Related Research Articles
A macron is a diacritical mark: it is a straight bar ¯ placed above a letter, usually a vowel. Its name derives from Ancient Greek μακρόν (makrón) 'long' because it was originally used to mark long or heavy syllables in Greco-Roman metrics. It now more often marks a long vowel. In the International Phonetic Alphabet, the macron is used to indicate a mid-tone; the sign for a long vowel is instead a modified triangular colon ⟨ː⟩.
An orthography is a set of conventions for writing a language, including norms of spelling, hyphenation, capitalization, word boundaries, emphasis, and punctuation.
In phonology and linguistics, a phoneme is a set of phones that can distinguish one word from another in a particular language.
Romani is an Indo-Aryan macrolanguage of the Romani communities. According to Ethnologue, seven varieties of Romani are divergent enough to be considered languages of their own. The largest of these are Vlax Romani, Balkan Romani (600,000), and Sinte Romani (300,000). Some Romani communities speak mixed languages based on the surrounding language with retained Romani-derived vocabulary – these are known by linguists as Para-Romani varieties, rather than dialects of the Romani language itself.
Finnish orthography is based on the Latin script, and uses an alphabet derived from the Swedish alphabet, officially comprising twenty-nine letters but also including two additional letters found in some loanwords. The Finnish orthography strives to represent all morphemes phonologically and, roughly speaking, the sound value of each letter tends to correspond with its value in the International Phonetic Alphabet (IPA) – although some discrepancies do exist.
A caron is a diacritic mark commonly placed over certain letters in the orthography of some languages to indicate a change of the related letter's pronunciation.
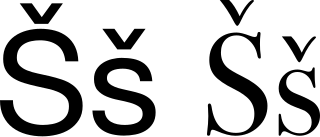
The grapheme Š, š is used in various contexts representing the sh sound like in the word show, usually denoting the voiceless postalveolar fricative /ʃ/ or similar voiceless retroflex fricative /ʂ/. In the International Phonetic Alphabet this sound is denoted with ʃ or ʂ, but the lowercase š is used in the Americanist phonetic notation, as well as in the Uralic Phonetic Alphabet. It represents the same sound as the Turkic letter Ş and the Romanian letter Ș (S-comma), the Hebrew and Yiddish letter ש, the Ge'ez (Ethiopic) letter ሠ and the Arabic letter ش.
A phonemic orthography is an orthography in which the graphemes correspond to the language's phonemes. Natural languages rarely have perfectly phonemic orthographies; a high degree of grapheme–phoneme correspondence can be expected in orthographies based on alphabetic writing systems, but they differ in how complete this correspondence is. English orthography, for example, is alphabetic but highly nonphonemic; it was once mostly phonemic during the Middle English stage, when the modern spellings originated, but spoken English changed rapidly while the orthography was much more stable, resulting in the modern nonphonemic situation. On the contrary the Albanian, Serbian/Croatian/Bosnian/Montenegrin, Romanian, Italian, Turkish, Spanish, Finnish, Czech, Latvian, Esperanto, Korean and Swahili orthographic systems come much closer to being consistent phonemic representations.

A digraph or digram is a pair of characters used in the orthography of a language to write either a single phoneme, or a sequence of phonemes that does not correspond to the normal values of the two characters combined.

Gaj's Latin alphabet, also known as abeceda or gajica, is the form of the Latin script used for writing Serbo-Croatian and all of its standard varieties: Bosnian, Croatian, Montenegrin, and Serbian.

The grapheme Ř, ř is a letter used in the alphabets of the Czech and Upper Sorbian languages. It was also used in proposed orthographies for the Silesian language. It has been used in academic transcriptions for rhotic sounds.

Vlax Romani is a dialect group of the Romani language. Vlax Romani varieties are spoken mainly in Southeastern Europe by the Romani people. Vlax Romani can also be referred to as an independent language or as one dialect of the Romani language. Vlax Romani is the second most widely spoken dialect subgroup of the Romani language worldwide, after Balkan Romani.
The phonology of the Ojibwe language varies from dialect to dialect, but all varieties share common features. Ojibwe is an indigenous language of the Algonquian language family spoken in Canada and the United States in the areas surrounding the Great Lakes, and westward onto the northern plains in both countries, as well as in northeastern Ontario and northwestern Quebec. The article on Ojibwe dialects discusses linguistic variation in more detail, and contains links to separate articles on each dialect. There is no standard language and no dialect that is accepted as representing a standard. Ojibwe words in this article are written in the practical orthography commonly known as the Double vowel system.
Czech orthography is a system of rules for proper formal writing (orthography) in Czech. The earliest form of separate Latin script specifically designed to suit Czech was devised by Czech theologian and church reformist Jan Hus, the namesake of the Hussite movement, in one of his seminal works, De orthographia bohemica.
The Czech language developed at the close of the 1st millennium from common West Slavic. Until the early 20th century, it was known as Bohemian.

ä
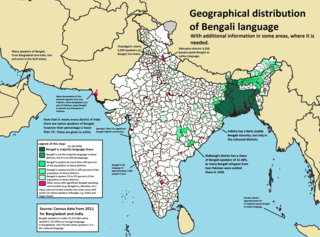
Bengali, also known by its endonym Bangla, is an Indo-Aryan language native to the Bengal region of South Asia. With approximately 240 million native speakers and another 41 million as second language speakers as of 2021, Bengali is the sixth most spoken native language and the seventh most spoken language by the total number of speakers in the world. It is the fifth most spoken Indo-European language.

The Bengali script or Bangla alphabet is the alphabet used to write the Bengali language based on the Bengali-Assamese script, and has historically been used to write Sanskrit within Bengal. It is one of the most widely adopted writing systems in the world . It is one of the official scripts of the Indian Republic. It is used as the official script of the Bengali language in Bangladesh, West Bengal, Tripura and Barak valley of Assam Until recently, it was the usual script for the Meitei language in Manipur, but is being replaced by Meitei mayek. two of the official languages of India.
This article describes the phonology of the Occitan language.

Podlachian language is an East Slavic literary microlanguage based on the East Slavic dialects spoken by inhabitants of the southern part of Podlachian Province in Poland between the Narew (north) and Bug (south) rivers. The native speakers of these dialects usually refer to them by the adverbial term po-svojomu. The unequivocal academic classification of the po-svojomu dialects has been disputed for many years among linguists as well as activists of ethnic minorities in Podlachia, who classify them as either Belarusian dialects with Ukrainian traits or Ukrainian dialects.
References
- Bagchi, Tista (December 28, 2016). "Romany language". Britannica Online Encyclopedia. Retrieved January 28, 2022.
- Bakker, Peter; Kyuchukov, Hristo, eds. (2000), What Is the Romani Language?, Interface Collection, vol. 21, Centre de Recherches Tsiganes; University of Hertfordshire Press, ISBN 1-902806-06-9
- Boretzky, Nobert; Igla, Birgit (1994), Wörterbuch Romani-Deutsch-Englisch für den südosteuropäischen Raum : mit einer Grammatik der Dialektvarianten, Wiesbaden: Harrassowitz Verlag, ISBN 3-447-03459-9
- Courthiade, Marcel (2009), Rézműves, Melinda (ed.), Morri angluni rromane ćhibǎqi evroputni lavustik (in Romany, Hungarian, English, French, Spanish, German, Ukrainian, Romanian, Croatian, Slovak, and Greek), Budapest: Fővárosi Onkormányzat Cigány Ház--Romano Kher, ISBN 978-963-85408-6-7
- Djonedi, Fereydun (1996). "Romano Glossar. Gesammelt von Schir-ali Tehranizade" (PDF). Grazer Linguistische Studien (in German). 46: 31–59. Archived from the original (PDF) on February 5, 2012.
- Everson, Michael (October 7, 2001). "Romani" (PDF). Everytype: The Alphabets of Europe. Retrieved January 28, 2022.
- Granqvist, Kimmo (2011), Lyhyt Suomen romanikielen kielioppi [Consice grammar of Finnish Romani], Helsinki: Kotimaisten kielten keskus, ISBN 978-952-5446-69-2
- Hancock, Ian (1995), A Handbook of Vlax Romani, Columbus: Slavica Publishers, ISBN 0-89357-258-6
- Kepeski, Krume; Jusuf, Šaip (1980), Romani gramatika = Ромска граматика (in Macedonian and Romany), Skopje: Naša Kniga
- Lee, Ronald (2005), Learn Romani: Das-dúma Rromanes, Hatfield: University of Hertfordshire Press, ISBN 1-902806-44-1
- Matras, Yaron (December 1999). "Writing Romani: The pragmatics of codification in a stateless language" (PDF). Applied Linguistics. 20 (4): 481–502. doi:10.1093/applin/20.4.481.
- Matras, Yaron (2002), Romani: A Linguistic Introduction, Cambridge: Cambridge University Press, ISBN 0-521-02330-0
- Petrovski, Trajko (2021), I čhib thaj i kultura romengiri bašo III klasi (PDF) (in Romany) (2nd ed.), Skopje: Ministry of Education and Science of the Republic of Northern Macedonia, ISBN 978-608-226-933-7 , retrieved January 28, 2022
- Sarău, Gheorghe (1994), Limba Romani (țigănească): Manual pentru Clasele de Învățători Romi ale Școlilor Normale, Bucharest: Editura Didactică și Pedagogică
- Serghievsky, M. V.; Barannikov, A. P. (1938), Цыганско-русский словарь [Romani-Russian dictionary] (in Russian), Moscow, archived from the original on April 26, 2012
{{citation}}: CS1 maint: location missing publisher (link)
Suggested further reading
- Hodge, Nathanael (2011), Romani Orthographies (PDF), University of Manchester, retrieved January 28, 2022
{{citation}}: CS1 maint: location missing publisher (link) - Matras, Yaron (2005). "The future of Romani: Toward a policy of linguistic pluralism" (PDF). Roma Rights Quarterly. 1: 31–44.
- Meyer, Anna-Maria (2019). "The creation of orthographies for Romani by means of 'Slavic' alphabets". In Kempgen, Sebastian; Tomelleri, Vittorio Springfield (eds.). Slavic Alphabets and Identities (PDF) (in English, German, and Russian). Bamberg: Bamberg University Press. pp. 129–160. ISBN 978-3-86309-617-5.