one set of values by which the properties of a probability distribution can be usefully characterized. Central moments are used in preference to ordinary moments, computed in terms of deviations from the mean instead of from zero, because the higher-order central moments relate only to the spread and shape of the distribution, rather than also to its location.

In probability theory and statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In statistics, the standard deviation is a measure of the amount of variation of a random variable expected about its mean. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range. The standard deviation is commonly used in the determination of what constitutes an outlier and what does not.

In probability theory and statistics, variance is the expected value of the squared deviation from the mean of a random variable. The standard deviation (SD) is obtained as the square root of the variance. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. It is the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables, each of which clusters around a mean value.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
In probability theory, Chebyshev's inequality provides an upper bound on the probability of deviation of a random variable from its mean. More specifically, the probability that a random variable deviates from its mean by more than is at most , where is any positive constant and is the standard deviation.

In probability theory and statistics, the Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli, is the discrete probability distribution of a random variable which takes the value 1 with probability and the value 0 with probability . Less formally, it can be thought of as a model for the set of possible outcomes of any single experiment that asks a yes–no question. Such questions lead to outcomes that are Boolean-valued: a single bit whose value is success/yes/true/one with probability p and failure/no/false/zero with probability q. It can be used to represent a coin toss where 1 and 0 would represent "heads" and "tails", respectively, and p would be the probability of the coin landing on heads. In particular, unfair coins would have
In statistics, the mean squared error (MSE) or mean squared deviation (MSD) of an estimator measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss. The fact that MSE is almost always strictly positive is because of randomness or because the estimator does not account for information that could produce a more accurate estimate. In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk, as an estimate of the true MSE.

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
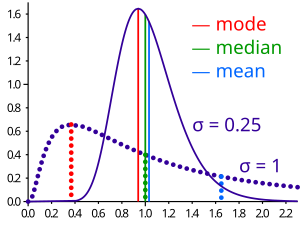
In mathematics, the moments of a function are certain quantitative measures related to the shape of the function's graph. If the function represents mass density, then the zeroth moment is the total mass, the first moment is the center of mass, and the second moment is the moment of inertia. If the function is a probability distribution, then the first moment is the expected value, the second central moment is the variance, the third standardized moment is the skewness, and the fourth standardized moment is the kurtosis. The mathematical concept is closely related to the concept of moment in physics.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.

The Pearson distribution is a family of continuous probability distributions. It was first published by Karl Pearson in 1895 and subsequently extended by him in 1901 and 1916 in a series of articles on biostatistics.
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: consistent estimators converge in probability to the true value of the parameter, but may be biased or unbiased; see bias versus consistency for more.
In statistics, D'Agostino's K2 test, named for Ralph D'Agostino, is a goodness-of-fit measure of departure from normality, that is the test aims to gauge the compatibility of given data with the null hypothesis that the data is a realization of independent, identically distributed Gaussian random variables. The test is based on transformations of the sample kurtosis and skewness, and has power only against the alternatives that the distribution is skewed and/or kurtic.
In statistics, the Jarque–Bera test is a goodness-of-fit test of whether sample data have the skewness and kurtosis matching a normal distribution. The test is named after Carlos Jarque and Anil K. Bera. The test statistic is always nonnegative. If it is far from zero, it signals the data do not have a normal distribution.
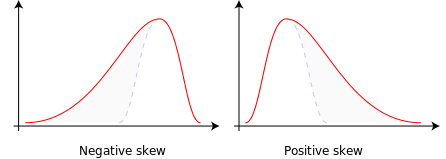
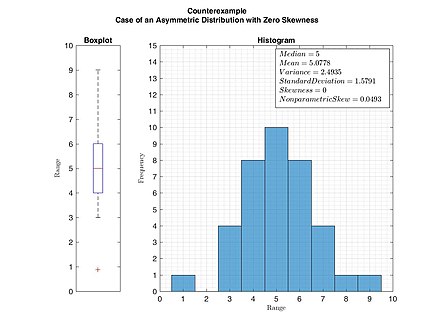
In statistics and probability theory, the nonparametric skew is a statistic occasionally used with random variables that take real values. It is a measure of the skewness of a random variable's distribution—that is, the distribution's tendency to "lean" to one side or the other of the mean. Its calculation does not require any knowledge of the form of the underlying distribution—hence the name nonparametric. It has some desirable properties: it is zero for any symmetric distribution; it is unaffected by a scale shift; and it reveals either left- or right-skewness equally well. In some statistical samples it has been shown to be less powerful than the usual measures of skewness in detecting departures of the population from normality.

In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.
In probability and statistics, the skewed generalized "t" distribution is a family of continuous probability distributions. The distribution was first introduced by Panayiotis Theodossiou in 1998. The distribution has since been used in different applications. There are different parameterizations for the skewed generalized t distribution.