In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.
In statistics, the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero. The errors do not need to be normal for the theorem to apply, nor do they need to be independent and identically distributed.

In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.

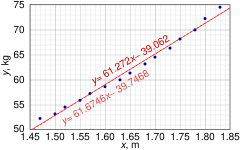
In statistics, Deming regression, named after W. Edwards Deming, is an errors-in-variables model that tries to find the line of best fit for a two-dimensional data set. It differs from the simple linear regression in that it accounts for errors in observations on both the x- and the y- axis. It is a special case of total least squares, which allows for any number of predictors and a more complicated error structure.
In statistics, a studentized residual is the dimensionless ratio resulting from the division of a residual by an estimate of its standard deviation, both expressed in the same units. It is a form of a Student's t-statistic, with the estimate of error varying between points.

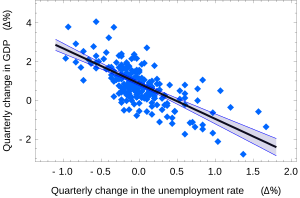
In statistical modeling, regression analysis is a set of statistical processes for estimating the relationships between a dependent variable and one or more independent variables. The most common form of regression analysis is linear regression, in which one finds the line that most closely fits the data according to a specific mathematical criterion. For example, the method of ordinary least squares computes the unique line that minimizes the sum of squared differences between the true data and that line. For specific mathematical reasons, this allows the researcher to estimate the conditional expectation of the dependent variable when the independent variables take on a given set of values. Less common forms of regression use slightly different procedures to estimate alternative location parameters or estimate the conditional expectation across a broader collection of non-linear models.

In statistics, the coefficient of determination, denoted R2 or r2 and pronounced "R squared", is the proportion of the variation in the dependent variable that is predictable from the independent variable(s).
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable. Some sources consider OLS to be linear regression.
In statistics, the residual sum of squares (RSS), also known as the sum of squared residuals (SSR) or the sum of squared estimate of errors (SSE), is the sum of the squares of residuals. It is a measure of the discrepancy between the data and an estimation model, such as a linear regression. A small RSS indicates a tight fit of the model to the data. It is used as an optimality criterion in parameter selection and model selection.
Difference in differences is a statistical technique used in econometrics and quantitative research in the social sciences that attempts to mimic an experimental research design using observational study data, by studying the differential effect of a treatment on a 'treatment group' versus a 'control group' in a natural experiment. It calculates the effect of a treatment on an outcome by comparing the average change over time in the outcome variable for the treatment group to the average change over time for the control group. Although it is intended to mitigate the effects of extraneous factors and selection bias, depending on how the treatment group is chosen, this method may still be subject to certain biases.
In statistics, a fixed effects model is a statistical model in which the model parameters are fixed or non-random quantities. This is in contrast to random effects models and mixed models in which all or some of the model parameters are random variables. In many applications including econometrics and biostatistics a fixed effects model refers to a regression model in which the group means are fixed (non-random) as opposed to a random effects model in which the group means are a random sample from a population. Generally, data can be grouped according to several observed factors. The group means could be modeled as fixed or random effects for each grouping. In a fixed effects model each group mean is a group-specific fixed quantity.
In statistics, generalized least squares (GLS) is a method used to estimate the unknown parameters in a linear regression model. It is used when there is a non-zero amount of correlation between the residuals in the regression model. GLS is employed to improve statistical efficiency and reduce the risk of drawing erroneous inferences, as compared to conventional least squares and weighted least squares methods. It was first described by Alexander Aitken in 1935.
The topic of heteroskedasticity-consistent (HC) standard errors arises in statistics and econometrics in the context of linear regression and time series analysis. These are also known as heteroskedasticity-robust standard errors, Eicker–Huber–White standard errors, to recognize the contributions of Friedhelm Eicker, Peter J. Huber, and Halbert White.
In statistics, the variance inflation factor (VIF) is the ratio (quotient) of the variance of a parameter estimate when fitting a full model that includes other parameters to the variance of the parameter estimate if the model is fit with only the parameter on its own. The VIF provides an index that measures how much the variance of an estimated regression coefficient is increased because of collinearity.
In regression, mean response and predicted response, also known as mean outcome and predicted outcome, are values of the dependent variable calculated from the regression parameters and a given value of the independent variable. The values of these two responses are the same, but their calculated variances are different. The concept is a generalization of the distinction between the standard error of the mean and the sample standard deviation.
In statistics, a sum of squares due to lack of fit, or more tersely a lack-of-fit sum of squares, is one of the components of a partition of the sum of squares of residuals in an analysis of variance, used in the numerator in an F-test of the null hypothesis that says that a proposed model fits well. The other component is the pure-error sum of squares.
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression.
The purpose of this page is to provide supplementary materials for the ordinary least squares article, reducing the load of the main article with mathematics and improving its accessibility, while at the same time retaining the completeness of exposition.

In statistics, errors-in-variables models or measurement error models are regression models that account for measurement errors in the independent variables. In contrast, standard regression models assume that those regressors have been measured exactly, or observed without error; as such, those models account only for errors in the dependent variables, or responses.
In statistics, particularly regression analysis, the Working–Hotelling procedure, named after Holbrook Working and Harold Hotelling, is a method of simultaneous estimation in linear regression models. One of the first developments in simultaneous inference, it was devised by Working and Hotelling for the simple linear regression model in 1929. It provides a confidence region for multiple mean responses, that is, it gives the upper and lower bounds of more than one value of a dependent variable at several levels of the independent variables at a certain confidence level. The resulting confidence bands are known as the Working–Hotelling–Scheffé confidence bands.