Related Research Articles
In theoretical computer science and formal language theory, a regular language is a formal language that can be defined by a regular expression, in the strict sense in theoretical computer science.

Automata theory is the study of abstract machines and automata, as well as the computational problems that can be solved using them. It is a theory in theoretical computer science. The word automata comes from the Greek word αὐτόματος, which means "self-acting, self-willed, self-moving". An automaton is an abstract self-propelled computing device which follows a predetermined sequence of operations automatically. An automaton with a finite number of states is called a Finite Automaton (FA) or Finite-State Machine (FSM).
In the theory of formal languages, the Myhill–Nerode theorem provides a necessary and sufficient condition for a language to be regular. The theorem is named for John Myhill and Anil Nerode, who proved it at the University of Chicago in 1958.

In computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.
Computability is the ability to solve a problem in an effective manner. It is a key topic of the field of computability theory within mathematical logic and the theory of computation within computer science. The computability of a problem is closely linked to the existence of an algorithm to solve the problem.

In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite-state machine (DFSM), or deterministic finite-state automaton (DFSA)—is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string. Deterministic refers to the uniqueness of the computation run. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.
In automata theory, a finite-state machine is called a deterministic finite automaton (DFA), if
In the theory of computation and automata theory, the powerset construction or subset construction is a standard method for converting a nondeterministic finite automaton (NFA) into a deterministic finite automaton (DFA) which recognizes the same formal language. It is important in theory because it establishes that NFAs, despite their additional flexibility, are unable to recognize any language that cannot be recognized by some DFA. It is also important in practice for converting easier-to-construct NFAs into more efficiently executable DFAs. However, if the NFA has n states, the resulting DFA may have up to 2n states, an exponentially larger number, which sometimes makes the construction impractical for large NFAs.
In automata theory, a permutation automaton, or pure-group automaton, is a deterministic finite automaton such that each input symbol permutes the set of states.
In computer science, a linear bounded automaton is a restricted form of Turing machine.
In automata theory, a deterministic pushdown automaton is a variation of the pushdown automaton. The class of deterministic pushdown automata accepts the deterministic context-free languages, a proper subset of context-free languages.
In computer science, in particular in automata theory, a two-way finite automaton is a finite automaton that is allowed to re-read its input.
In mathematics and theoretical computer science, an automatic sequence is an infinite sequence of terms characterized by a finite automaton. The n-th term of an automatic sequence a(n) is a mapping of the final state reached in a finite automaton accepting the digits of the number n in some fixed base k.
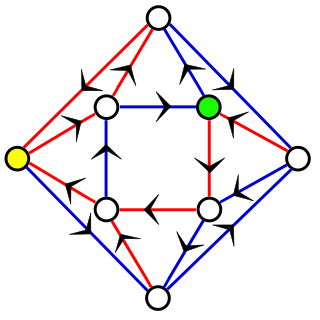
In computer science, more precisely, in the theory of deterministic finite automata (DFA), a synchronizing word or reset sequence is a word in the input alphabet of the DFA that sends any state of the DFA to one and the same state. That is, if an ensemble of copies of the DFA are each started in different states, and all of the copies process the synchronizing word, they will all end up in the same state. Not every DFA has a synchronizing word; for instance, a DFA with two states, one for words of even length and one for words of odd length, can never be synchronized.

In automata theory, DFA minimization is the task of transforming a given deterministic finite automaton (DFA) into an equivalent DFA that has a minimum number of states. Here, two DFAs are called equivalent if they recognize the same regular language. Several different algorithms accomplishing this task are known and described in standard textbooks on automata theory.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
In computer science and mathematical logic, an infinite-tree automaton is a state machine that deals with infinite tree structures. It can be seen as an extension of top-down finite-tree automata to infinite trees or as an extension of infinite-word automata to infinite trees.
In computer science, the complexity function of a word or string is the function that counts the number of distinct factors of that string. More generally, the complexity function of a formal language counts the number of distinct words of given length.
In computational learning theory, induction of regular languages refers to the task of learning a formal description of a regular language from a given set of example strings. Although E. Mark Gold has shown that not every regular language can be learned this way, approaches have been investigated for a variety of subclasses. They are sketched in this article. For learning of more general grammars, see Grammar induction.
In mathematics, the Chvátal–Sankoff constants are mathematical constants that describe the lengths of longest common subsequences of random strings. Although the existence of these constants has been proven, their exact values are unknown. They are named after Václav Chvátal and David Sankoff, who began investigating them in the mid-1970s.
References
- 1 2 3 4 5 6 7 Demaine, Erik D.; Eisenstat, Sarah; Shallit, Jeffrey; Wilson, David A. (2011), "Remarks on separating words", Descriptional Complexity of Formal Systems: 13th International Workshop, DCFS 2011, Gießen/Limburg, Germany, July 25-27, 2011, Proceedings, Lecture Notes in Computer Science, vol. 6808, Heidelberg: Springer-Verlag, pp. 147–157, arXiv: 1103.4513 , doi:10.1007/978-3-642-22600-7_12, MR 2910373, S2CID 6959459 .
- ↑ Goralčík, P.; Koubek, V. (1986), "On discerning words by automata", Automata, Languages and Programming: 13th International Colloquium, Rennes, France, July 15–19, 1986, Proceedings, Lecture Notes in Computer Science, vol. 226, Berlin: Springer-Verlag, pp. 116–122, doi:10.1007/3-540-16761-7_61, MR 0864674 .
- ↑ Robson, J. M. (1989), "Separating strings with small automata", Information Processing Letters, 30 (4): 209–214, doi:10.1016/0020-0190(89)90215-9, MR 0986823 .
- ↑ Chase, Z. (2020), "A New Upper Bound for Separating Words", arXiv: 2007.12097 [math.CO].
- ↑ Shallit, Jeffrey (2014), "Open Problems in Automata Theory: An Idiosyncratic View", British Colloquium for Theoretical Computer Science (BCTCS 2014), Loughborough University (PDF).