Stochastic dominance is a partial order between random variables.[1][2] It is a form of stochastic ordering. The concept arises in decision theory and decision analysis in situations where one gamble (a probability distribution over possible outcomes, also known as prospects) can be ranked as superior to another gamble for a broad class of decision-makers. It is based on shared preferences regarding sets of possible outcomes and their associated probabilities. Only limited knowledge of preferences is required for determining dominance. Risk aversion is a factor only in second order stochastic dominance.
Stochastic dominance does not give a total order, but rather only a partial order: for some pairs of gambles, neither one stochastically dominates the other, since different members of the broad class of decision-makers will differ regarding which gamble is preferable without them generally being considered to be equally attractive.
Throughout the article, stand for probability distributions on , while stand for particular random variables on . The notation means that has distribution .
There are a sequence of stochastic dominance orderings, from first , to second , to higher orders . The sequence is increasingly more inclusive. That is, if , then for all . Further, there exists such that but not [contradictory].
Stochastic dominance could trace back to (Blackwell, 1953),[3] but it was not developed until 1969–1970.[4]
Statewise dominance (Zeroth-Order)
The simplest case of stochastic dominance is statewise dominance (also known as state-by-state dominance), defined as follows:
Random variable A is statewise dominant over random variable B if A gives at least as good a result in every state (every possible set of outcomes), and a strictly better result in at least one state.
For example, if a dollar is added to one or more prizes in a lottery, the new lottery statewise dominates the old one because it yields a better payout regardless of the specific numbers realized by the lottery. Similarly, if a risk insurance policy has a lower premium and a better coverage than another policy, then with or without damage, the outcome is better. Anyone who prefers more to less (in the standard terminology, anyone who has monotonically increasing preferences) will always prefer a statewise dominant gamble.
First-order
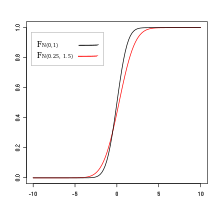
und , X and Y are not compareable through first-order stochastic dominance.
Statewise dominance implies first-order stochastic dominance (FSD),[5] which is defined as:
Random variable A has first-order stochastic dominance over random variable B if for any outcome x, A gives at least as high a probability of receiving at least x as does B, and for some x, A gives a higher probability of receiving at least x. In notation form, for all x, and for some x, .
In terms of the cumulative distribution functions of the two random variables, A dominating B means that for all x, with strict inequality at somex.
Let be two probability distributions on , such that are both finite, then the following conditions are equivalent, thus they may all serve as the definition of first-order stochastic dominance:[7]
For any that is non-decreasing,
There exists two random variables , such that , where .
The first definition states that a gamble first-order stochastically dominates gamble if and only if every expected utility maximizer with an increasing utility function prefers gamble over gamble .
The third definition states that we can construct a pair of gambles with distributions , such that gamble always pays at least as much as gamble . More concretely, construct first a uniformly distributed , then use the inverse transform sampling to get , then for any .
Pictorially, the second and third definition are equivalent, because we can go from the graphed density function of A to that of B both by pushing it upwards and pushing it leftwards.
Extended example
Consider three gambles over a single toss of a fair six-sided die:
Gamble A statewise dominates gamble B because A gives at least as good a yield in all possible states (outcomes of the die roll) and gives a strictly better yield in one of them (state 3). Since A statewise dominates B, it also first-order dominates B.
Gamble C does not statewise dominate B because B gives a better yield in states 4 through 6, but C first-order stochastically dominates B because Pr(B ≥ 1) = Pr(C ≥ 1) = 1, Pr(B ≥ 2) = Pr(C ≥ 2) = 3/6, and Pr(B ≥ 3) = 0 while Pr(C ≥ 3) = 3/6 > Pr(B ≥ 3).
Gambles A and C cannot be ordered relative to each other on the basis of first-order stochastic dominance because Pr(A ≥ 2) = 4/6 > Pr(C ≥ 2) = 3/6 while on the other hand Pr(C ≥ 3) = 3/6 > Pr(A ≥ 3) = 0.
In general, although when one gamble first-order stochastically dominates a second gamble, the expected value of the payoff under the first will be greater than the expected value of the payoff under the second, the converse is not true: one cannot order lotteries with regard to stochastic dominance simply by comparing the means of their probability distributions. For instance, in the above example C has a higher mean (2) than does A (5/3), yet C does not first-order dominate A.
Second-order
The other commonly used type of stochastic dominance is second-order stochastic dominance.[1][8][9] Roughly speaking, for two gambles and , gamble has second-order stochastic dominance over gamble if the former is more predictable (i.e. involves less risk) and has at least as high a mean. All risk-averseexpected-utility maximizers (that is, those with increasing and concave utility functions) prefer a second-order stochastically dominant gamble to a dominated one. Second-order dominance describes the shared preferences of a smaller class of decision-makers (those for whom more is better and who are averse to risk, rather than all those for whom more is better) than does first-order dominance.
In terms of cumulative distribution functions and , is second-order stochastically dominant over if and only if for all , with strict inequality at some . Equivalently, dominates in the second order if and only if for all nondecreasing and concave utility functions .
Second-order stochastic dominance can also be expressed as follows: Gamble second-order stochastically dominates if and only if there exist some gambles and such that , with always less than or equal to zero, and with for all values of . Here the introduction of random variable makes first-order stochastically dominated by (making disliked by those with an increasing utility function), and the introduction of random variable introduces a mean-preserving spread in which is disliked by those with concave utility. Note that if and have the same mean (so that the random variable degenerates to the fixed number 0), then is a mean-preserving spread of .
Equivalent definitions
Let be two probability distributions on , such that are both finite, then the following conditions are equivalent, thus they may all serve as the definition of second-order stochastic dominance:[7]
For any that is non-decreasing, and (not necessarily strictly) concave,
There exists two random variables , such that , where and .
These are analogous with the equivalent definitions of first-order stochastic dominance, given above.
Sufficient conditions
First-order stochastic dominance of A over B is a sufficient condition for second-order dominance of A over B.
If B is a mean-preserving spread of A, then A second-order stochastically dominates B.
Necessary conditions
is a necessary condition for A to second-order stochastically dominate B.
is a necessary condition for A to second-order dominate B. The condition implies that the left tail of must be thicker than the left tail of .
Third-order
Let and be the cumulative distribution functions of two distinct investments and . dominates in the third order if and only if both
.
Equivalently, dominates in the third order if and only if for all .
The set has two equivalent definitions:
the set of nondecreasing, concave utility functions that are positively skewed (that is, have a nonnegative third derivative throughout).[10]
the set of nondecreasing, concave utility functions, such that for any random variable , the risk-premium function is a monotonically nonincreasing function of .[11]
is a necessary condition. The condition implies that the geometric mean of must be greater than or equal to the geometric mean of .
is a necessary condition. The condition implies that the left tail of must be thicker than the left tail of .
Higher-order
Higher orders of stochastic dominance have also been analyzed, as have generalizations of the dual relationship between stochastic dominance orderings and classes of preference functions.[12] Arguably the most powerful dominance criterion relies on the accepted economic assumption of decreasing absolute risk aversion.[13][14] This involves several analytical challenges and a research effort is on its way to address those. [15]
Formally, the n-th-order stochastic dominance is defined as [16]
For any probability distribution on , define the functions inductively:
For any two probability distributions on , non-strict and strict n-th-order stochastic dominance is defined as
These relations are transitive and increasingly more inclusive. That is, if , then for all . Further, there exists such that but not .
Define the n-th moment by , then
Theorem—If are on with finite moments for all , then .
Here, the partial ordering is defined on by iff , and, letting be the smallest such that , we have
Constraints
Stochastic dominance relations may be used as constraints in problems of mathematical optimization, in particular stochastic programming.[17][18][19] In a problem of maximizing a real functional over random variables in a set we may additionally require that stochastically dominates a fixed random benchmark. In these problems, utility functions play the role of Lagrange multipliers associated with stochastic dominance constraints. Under appropriate conditions, the solution of the problem is also a (possibly local) solution of the problem to maximize over in , where is a certain utility function. If the first order stochastic dominance constraint is employed, the utility function is nondecreasing; if the second order stochastic dominance constraint is used, is nondecreasing and concave. A system of linear equations can test whether a given solution if efficient for any such utility function.[20] Third-order stochastic dominance constraints can be dealt with using convex quadratically constrained programming (QCP).[21]
The Navier–Stokes equations are partial differential equations which describe the motion of viscous fluid substances. They were named after French engineer and physicist Claude-Louis Navier and the Irish physicist and mathematician George Gabriel Stokes. They were developed over several decades of progressively building the theories, from 1822 (Navier) to 1842–1850 (Stokes).
In statistics, the Pearson correlation coefficient (PCC) is a correlation coefficient that measures linear correlation between two sets of data. It is the ratio between the covariance of two variables and the product of their standard deviations; thus, it is essentially a normalized measurement of the covariance, such that the result always has a value between −1 and 1. As with covariance itself, the measure can only reflect a linear correlation of variables, and ignores many other types of relationships or correlations. As a simple example, one would expect the age and height of a sample of teenagers from a high school to have a Pearson correlation coefficient significantly greater than 0, but less than 1.
The theory of functions of several complex variables is the branch of mathematics dealing with functions defined on the complex coordinate space, that is, n-tuples of complex numbers. The name of the field dealing with the properties of these functions is called several complex variables, which the Mathematics Subject Classification has as a top-level heading.
In probability theory, a Lévy process, named after the French mathematician Paul Lévy, is a stochastic process with independent, stationary increments: it represents the motion of a point whose successive displacements are random, in which displacements in pairwise disjoint time intervals are independent, and displacements in different time intervals of the same length have identical probability distributions. A Lévy process may thus be viewed as the continuous-time analog of a random walk.
Probability theory and statistics have some commonly used conventions, in addition to standard mathematical notation and mathematical symbols.
In information theory, information dimension is an information measure for random vectors in Euclidean space, based on the normalized entropy of finely quantized versions of the random vectors. This concept was first introduced by Alfréd Rényi in 1959.
Semidefinite programming (SDP) is a subfield of mathematical programming concerned with the optimization of a linear objective function over the intersection of the cone of positive semidefinite matrices with an affine space, i.e., a spectrahedron.
The Navier–Stokes existence and smoothness problem concerns the mathematical properties of solutions to the Navier–Stokes equations, a system of partial differential equations that describe the motion of a fluid in space. Solutions to the Navier–Stokes equations are used in many practical applications. However, theoretical understanding of the solutions to these equations is incomplete. In particular, solutions of the Navier–Stokes equations often include turbulence, which remains one of the greatest unsolved problems in physics, despite its immense importance in science and engineering.
In mathematics, the Wasserstein distance or Kantorovich–Rubinstein metric is a distance function defined between probability distributions on a given metric space . It is named after Leonid Vaseršteĭn.
Robust optimization is a field of mathematical optimization theory that deals with optimization problems in which a certain measure of robustness is sought against uncertainty that can be represented as deterministic variability in the value of the parameters of the problem itself and/or its solution. It is related to, but often distinguished from, probabilistic optimization methods such as chance-constrained optimization.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
Linear Programming Boosting (LPBoost) is a supervised classifier from the boosting family of classifiers. LPBoost maximizes a margin between training samples of different classes and hence also belongs to the class of margin-maximizing supervised classification algorithms. Consider a classification function
In mathematics — specifically, in stochastic analysis — the infinitesimal generator of a Feller process is a Fourier multiplier operator that encodes a great deal of information about the process.
In arithmetic, a complex-base system is a positional numeral system whose radix is an imaginary or complex number.
In probability theory and statistics, a stochastic order quantifies the concept of one random variable being "bigger" than another. These are usually partial orders, so that one random variable may be neither stochastically greater than, less than, nor equal to another random variable . Many different orders exist, which have different applications.
Financial models with long-tailed distributions and volatility clustering have been introduced to overcome problems with the realism of classical financial models. These classical models of financial time series typically assume homoskedasticity and normality cannot explain stylized phenomena such as skewness, heavy tails, and volatility clustering of the empirical asset returns in finance. In 1963, Benoit Mandelbrot first used the stable distribution to model the empirical distributions which have the skewness and heavy-tail property. Since -stable distributions have infinite -th moments for all , the tempered stable processes have been proposed for overcoming this limitation of the stable distribution.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product is a product distribution.
In financial mathematics and economics, a distortion risk measure is a type of risk measure which is related to the cumulative distribution function of the return of a financial portfolio.
Stochastic portfolio theory (SPT) is a mathematical theory for analyzing stock market structure and portfolio behavior introduced by E. Robert Fernholz in 2002. It is descriptive as opposed to normative, and is consistent with the observed behavior of actual markets. Normative assumptions, which serve as a basis for earlier theories like modern portfolio theory (MPT) and the capital asset pricing model (CAPM), are absent from SPT.
In quantum probability, the Belavkin equation, also known as Belavkin-Schrödinger equation, quantum filtering equation, stochastic master equation, is a quantum stochastic differential equation describing the dynamics of a quantum system undergoing observation in continuous time. It was derived and henceforth studied by Viacheslav Belavkin in 1988.
↑ Vickson, R.G. (1975). "Stochastic Dominance Tests for Decreasing Absolute Risk Aversion. I. Discrete Random Variables". Management Science. 21 (12): 1438–1446. doi:10.1287/mnsc.21.12.1438.
↑ Vickson, R.G. (1977). "Stochastic Dominance Tests for Decreasing Absolute Risk Aversion. II. General random Variables". Management Science. 23 (5): 478–489. doi:10.1287/mnsc.23.5.478.
↑ See, e.g. Post, Th.; Fang, Y.; Kopa, M. (2015). "Linear Tests for DARA Stochastic Dominance". Management Science. 61 (7): 1615–1629. doi:10.1287/mnsc.2014.1960.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.













![F
B
~
N
(
0
,
1
)
(
x
)
>=
F
A
~
N
(
0.75
,
1
)
(
x
)
[?]
x
{\displaystyle F_{B\sim N(0,1)}(x)\geq F_{A\sim N(0.75,1)}(x)\forall x}
[?]
B
(
b
l
a
c
k
)
<=
A
(
r
e
d
)
{\displaystyle \implies B(black)\leq A(red)} Normaldistdominance2.svg](http://upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Normaldistdominance2.svg/220px-Normaldistdominance2.svg.png)