
The travelling salesman problem (TSP) asks the following question: "Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?" It is an NP-hard problem in combinatorial optimization, important in theoretical computer science and operations research.
The bin packing problem is an optimization problem, in which items of different sizes must be packed into a finite number of bins or containers, each of a fixed given capacity, in a way that minimizes the number of bins used. The problem has many applications, such as filling up containers, loading trucks with weight capacity constraints, creating file backups in media, and technology mapping in FPGA semiconductor chip design.

In graph theory, graph coloring is a special case of graph labeling; it is an assignment of labels traditionally called "colors" to elements of a graph subject to certain constraints. In its simplest form, it is a way of coloring the vertices of a graph such that no two adjacent vertices are of the same color; this is called a vertex coloring. Similarly, an edge coloring assigns a color to each edge so that no two adjacent edges are of the same color, and a face coloring of a planar graph assigns a color to each face or region so that no two faces that share a boundary have the same color.
In computer science and operations research, approximation algorithms are efficient algorithms that find approximate solutions to optimization problems with provable guarantees on the distance of the returned solution to the optimal one. Approximation algorithms naturally arise in the field of theoretical computer science as a consequence of the widely believed P ≠ NP conjecture. Under this conjecture, a wide class of optimization problems cannot be solved exactly in polynomial time. The field of approximation algorithms, therefore, tries to understand how closely it is possible to approximate optimal solutions to such problems in polynomial time. In an overwhelming majority of the cases, the guarantee of such algorithms is a multiplicative one expressed as an approximation ratio or approximation factor i.e., the optimal solution is always guaranteed to be within a (predetermined) multiplicative factor of the returned solution. However, there are also many approximation algorithms that provide an additive guarantee on the quality of the returned solution. A notable example of an approximation algorithm that provides both is the classic approximation algorithm of Lenstra, Shmoys and Tardos for scheduling on unrelated parallel machines.
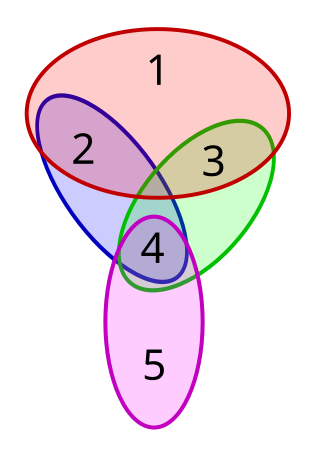
The set cover problem is a classical question in combinatorics, computer science, operations research, and complexity theory.
Convex optimization is a subfield of mathematical optimization that studies the problem of minimizing convex functions over convex sets. Many classes of convex optimization problems admit polynomial-time algorithms, whereas mathematical optimization is in general NP-hard.
In graph theory, the metric dimension of a graph G is the minimum cardinality of a subset S of vertices such that all other vertices are uniquely determined by their distances to the vertices in S. Finding the metric dimension of a graph is an NP-hard problem; the decision version, determining whether the metric dimension is less than a given value, is NP-complete.
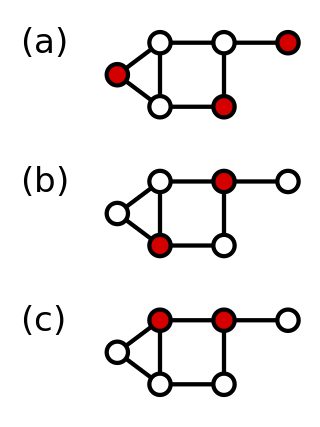
In graph theory, a dominating set for a graph G is a subset D of its vertices, such that any vertex of G is either in D, or has a neighbor in D. The domination numberγ(G) is the number of vertices in a smallest dominating set for G.
Set packing is a classical NP-complete problem in computational complexity theory and combinatorics, and was one of Karp's 21 NP-complete problems. Suppose one has a finite set S and a list of subsets of S. Then, the set packing problem asks if some k subsets in the list are pairwise disjoint.
The Frank–Wolfe algorithm is an iterative first-order optimization algorithm for constrained convex optimization. Also known as the conditional gradient method, reduced gradient algorithm and the convex combination algorithm, the method was originally proposed by Marguerite Frank and Philip Wolfe in 1956. In each iteration, the Frank–Wolfe algorithm considers a linear approximation of the objective function, and moves towards a minimizer of this linear function.
The study of facility location problems (FLP), also known as location analysis, is a branch of operations research and computational geometry concerned with the optimal placement of facilities to minimize transportation costs while considering factors like avoiding placing hazardous materials near housing, and competitors' facilities. The techniques also apply to cluster analysis.
In computer science, locality-sensitive hashing (LSH) is a fuzzy hashing technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
In mathematics, a submodular set function is a set function that, informally, describes the relationship between a set of inputs and an output, where adding more of one input has a decreasing additional benefit. The natural diminishing returns property which makes them suitable for many applications, including approximation algorithms, game theory and electrical networks. Recently, submodular functions have also found utility in several real world problems in machine learning and artificial intelligence, including automatic summarization, multi-document summarization, feature selection, active learning, sensor placement, image collection summarization and many other domains.
The geometric set cover problem is the special case of the set cover problem in geometric settings. The input is a range space where is a universe of points in and is a family of subsets of called ranges, defined by the intersection of and geometric shapes such as disks and axis-parallel rectangles. The goal is to select a minimum-size subset of ranges such that every point in the universe is covered by some range in .
The vertex k-center problem is a classical NP-hard problem in computer science. It has application in facility location and clustering. Basically, the vertex k-center problem models the following real problem: given a city with facilities, find the best facilities where to build fire stations. Since firemen must attend any emergency as quickly as possible, the distance from the farthest facility to its nearest fire station has to be as small as possible. In other words, the position of the fire stations must be such that every possible fire is attended as quickly as possible.
The strip packing problem is a 2-dimensional geometric minimization problem. Given a set of axis-aligned rectangles and a strip of bounded width and infinite height, determine an overlapping-free packing of the rectangles into the strip minimizing its height. This problem is a cutting and packing problem and is classified as an Open Dimension Problem according to Wäscher et al.
A central problem in algorithmic graph theory is the shortest path problem. One of the generalizations of the shortest path problem is known as the single-source-shortest-paths (SSSP) problem, which consists of finding the shortest paths from a source vertex to all other vertices in the graph. There are classical sequential algorithms which solve this problem, such as Dijkstra's algorithm. In this article, however, we present two parallel algorithms solving this problem.
In statistics and machine learning, Gaussian process approximation is a computational method that accelerates inference tasks in the context of a Gaussian process model, most commonly likelihood evaluation and prediction. Like approximations of other models, they can often be expressed as additional assumptions imposed on the model, which do not correspond to any actual feature, but which retain its key properties while simplifying calculations. Many of these approximation methods can be expressed in purely linear algebraic or functional analytic terms as matrix or function approximations. Others are purely algorithmic and cannot easily be rephrased as a modification of a statistical model.
In computer science, multiway number partitioning is the problem of partitioning a multiset of numbers into a fixed number of subsets, such that the sums of the subsets are as similar as possible. It was first presented by Ronald Graham in 1969 in the context of the identical-machines scheduling problem. The problem is parametrized by a positive integer k, and called k-way number partitioning. The input to the problem is a multiset S of numbers, whose sum is k*T.
The highway dimension is a graph parameter modelling transportation networks, such as road networks or public transportation networks. It was first formally defined by Abraham et al. based on the observation by Bast et al. that any road network has a sparse set of "transit nodes", such that driving from a point A to a sufficiently far away point B along the shortest route will always pass through one of these transit nodes. It has also been proposed that the highway dimension captures the properties of public transportation networks well, given that longer routes using busses, trains, or airplanes will typically be serviced by larger transit hubs. This relates to the spoke–hub distribution paradigm in transport topology optimization.

































