
The method of least squares is a parameter estimation method in regression analysis based on minimizing the sum of the squares of the residuals made in the results of each individual equation.
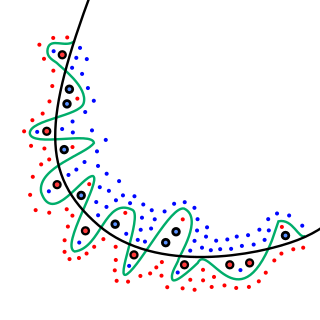
In mathematical modeling, overfitting is "the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit to additional data or predict future observations reliably". An overfitted model is a mathematical model that contains more parameters than can be justified by the data. In a mathematical sense, these parameters represent the degree of a polynomial. The essence of overfitting is to have unknowingly extracted some of the residual variation as if that variation represented underlying model structure.

Cross-validation, sometimes called rotation estimation or out-of-sample testing, is any of various similar model validation techniques for assessing how the results of a statistical analysis will generalize to an independent data set. Cross-validation includes resampling and sample splitting methods that use different portions of the data to test and train a model on different iterations. It is often used in settings where the goal is prediction, and one wants to estimate how accurately a predictive model will perform in practice. It can also be used to assess the quality of a fitted model and the stability of its parameters.

A variable is considered dependent if it depends on an independent variable. Dependent variables are studied under the supposition or demand that they depend, by some law or rule, on the values of other variables. Independent variables, in turn, are not seen as depending on any other variable in the scope of the experiment in question. In this sense, some common independent variables are time, space, density, mass, fluid flow rate, and previous values of some observed value of interest to predict future values.

In statistical modeling, regression analysis is a set of statistical processes for estimating the relationships between a dependent variable and one or more independent variables. The most common form of regression analysis is linear regression, in which one finds the line that most closely fits the data according to a specific mathematical criterion. For example, the method of ordinary least squares computes the unique line that minimizes the sum of squared differences between the true data and that line. For specific mathematical reasons, this allows the researcher to estimate the conditional expectation of the dependent variable when the independent variables take on a given set of values. Less common forms of regression use slightly different procedures to estimate alternative location parameters or estimate the conditional expectation across a broader collection of non-linear models.

In statistics, the coefficient of determination, denoted R2 or r2 and pronounced "R squared", is the proportion of the variation in the dependent variable that is predictable from the independent variable(s).
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the input dataset and the output of the (linear) function of the independent variable.
In robust statistics, robust regression seeks to overcome some limitations of traditional regression analysis. A regression analysis models the relationship between one or more independent variables and a dependent variable. Standard types of regression, such as ordinary least squares, have favourable properties if their underlying assumptions are true, but can give misleading results otherwise. Robust regression methods are designed to limit the effect that violations of assumptions by the underlying data-generating process have on regression estimates.
In statistics, resampling is the creation of new samples based on one observed sample. Resampling methods are:
- Permutation tests
- Bootstrapping
- Cross validation
- Jackknife
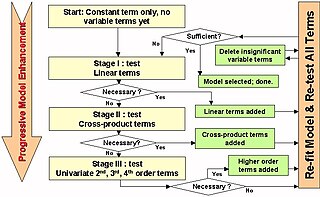
In statistics, stepwise regression is a method of fitting regression models in which the choice of predictive variables is carried out by an automatic procedure. In each step, a variable is considered for addition to or subtraction from the set of explanatory variables based on some prespecified criterion. Usually, this takes the form of a forward, backward, or combined sequence of F-tests or t-tests.
In statistics, Mallows's, named for Colin Lingwood Mallows, is used to assess the fit of a regression model that has been estimated using ordinary least squares. It is applied in the context of model selection, where a number of predictor variables are available for predicting some outcome, and the goal is to find the best model involving a subset of these predictors. A small value of means that the model is relatively precise.
In statistics, the fraction of variance unexplained (FVU) in the context of a regression task is the fraction of variance of the regressand Y which cannot be explained, i.e., which is not correctly predicted, by the explanatory variables X.

A plot is a graphical technique for representing a data set, usually as a graph showing the relationship between two or more variables. The plot can be drawn by hand or by a computer. In the past, sometimes mechanical or electronic plotters were used. Graphs are a visual representation of the relationship between variables, which are very useful for humans who can then quickly derive an understanding which may not have come from lists of values. Given a scale or ruler, graphs can also be used to read off the value of an unknown variable plotted as a function of a known one, but this can also be done with data presented in tabular form. Graphs of functions are used in mathematics, sciences, engineering, technology, finance, and other areas.
The following outline is provided as an overview of and topical guide to regression analysis:
In statistics, model validation is the task of evaluating whether a chosen statistical model is appropriate or not. Oftentimes in statistical inference, inferences from models that appear to fit their data may be flukes, resulting in a misunderstanding by researchers of the actual relevance of their model. To combat this, model validation is used to test whether a statistical model can hold up to permutations in the data. This topic is not to be confused with the closely related task of model selection, the process of discriminating between multiple candidate models: model validation does not concern so much the conceptual design of models as it tests only the consistency between a chosen model and its stated outputs.
In statistics, a regression diagnostic is one of a set of procedures available for regression analysis that seek to assess the validity of a model in any of a number of different ways. This assessment may be an exploration of the model's underlying statistical assumptions, an examination of the structure of the model by considering formulations that have fewer, more or different explanatory variables, or a study of subgroups of observations, looking for those that are either poorly represented by the model (outliers) or that have a relatively large effect on the regression model's predictions.
In statistics, the predicted residual error sum of squares (PRESS) is a form of cross-validation used in regression analysis to provide a summary measure of the fit of a model to a sample of observations that were not themselves used to estimate the model. It is calculated as the sums of squares of the prediction residuals for those observations.

JASP is a free and open-source program for statistical analysis supported by the University of Amsterdam. It is designed to be easy to use, and familiar to users of SPSS. It offers standard analysis procedures in both their classical and Bayesian form. JASP generally produces APA style results tables and plots to ease publication. It promotes open science via integration with the Open Science Framework and reproducibility by integrating the analysis settings into the results. The development of JASP is financially supported by several universities and research funds. As the JASP GUI is developed in C++ using Qt framework, some of the team left to make a notable fork which is Jamovi which has its GUI developed in JavaScript and HTML5.
In statistics, linear regression is a statistical model which estimates the linear relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable. If the explanatory variables are measured with error then errors-in-variables models are required, also known as measurement error models.

