
In probability theory, a probability density function (PDF), density function, or density of an absolutely continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample. Probability density is the probability per unit length, in other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.
In machine learning, support vector machines are supervised max-margin models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most studied models, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974).
Del, or nabla, is an operator used in mathematics as a vector differential operator, usually represented by the nabla symbol ∇. When applied to a function defined on a one-dimensional domain, it denotes the standard derivative of the function as defined in calculus. When applied to a field, it may denote any one of three operations depending on the way it is applied: the gradient or (locally) steepest slope of a scalar field ; the divergence of a vector field; or the curl (rotation) of a vector field.
In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector.
In mathematics, the Laplace operator or Laplacian is a differential operator given by the divergence of the gradient of a scalar function on Euclidean space. It is usually denoted by the symbols , (where is the nabla operator), or . In a Cartesian coordinate system, the Laplacian is given by the sum of second partial derivatives of the function with respect to each independent variable. In other coordinate systems, such as cylindrical and spherical coordinates, the Laplacian also has a useful form. Informally, the Laplacian Δf (p) of a function f at a point p measures by how much the average value of f over small spheres or balls centered at p deviates from f (p).
In vector calculus, Green's theorem relates a line integral around a simple closed curve C to a double integral over the plane region D bounded by C. It is the two-dimensional special case of Stokes' theorem.
In the calculus of variations, a field of mathematical analysis, the functional derivative relates a change in a functional to a change in a function on which the functional depends.
In mathematics, the Hodge star operator or Hodge star is a linear map defined on the exterior algebra of a finite-dimensional oriented vector space endowed with a nondegenerate symmetric bilinear form. Applying the operator to an element of the algebra produces the Hodge dual of the element. This map was introduced by W. V. D. Hodge.
In mathematics, the Hessian matrix, Hessian or Hesse matrix is a square matrix of second-order partial derivatives of a scalar-valued function, or scalar field. It describes the local curvature of a function of many variables. The Hessian matrix was developed in the 19th century by the German mathematician Ludwig Otto Hesse and later named after him. Hesse originally used the term "functional determinants". The Hessian is sometimes denoted by H or, ambiguously, by ∇2.
In mathematics and computing, the Levenberg–Marquardt algorithm, also known as the damped least-squares (DLS) method, is used to solve non-linear least squares problems. These minimization problems arise especially in least squares curve fitting. The LMA interpolates between the Gauss–Newton algorithm (GNA) and the method of gradient descent. The LMA is more robust than the GNA, which means that in many cases it finds a solution even if it starts very far off the final minimum. For well-behaved functions and reasonable starting parameters, the LMA tends to be slower than the GNA. LMA can also be viewed as Gauss–Newton using a trust region approach.

The Gauss–Newton algorithm is used to solve non-linear least squares problems, which is equivalent to minimizing a sum of squared function values. It is an extension of Newton's method for finding a minimum of a non-linear function. Since a sum of squares must be nonnegative, the algorithm can be viewed as using Newton's method to iteratively approximate zeroes of the components of the sum, and thus minimizing the sum. In this sense, the algorithm is also an effective method for solving overdetermined systems of equations. It has the advantage that second derivatives, which can be challenging to compute, are not required.
In mathematics, matrix calculus is a specialized notation for doing multivariable calculus, especially over spaces of matrices. It collects the various partial derivatives of a single function with respect to many variables, and/or of a multivariate function with respect to a single variable, into vectors and matrices that can be treated as single entities. This greatly simplifies operations such as finding the maximum or minimum of a multivariate function and solving systems of differential equations. The notation used here is commonly used in statistics and engineering, while the tensor index notation is preferred in physics.
The softmax function, also known as softargmax or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes.
In statistics, the multivariate t-distribution is a multivariate probability distribution. It is a generalization to random vectors of the Student's t-distribution, which is a distribution applicable to univariate random variables. While the case of a random matrix could be treated within this structure, the matrix t-distribution is distinct and makes particular use of the matrix structure.
Oja's learning rule, or simply Oja's rule, named after Finnish computer scientist Erkki Oja, is a model of how neurons in the brain or in artificial neural networks change connection strength, or learn, over time. It is a modification of the standard Hebb's Rule that, through multiplicative normalization, solves all stability problems and generates an algorithm for principal components analysis. This is a computational form of an effect which is believed to happen in biological neurons.
In the field of mathematical modeling, a radial basis function network is an artificial neural network that uses radial basis functions as activation functions. The output of the network is a linear combination of radial basis functions of the inputs and neuron parameters. Radial basis function networks have many uses, including function approximation, time series prediction, classification, and system control. They were first formulated in a 1988 paper by Broomhead and Lowe, both researchers at the Royal Signals and Radar Establishment.
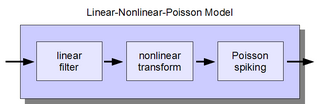
The linear-nonlinear-Poisson (LNP) cascade model is a simplified functional model of neural spike responses. It has been successfully used to describe the response characteristics of neurons in early sensory pathways, especially the visual system. The LNP model is generally implicit when using reverse correlation or the spike-triggered average to characterize neural responses with white-noise stimuli.

The multivariate stable distribution is a multivariate probability distribution that is a multivariate generalisation of the univariate stable distribution. The multivariate stable distribution defines linear relations between stable distribution marginals. In the same way as for the univariate case, the distribution is defined in terms of its characteristic function.

In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs).
In statistics, machine learning and algorithms, a tensor sketch is a type of dimensionality reduction that is particularly efficient when applied to vectors that have tensor structure. Such a sketch can be used to speed up explicit kernel methods, bilinear pooling in neural networks and is a cornerstone in many numerical linear algebra algorithms.












