Bayesian inference is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available. Fundamentally, Bayesian inference uses prior knowledge, in the form of a prior distribution in order to estimate posterior probabilities. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian updating is particularly important in the dynamic analysis of a sequence of data. Bayesian inference has found application in a wide range of activities, including science, engineering, philosophy, medicine, sport, and law. In the philosophy of decision theory, Bayesian inference is closely related to subjective probability, often called "Bayesian probability".
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). While it is one of several forms of causal notation, causal networks are special cases of Bayesian networks. Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
- With a shape parameter k and a scale parameter θ
- With a shape parameter and an inverse scale parameter , called a rate parameter.
In statistics, the Rao–Blackwell theorem, sometimes referred to as the Rao–Blackwell–Kolmogorov theorem, is a result that characterizes the transformation of an arbitrarily crude estimator into an estimator that is optimal by the mean-squared-error criterion or any of a variety of similar criteria.
In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X. Formally, it is the variance of the score, or the expected value of the observed information.
Bayesian experimental design provides a general probability-theoretical framework from which other theories on experimental design can be derived. It is based on Bayesian inference to interpret the observations/data acquired during the experiment. This allows accounting for both any prior knowledge on the parameters to be determined as well as uncertainties in observations.
The Kuramoto model, first proposed by Yoshiki Kuramoto, is a mathematical model used in describing synchronization. More specifically, it is a model for the behavior of a large set of coupled oscillators. Its formulation was motivated by the behavior of systems of chemical and biological oscillators, and it has found widespread applications in areas such as neuroscience and oscillating flame dynamics. Kuramoto was quite surprised when the behavior of some physical systems, namely coupled arrays of Josephson junctions, followed his model.
The nested sampling algorithm is a computational approach to the Bayesian statistics problems of comparing models and generating samples from posterior distributions. It was developed in 2004 by physicist John Skilling.
Approximate Bayesian computation (ABC) constitutes a class of computational methods rooted in Bayesian statistics that can be used to estimate the posterior distributions of model parameters.
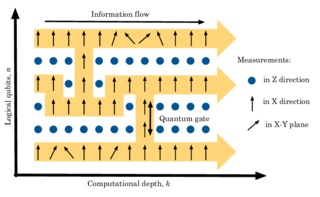
The one-way or measurement-based quantum computer (MBQC) is a method of quantum computing that first prepares an entangled resource state, usually a cluster state or graph state, then performs single qubit measurements on it. It is "one-way" because the resource state is destroyed by the measurements.
In statistics, identifiability is a property which a model must satisfy for precise inference to be possible. A model is identifiable if it is theoretically possible to learn the true values of this model's underlying parameters after obtaining an infinite number of observations from it. Mathematically, this is equivalent to saying that different values of the parameters must generate different probability distributions of the observable variables. Usually the model is identifiable only under certain technical restrictions, in which case the set of these requirements is called the identification conditions.
The kicked rotator, also spelled as kicked rotor, is a paradigmatic model for both Hamiltonian chaos and quantum chaos. It describes a free rotating stick in an inhomogeneous "gravitation like" field that is periodically switched on in short pulses. The model is described by the Hamiltonian

Exponential Random Graph Models (ERGMs) are a family of statistical models for analyzing data from social and other networks. Examples of networks examined using ERGM include knowledge networks, organizational networks, colleague networks, social media networks, networks of scientific development, and others.
Iterated filtering algorithms are a tool for maximum likelihood inference on partially observed dynamical systems. Stochastic perturbations to the unknown parameters are used to explore the parameter space. Applying sequential Monte Carlo to this extended model results in the selection of the parameter values that are more consistent with the data. Appropriately constructed procedures, iterating with successively diminished perturbations, converge to the maximum likelihood estimate. Iterated filtering methods have so far been used most extensively to study infectious disease transmission dynamics. Case studies include cholera, Ebola virus, influenza, malaria, HIV, pertussis, poliovirus and measles. Other areas which have been proposed to be suitable for these methods include ecological dynamics and finance.
Linear optical quantum computing or linear optics quantum computation (LOQC), also photonic quantum computing (PQC), is a paradigm of quantum computation, allowing (under certain conditions, described below) universal quantum computation. LOQC uses photons as information carriers, mainly uses linear optical elements, or optical instruments (including reciprocal mirrors and waveplates) to process quantum information, and uses photon detectors and quantum memories to detect and store quantum information.
In machine learning, the vanishing gradient problem is encountered when training recurrent neural networks with gradient-based learning methods and backpropagation. In such methods, during each iteration of training each of the neural networks weights receives an update proportional to the partial derivative of the error function with respect to the current weight. The problem is that as the sequence length increases, the gradient magnitude typically is expected to decrease, slowing the training process. In the worst case, this may completely stop the neural network from further training. As one example of the problem cause, traditional activation functions such as the hyperbolic tangent function have gradients in the range [-1,1], and backpropagation computes gradients by the chain rule. This has the effect of multiplying n of these small numbers to compute gradients of the early layers in an n-layer network, meaning that the gradient decreases exponentially with n while the early layers train very slowly.
The quantum Fisher information is a central quantity in quantum metrology and is the quantum analogue of the classical Fisher information. The quantum Fisher information of a state with respect to the observable is defined as
An energy-based model (EBM) (Canonical Ensemble Learning(CEL) or Learning via Canonical Ensemble (LCE)) is an application of canonical ensemble formulation of statistical physics for learning from data problems. Approach prominently appears in generative models.
Quantum artificial life is the application of quantum algorithms with the ability to simulate biological behavior. Quantum computers offer many potential improvements to processes performed on classical computers including machine learning and artificial intelligence. Artificial intelligence applications are often inspired by the idea of mimicking human brains; closely related biomimicry. This has been implemented to a certain extent on classical computers, but quantum computers offer many advantages in the simulation of artificial life. Artificial life and artificial intelligence are extremely similar with a minor differences; the goal of studying artificial life is to understand living beings better, while the goal of artificial intelligence is to create intelligent beings.
In quantum computing, the variational quantum eigensolver (VQE) is a quantum algorithm for quantum chemistry, quantum simulations and optimization problems. It is a hybrid algorithm that uses both classical computers and quantum computers to find the ground state of a given physical system. Given a guess or ansatz, the quantum processor calculates the expectation value of the system with respect to an observable, often the Hamiltonian, and a classical optimizer is used to improve the guess. The algorithm is based on the variational method of quantum mechanics.









