
A data set is a collection of data. In the case of tabular data, a data set corresponds to one or more database tables, where every column of a table represents a particular variable, and each row corresponds to a given record of the data set in question. The data set lists values for each of the variables, such as for example height and weight of an object, for each member of the data set. Data sets can also consist of a collection of documents or files.

In statistics and probability theory, the median is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as "the middle" value. The basic feature of the median in describing data compared to the mean is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe center of the income distribution because increases in the largest incomes alone have no effect on median. For this reason, the median is of central importance in robust statistics.
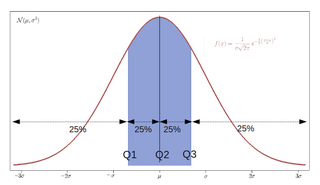
In statistics and probability, quantiles are cut points dividing the range of a probability distribution into continuous intervals with equal probabilities, or dividing the observations in a sample in the same way. There is one fewer quantile than the number of groups created. Common quantiles have special names, such as quartiles, deciles, and percentiles. The groups created are termed halves, thirds, quarters, etc., though sometimes the terms for the quantile are used for the groups created, rather than for the cut points.
Statistics is a field of inquiry that studies the collection, analysis, interpretation, and presentation of data. It is applicable to a wide variety of academic disciplines, from the physical and social sciences to the humanities; it is also used and misused for making informed decisions in all areas of business and government.

In statistics, an outlier is a data point that differs significantly from other observations. An outlier may be due to a variability in the measurement, an indication of novel data, or it may be the result of experimental error; the latter are sometimes excluded from the data set. An outlier can be an indication of exciting possibility, but can also cause serious problems in statistical analyses.

In statistical modeling, regression analysis is a set of statistical processes for estimating the relationships between a dependent variable and one or more independent variables. The most common form of regression analysis is linear regression, in which one finds the line that most closely fits the data according to a specific mathematical criterion. For example, the method of ordinary least squares computes the unique line that minimizes the sum of squared differences between the true data and that line. For specific mathematical reasons, this allows the researcher to estimate the conditional expectation of the dependent variable when the independent variables take on a given set of values. Less common forms of regression use slightly different procedures to estimate alternative location parameters or estimate the conditional expectation across a broader collection of non-linear models.
In robust statistics, robust regression seeks to overcome some limitations of traditional regression analysis. A regression analysis models the relationship between one or more independent variables and a dependent variable. Standard types of regression, such as ordinary least squares, have favourable properties if their underlying assumptions are true, but can give misleading results otherwise. Robust regression methods are designed to limit the effect that violations of assumptions by the underlying data-generating process have on regression estimates.
In statistics, the mid-range or mid-extreme is a measure of central tendency of a sample defined as the arithmetic mean of the maximum and minimum values of the data set:
Robust statistics are statistics with good performance for data drawn from a wide range of probability distributions, especially for distributions that are not normal. Robust statistical methods have been developed for many common problems, such as estimating location, scale, and regression parameters. One motivation is to produce statistical methods that are not unduly affected by outliers. Another motivation is to provide methods with good performance when there are small departures from a parametric distribution. For example, robust methods work well for mixtures of two normal distributions with different standard deviations; under this model, non-robust methods like a t-test work poorly.

Local regression or local polynomial regression, also known as moving regression, is a generalization of the moving average and polynomial regression. Its most common methods, initially developed for scatterplot smoothing, are LOESS and LOWESS, both pronounced. They are two strongly related non-parametric regression methods that combine multiple regression models in a k-nearest-neighbor-based meta-model. In some fields, LOESS is known and commonly referred to as Savitzky–Golay filter.
In statistics, the Hodges–Lehmann estimator is a robust and nonparametric estimator of a population's location parameter. For populations that are symmetric about one median, such as the (Gaussian) normal distribution or the Student t-distribution, the Hodges–Lehmann estimator is a consistent and median-unbiased estimate of the population median. For non-symmetric populations, the Hodges–Lehmann estimator estimates the "pseudo–median", which is closely related to the population median.
Least absolute deviations (LAD), also known as least absolute errors (LAE), least absolute residuals (LAR), or least absolute values (LAV), is a statistical optimality criterion and a statistical optimization technique based on minimizing the sum of absolute deviations or the L1 norm of such values. It is analogous to the least squares technique, except that it is based on absolute values instead of squared values. It attempts to find a function which closely approximates a set of data by minimizing residuals between points generated by the function and corresponding data points. The LAD estimate also arises as the maximum likelihood estimate if the errors have a Laplace distribution. It was introduced in 1757 by Roger Joseph Boscovich.

A plot is a graphical technique for representing a data set, usually as a graph showing the relationship between two or more variables. The plot can be drawn by hand or by a computer. In the past, sometimes mechanical or electronic plotters were used. Graphs are a visual representation of the relationship between variables, which are very useful for humans who can then quickly derive an understanding which may not have come from lists of values. Given a scale or ruler, graphs can also be used to read off the value of an unknown variable plotted as a function of a known one, but this can also be done with data presented in tabular form. Graphs of functions are used in mathematics, sciences, engineering, technology, finance, and other areas.
In statistics, robust measures of scale are methods that quantify the statistical dispersion in a sample of numerical data while resisting outliers. The most common such robust statistics are the interquartile range (IQR) and the median absolute deviation (MAD). These are contrasted with conventional or non-robust measures of scale, such as sample variance or standard deviation, which are greatly influenced by outliers.
The following outline is provided as an overview of and topical guide to regression analysis:
Least trimmed squares (LTS), or least trimmed sum of squares, is a robust statistical method that fits a function to a set of data whilst not being unduly affected by the presence of outliers. It is one of a number of methods for robust regression.

Peter J. Rousseeuw is a statistician known for his work on robust statistics and cluster analysis. He obtained his PhD in 1981 at the Vrije Universiteit Brussel, following research carried out at the ETH in Zurich, which led to a book on influence functions. Later he was professor at the Delft University of Technology, The Netherlands, at the University of Fribourg, Switzerland, and at the University of Antwerp, Belgium. Next he was a senior researcher at Renaissance Technologies. He then returned to Belgium as professor at KU Leuven, until becoming emeritus in 2022. His former PhD students include Annick Leroy, Hendrik Lopuhaä, Geert Molenberghs, Christophe Croux, Mia Hubert, Stefan Van Aelst, Tim Verdonck and Jakob Raymaekers.

In non-parametric statistics, the Theil–Sen estimator is a method for robustly fitting a line to sample points in the plane by choosing the median of the slopes of all lines through pairs of points. It has also been called Sen's slope estimator, slope selection, the single median method, the Kendall robust line-fit method, and the Kendall–Theil robust line. It is named after Henri Theil and Pranab K. Sen, who published papers on this method in 1950 and 1968 respectively, and after Maurice Kendall because of its relation to the Kendall tau rank correlation coefficient.
In statistics, linear regression is a linear approach for modelling the relationship between a scalar response and one or more explanatory variables. The case of one explanatory variable is called simple linear regression; for more than one, the process is called multiple linear regression. This term is distinct from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable.
