A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a sensor model (the probability distribution of different observations given the underlying state) and the underlying MDP. Unlike the policy function in MDP which maps the underlying states to the actions, POMDP's policy is a mapping from the history of observations (or belief states) to the actions.
The POMDP framework is general enough to model a variety of real-world sequential decision processes. Applications include robot navigation problems, machine maintenance, and planning under uncertainty in general. The general framework of Markov decision processes with imperfect information was described by Karl Johan Åström in 1965[1] in the case of a discrete state space, and it was further studied in the operations research community where the acronym POMDP was coined. It was later adapted for problems in artificial intelligence and automated planning by Leslie P. Kaelbling and Michael L. Littman.[2]
An exact solution to a POMDP yields the optimal action for each possible belief over the world states. The optimal action maximizes the expected reward (or minimizes the cost) of the agent over a possibly infinite horizon. The sequence of optimal actions is known as the optimal policy of the agent for interacting with its environment.
Definition
Formal definition
A discrete-time POMDP models the relationship between an agent and its environment. Formally, a POMDP is a 7-tuple , where
is a set of states,
is a set of actions,
is a set of conditional transition probabilities between states,
is the reward function.
is a set of observations,
is a set of conditional observation probabilities, and
is the discount factor.
At each time period, the environment is in some state . The agent takes an action , which causes the environment to transition to state with probability . At the same time, the agent receives an observation which depends on the new state of the environment, , and on the just taken action, , with probability (or sometimes depending on the sensor model). Finally, the agent receives a reward equal to . Then the process repeats. The goal is for the agent to choose actions at each time step that maximize its expected future discounted reward: , where is the reward earned at time . The discount factor determines how much immediate rewards are favored over more distant rewards. When the agent only cares about which action will yield the largest expected immediate reward; when the agent cares about maximizing the expected sum of future rewards.
Discussion
Because the agent does not directly observe the environment's state, the agent must make decisions under uncertainty of the true environment state. However, by interacting with the environment and receiving observations, the agent may update its belief in the true state by updating the probability distribution of the current state. A consequence of this property is that the optimal behavior may often include (information gathering) actions that are taken purely because they improve the agent's estimate of the current state, thereby allowing it to make better decisions in the future.
It is instructive to compare the above definition with the definition of a Markov decision process. An MDP does not include the observation set, because the agent always knows with certainty the environment's current state. Alternatively, an MDP can be reformulated as a POMDP by setting the observation set to be equal to the set of states and defining the observation conditional probabilities to deterministically select the observation that corresponds to the true state.
Belief update
After having taken the action and observing , an agent needs to update its belief in the state the environment may (or not) be in. Since the state is Markovian (by assumption), maintaining a belief over the states solely requires knowledge of the previous belief state, the action taken, and the current observation. The operation is denoted . Below we describe how this belief update is computed.
After reaching , the agent observes with probability . Let be a probability distribution over the state space . denotes the probability that the environment is in state . Given , then after taking action and observing ,
where is a normalizing constant with .
Belief MDP
A Markovian belief state allows a POMDP to be formulated as a Markov decision process where every belief is a state. The resulting belief MDP will thus be defined on a continuous state space (even if the "originating" POMDP has a finite number of states: there are infinite belief states (in ) because there are an infinite number of probability distributions over the states (of )).[2]
Formally, the belief MDP is defined as a tuple where
is the set of belief states over the POMDP states,
is the same finite set of action as for the original POMDP,
is the belief state transition function,
is the reward function on belief states,
is the discount factor equal to the in the original POMDP.
Of these, and need to be derived from the original POMDP. is
where is the value derived in the previous section and
The belief MDP reward function () is the expected reward from the POMDP reward function over the belief state distribution:
.
The belief MDP is not partially observable anymore, since at any given time the agent knows its belief, and by extension the state of the belief MDP.
Policy and value function
Unlike the "originating" POMDP (where each action is available from only one state), in the corresponding Belief MDP all belief states allow all actions, since you (almost) always have some probability of believing you are in any (originating) state. As such, specifies an action for any belief .
Here it is assumed the objective is to maximize the expected total discounted reward over an infinite horizon. When defines a cost, the objective becomes the minimization of the expected cost.
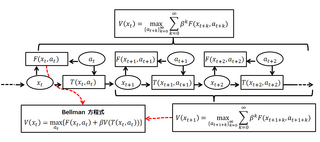
The expected reward for policy starting from belief is defined as
where is the discount factor. The optimal policy is obtained by optimizing the long-term reward.
where is the initial belief.
The optimal policy, denoted by , yields the highest expected reward value for each belief state, compactly represented by the optimal value function . This value function is solution to the Bellman optimality equation:
For finite-horizon POMDPs, the optimal value function is piecewise-linear and convex.[3] It can be represented as a finite set of vectors. In the infinite-horizon formulation, a finite vector set can approximate arbitrarily closely, whose shape remains convex. Value iteration applies dynamic programming update to gradually improve on the value until convergence to an -optimal value function, and preserves its piecewise linearity and convexity.[4] By improving the value, the policy is implicitly improved. Another dynamic programming technique called policy iteration explicitly represents and improves the policy instead.[5][6]
Approximate POMDP solutions
In practice, POMDPs are often computationally intractable to solve exactly. This intractability is often due to the curse of dimensionality or the curse of history (the fact that optimal policies may depend on the entire history of actions and observations). To address these issues, computer scientists have developed methods that approximate solutions for POMDPs. These solutions typically attempt to approximate the problem or solution with a limited number of parameters,[7] plan only over a small part of the belief space online, or summarize the action-observation history compactly.
Grid-based algorithms[8] comprise one approximate solution technique. In this approach, the value function is computed for a set of points in the belief space, and interpolation is used to determine the optimal action to take for other belief states that are encountered which are not in the set of grid points. More recent work makes use of sampling techniques, generalization techniques and exploitation of problem structure, and has extended POMDP solving into large domains with millions of states.[9][10] For example, adaptive grids and point-based methods sample random reachable belief points to constrain the planning to relevant areas in the belief space.[11][12] Dimensionality reduction using PCA has also been explored.[13]
Online planning algorithms approach large POMDPs by constructing a new policy for the current belief each time a new observation is received. Such a policy only needs to consider future beliefs reachable from the current belief, which is often only a very small part of the full belief space. This family includes variants of Monte Carlo tree search[14] and heuristic search.[15] Similar to MDPs, it is possible to construct online algorithms that find arbitrarily near-optimal policies and have no direct computational complexity dependence on the size of the state and observation spaces.[16]
Another line of approximate solution techniques for solving POMDPs relies on using (a subset of) the history of previous observations, actions and rewards up to the current time step as a pseudo-state. Usual techniques for solving MDPs based on these pseudo-states can then be used (e.g. Q-learning). Ideally the pseudo-states should contain the most important information from the whole history (to reduce bias) while being as compressed as possible (to reduce overfitting).[17]
POMDP theory
Planning in POMDP is undecidable in general. However, some settings have been identified to be decidable (see Table 2 in,[18] reproduced below). Different objectives have been considered. Büchi objectives are defined by Büchi automata. Reachability is an example of a Büchi condition (for instance, reaching a good state in which all robots are home). coBüchi objectives correspond to traces that do not satisfy a given Büchi condition (for instance, not reaching a bad state in which some robot died). Parity objectives are defined via parity games; they enable to define complex objectives such that reaching a good state every 10 timesteps. The objective can be satisfied:
almost-surely, that is the probability to satisfy the objective is 1;
positive, that is the probability to satisfy the objective is strictly greater than 0;
quantitative, that is the probability to satisfy the objective is greater than a given threshold.
We also consider the finite memory case in which the agent is a finite-state machine, and the general case in which the agent has an infinite memory.
POMDPs can be used to model many kinds of real-world problems. Notable applications include the use of a POMDP in management of patients with ischemic heart disease,[19] assistive technology for persons with dementia,[9][10] the conservation of the critically endangered and difficult to detect Sumatran tigers[20] and aircraft collision avoidance.[21]
One application is a teaching case, a crying baby problem, where a parent needs to sequentially decide whether to feed the baby based on the observation of whether the baby is crying or not, which is an imperfect representation of the actual baby's state of hunger.[22][23]
Related Research Articles
Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize the cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
In electrical engineering, statistical computing and bioinformatics, the Baum–Welch algorithm is a special case of the expectation–maximization algorithm used to find the unknown parameters of a hidden Markov model (HMM). It makes use of the forward-backward algorithm to compute the statistics for the expectation step.
A continuous-time Markov chain (CTMC) is a continuous stochastic process in which, for each state, the process will change state according to an exponential random variable and then move to a different state as specified by the probabilities of a stochastic matrix. An equivalent formulation describes the process as changing state according to the least value of a set of exponential random variables, one for each possible state it can move to, with the parameters determined by the current state.
In mathematics, a Markov decision process (MDP) is a discrete-time stochastic control process. It provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying optimization problems solved via dynamic programming. MDPs were known at least as early as the 1950s; a core body of research on Markov decision processes resulted from Ronald Howard's 1960 book, Dynamic Programming and Markov Processes. They are used in many disciplines, including robotics, automatic control, economics and manufacturing. The name of MDPs comes from the Russian mathematician Andrey Markov as they are an extension of Markov chains.
Temporal difference (TD) learning refers to a class of model-free reinforcement learning methods which learn by bootstrapping from the current estimate of the value function. These methods sample from the environment, like Monte Carlo methods, and perform updates based on current estimates, like dynamic programming methods.
A Bellman equation, named after Richard E. Bellman, is a necessary condition for optimality associated with the mathematical optimization method known as dynamic programming. It writes the "value" of a decision problem at a certain point in time in terms of the payoff from some initial choices and the "value" of the remaining decision problem that results from those initial choices. This breaks a dynamic optimization problem into a sequence of simpler subproblems, as Bellman's “principle of optimality" prescribes. The equation applies to algebraic structures with a total ordering; for algebraic structures with a partial ordering, the generic Bellman's equation can be used.
Q-learning is a model-free reinforcement learning algorithm to learn the value of an action in a particular state. It does not require a model of the environment, and it can handle problems with stochastic transitions and rewards without requiring adaptations.
Automated planning and scheduling, sometimes denoted as simply AI planning, is a branch of artificial intelligence that concerns the realization of strategies or action sequences, typically for execution by intelligent agents, autonomous robots and unmanned vehicles. Unlike classical control and classification problems, the solutions are complex and must be discovered and optimized in multidimensional space. Planning is also related to decision theory.
The principle of detailed balance can be used in kinetic systems which are decomposed into elementary processes. It states that at equilibrium, each elementary process is in equilibrium with its reverse process.
In probability theory and machine learning, the multi-armed bandit problem is a problem in which a decision maker iteratively selects one of multiple fixed choices when the properties of each choice are only partially known at the time of allocation, and may become better understood as time passes. A fundamental aspect of bandit problems is that choosing an arm does not affect the properties of the arm or other arms.
In mathematics, the theory of optimal stopping or early stopping is concerned with the problem of choosing a time to take a particular action, in order to maximise an expected reward or minimise an expected cost. Optimal stopping problems can be found in areas of statistics, economics, and mathematical finance. A key example of an optimal stopping problem is the secretary problem. Optimal stopping problems can often be written in the form of a Bellman equation, and are therefore often solved using dynamic programming.
In game theory, a stochastic game, introduced by Lloyd Shapley in the early 1950s, is a repeated game with probabilistic transitions played by one or more players. The game is played in a sequence of stages. At the beginning of each stage the game is in some state. The players select actions and each player receives a payoff that depends on the current state and the chosen actions. The game then moves to a new random state whose distribution depends on the previous state and the actions chosen by the players. The procedure is repeated at the new state and play continues for a finite or infinite number of stages. The total payoff to a player is often taken to be the discounted sum of the stage payoffs or the limit inferior of the averages of the stage payoffs.
State–action–reward–state–action (SARSA) is an algorithm for learning a Markov decision process policy, used in the reinforcement learning area of machine learning. It was proposed by Rummery and Niranjan in a technical note with the name "Modified Connectionist Q-Learning" (MCQ-L). The alternative name SARSA, proposed by Rich Sutton, was only mentioned as a footnote.
In probability theory, a Markov model is a stochastic model used to model pseudo-randomly changing systems. It is assumed that future states depend only on the current state, not on the events that occurred before it. Generally, this assumption enables reasoning and computation with the model that would otherwise be intractable. For this reason, in the fields of predictive modelling and probabilistic forecasting, it is desirable for a given model to exhibit the Markov property.
AIXI is a theoretical mathematical formalism for artificial general intelligence. It combines Solomonoff induction with sequential decision theory. AIXI was first proposed by Marcus Hutter in 2000 and several results regarding AIXI are proved in Hutter's 2005 book Universal Artificial Intelligence.
In machine learning, automatic basis function construction is the mathematical method of looking for a set of task-independent basis functions that map the state space to a lower-dimensional embedding, while still representing the value function accurately. Automatic basis construction is independent of prior knowledge of the domain, which allows it to perform well where expert-constructed basis functions are difficult or impossible to create.
Thompson sampling, named after William R. Thompson, is a heuristic for choosing actions that addresses the exploration-exploitation dilemma in the multi-armed bandit problem. It consists of choosing the action that maximizes the expected reward with respect to a randomly drawn belief.
Shlomo Zilberstein is an Israeli-American computer scientist. He is a Professor of Computer Science and Associate Dean for Research and Engagement in the College of Information and Computer Sciences at the University of Massachusetts, Amherst. He graduated with a B.A. in Computer Science summa cum laude from Technion – Israel Institute of Technology in 1982, and received a Ph.D. in Computer Science from University of California at Berkeley in 1993, advised by Stuart J. Russell. He is known for his contributions to artificial intelligence, anytime algorithms, multi-agent systems, and automated planning and scheduling algorithms, notably within the context of Markov decision processes (MDPs), Partially Observable MDPs (POMDPs), and Decentralized POMDPs (Dec-POMDPs).
The decentralized partially observable Markov decision process (Dec-POMDP) is a model for coordination and decision-making among multiple agents. It is a probabilistic model that can consider uncertainty in outcomes, sensors and communication.
The Coate–Loury model of affirmative action was developed by Stephen Coate and Glenn Loury in 1993. The model seeks to answer the question of whether, by mandating expanded opportunities for minorities in the present, these policies are rendered unnecessary in the future. Affirmative action may lead to one of two outcomes:
By improving employers’ perceptions of minorities or improving minorities’ skills, or both, affirmative action policies would eventually cause employers to want to hire minorities regardless of the presence of affirmative action policies.
By dampening incentives for minorities, affirmative action policies would reduce minority skill investment, thus leading to an equilibrium where employers correctly believe minorities to be less productive than majorities, thus perpetuating the need for affirmative action in order to achieve parity in the labor market.
↑ Smallwood, R.D., Sondik, E.J. (1973). "The optimal control of partially observable Markov decision processes over a finite horizon". Operations Research. 21 (5): 1071–88. doi:10.1287/opre.21.5.1071.{{cite journal}}: CS1 maint: multiple names: authors list (link)
↑ Sondik, E.J. (1978). "The optimal control of partially observable Markov processes over the infinite horizon: discounted cost". Operations Research. 26 (2): 282–304. doi:10.1287/opre.26.2.282.
↑ Hansen, E. (1998). "Solving POMDPs by searching in policy space". Proceedings of the Fourteenth International Conference on Uncertainty In Artificial Intelligence (UAI-98). arXiv:1301.7380.
↑ Lovejoy, W. (1991). "Computationally feasible bounds for partially observed Markov decision processes". Operations Research. 39: 162–175. doi:10.1287/opre.39.1.162.
1 2 Jesse Hoey; Axel von Bertoldi; Pascal Poupart; Alex Mihailidis (2007). "Assisting Persons with Dementia during Handwashing Using a Partially Observable Markov Decision Process". Proc. International Conference on Computer Vision Systems (ICVS). doi:10.2390/biecoll-icvs2007-89.
1 2 Jesse Hoey; Pascal Poupart; Axel von Bertoldi; Tammy Craig; Craig Boutilier; Alex Mihailidis. (2010). "Automated Handwashing Assistance For Persons With Dementia Using Video and a Partially Observable Markov Decision Process". Computer Vision and Image Understanding (CVIU). 114 (5): 503–519. CiteSeerX10.1.1.160.8351. doi:10.1016/j.cviu.2009.06.008.
↑ Hauskrecht, M. (1997). "Incremental methods for computing bounds in partially observable Markov decision processes". Proceedings of the 14th National Conference on Artificial Intelligence (AAAI). Providence, RI. pp.734–739. CiteSeerX10.1.1.85.8303.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.