Transcriptional gene modulation
An approach to therapeutic modulation utilizes agents that modulate endogenous transcription by specifically targeting those genes at the gDNA level. The advantage to this approach over modulation at the mRNA or protein level is that every cell contains only a single gDNA copy. Thus the target copy number is significantly lower allowing the drugs to theoretically be administered at much lower doses.[ citation needed ]
This approach also offers several advantages over traditional gene therapy. Directly targeting endogenous transcription should yield correct relative expression of splice variants. In contrast, traditional gene therapy typically introduces a gene which can express only one transcript, rather than a set of stoichiometrically-expressed spliced transcript variants. Additionally, virally-introduced genes can be targeted for gene silencing by methylation which can counteract the effect of traditional gene therapy. [1] This is not anticipated to be a problem for transcriptional modulation as it acts on endogenous DNA.
There are three major categories of agents that act as transcriptional gene modulators: triplex-forming oligonucleotides (TFOs), synthetic polyamides (SPAs), and DNA binding proteins. [2]
Triplex-forming oligonucleotides
What are they
Triplex-forming oligonucleotides (TFO) are one potential method to achieve therapeutic gene modulation. TFOs are approximately 10-40 base pairs long and can bind in the major groove in duplex DNA which creates a third strand or a triple helix. [2] [3] The binding occurs at polypurine or polypyrimidine regions via Hoogsteen hydrogen bonds to the purine (A / G) bases on the double stranded DNA that is already in the form of the Watson-Crick helix. [4]
How they work
TFOs can be either polypurine or polypyrimidine molecules and bind to one of the two strands in the double helix in either parallel or antiparallel orientation to target polypurine or polypyrimidine regions. Since the DNA-recognition codes are different for the parallel and the anti-parallel fashion of TFO binding, TFOs composed of pyrimidines (C / T) bind to the purine-rich strand of the target double helix via Hoogsteen hydrogen bonds in a parallel fashion. [3] TFOs composed of purines (A / G), or mixed purine and pyrimidine bind to the same purine-rich strand via reverse Hoogsteen bonds in an anti-parallel fashion. TFO's can recognize purine-rich target strands for duplex DNA. [2]

Complications and limitations
In order for TFO motifs to bind in a parallel fashion and create hydrogen bonds, the nitrogen atom at position 3 on the cytosine residue needs to be protonated, but at physiological pH levels it is not, which could prevent parallel binding. [2]
Another limitation is that TFOs can only bind to purine-rich target strands and this would limit the choice of endogenous gene target sites to polypurine-polypyrimidine stretches in duplex DNA. If a method to also allow TFOs to bind to pyrimidine bases was generated, this would enable TFOs to target any part of the genome. Also the human genome is rich in polypurine and polypyrimidine sequences which could affect the specificity of TFO to bind to a target DNA region. An approach to overcome this limitation is to develop TFOs with modified nucleotides that act as locked nucleic acids to increase the affinity of the TFO for specific target sequences. [5]
Other limitations include concerns regarding binding affinity and specificity, in vivo stability, and uptake into cells. Researchers are attempting to overcome these limitations by improving TFO characteristics through chemical modifications, such as modifying the TFO backbone to reduce electrostatic repulsions between the TFO and the DNA duplex. Also due to their high molecular weight, uptake into cells is limited and some strategies to overcome this include DNA condensing agents, coupling of the TFO to hydrophobic residues like cholesterol, or cell permeabilization agents. [2]
What can they do
Scientists are still refining the technology to turn TFOs into a therapeutic product and much of this revolves around their potential applications in antigene therapy. In particular they have been used as inducers of site-specific mutations, reagents that selectively and specifically cleave target DNA, and as modulators of gene expression. [6] One such gene sequence modification method is through the targeting DNA with TFOs to active a target gene. If a target sequence is located between two inactive copies of a gene, DNA ligands, such as TFOs, can bind to the target site and would be recognized as DNA lesions. To fix these lesions, DNA repair complexes are assembled on the targeted sequence, the DNA is repaired. Damage of the intramolecular recombination substrate can then be repaired and detected if resection goes far enough to produce compatible ends on both sides of the cleavage site and then 3' overhangs are ligated leading to the formation of a single active copy of the gene and the loss of all the sequences between the two copies of the gene. [4]
In model systems TFOs can inhibit gene expression at the DNA level as well as induce targeted mutagenesis in the model. [6] TFO-induced inhibition of transcription elongation on endogenous targets have been tested on cell cultures with success. [7] However, despite much in vitro success, there has been limited achievement in cellular applications potentially due to target accessibility.
TFOs have the potential to silence silence gene by targeting transcription initiation or elongation, arresting at the triplex binding sites, or introducing permanent changes in a target sequence via stimulating a cell's inherent repair pathways. These applications can be relevant in creating cancer therapies that inhibit gene expression at the DNA level. Since aberrant gene expression is a hallmark of cancer, modulating these endogenous genes' expression levels could potentially act as a therapy for multiple cancer types.
Synthetic polyamides
Synthetic polyamides are a set of small molecules that form specific hydrogen bonds to the minor groove of DNA. They can exert an effect either directly, by binding a regulatory region or transcribed region of a gene to modify transcription, or indirectly, by designed conjugation with another agent that makes alterations around the DNA target site.

Structure
Specific bases in the minor groove of DNA can be recognized and bound by small synthetic polyamides (SPAs). DNA-binding SPAs have been engineered to contain three polyamide amino acid components: hydroxypyrrole (Hp), imidazole (Im), and pyrrole (Py). [10] Chains of these amino acids loop back on themselves in a hairpin structure. The amino acids on either side of the hairpin form a pair which can specifically recognize both sides of a Watson-Crick base pair. This occurs through hydrogen bonding within the minor groove of DNA. The amide pairs Py/Im, Py/Hp, Hp/Py, and Im/Py recognize the Watson-Crick base pairs C-G, A-T, T-A, and G-C, respectively (Table 1). See figure for a graphical representation of 5'-GTAC-3' recognition by a SPA. SPAs have low toxicity, but have not yet been used in human gene modulation.
| Amide Pair | Nucleotide Pair |
|---|---|
| Py/Im | C-G |
| Py/Hp | A-T |
| Hp/Py | T-A |
| Im/Py | G-C |
Limitations and workarounds
The major structural drawback to unmodified SPAs as gene modulators is that their recognition sequence cannot be extended beyond 5 Watson-Crick base pairings. The natural curvature of the DNA minor groove is too tight a turn for the hairpin structure to match. There are several groups with proposed workarounds to this problem. [8] [11] [12] [13] [14] SPAs can be made to better follow the curvature of the minor groove by inserting beta-alanine which relaxes the structure. [10] Another approach to extending the recognition length is to use several short hairpins in succession. [15] [16] This approach has increased the recognition length to up to eleven Watson-Crick base pairs.


Direct modulation
SPAs may inhibit transcription through binding within a transcribed region of a target gene. This inhibition occurs through blocking of elongation by an RNA polymerase.
SPAs may also modulate transcription by targeting a transcription regulator binding site. If the regulator is an activator of transcription, this will decrease transcriptional levels. As an example, SPA targeting to the binding site for the activating transcription factor TFIIIA has been demonstrated to inhibit transcription of the downstream 5S RNA. [17] In contrast, if the regulator is a repressor, this will increase transcriptional levels. As an example, SPA targeting to the host factor LSF, which represses expression of the human immunodeficiency virus (HIV) type 1 long terminal repeat (LTR), blocks binding of LSF and consequently de-represses expression of LTR [18] .

Conjugate modulation
SPAs have not been shown to directly modify DNA or have activity other than direct blocking of other factors or processes. However, modifying agents can be bound to the tail ends of the hairpin structure. The specific binding of the SPA to DNA allows for site-specific targeting of the conjugated modifying agent.
SPAs have been paired with the DNA-alkylating moieties cyclopropylpyrroloindole [19] and chlorambucil [20] that were able to damage and crosslink SV40 DNA. This effect inhibited cell cycling and growth. Chlorambucil, a chemotherapeutic agent, was more effective when conjugated to an SPA than without.
In 2012, SPAs were conjugated to SAHA, a potent histone deacetylase (HDAC) inhibitor. [21] SPAs with conjugated SAHA were targeted to Oct-3/4 and Nanog which induced epigenetic remodeling and consequently increased expression of multiple pluripotency related genes in mouse embryonic fibroblasts.
Designer zinc-finger proteins
What they are/structure
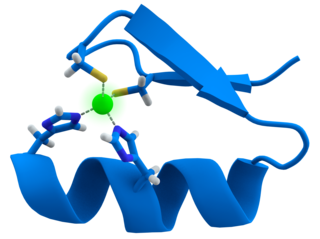
Designer zinc-finger proteins are engineered proteins used to target specific areas of DNA. These proteins capitalize on the DNA-binding capacity of natural zinc-finger domains to modulate specific target areas of the genome. [22] In both designer and natural zinc-finger motifs, the protein consists of two β-sheets and one α-helix. Two histidine residues on the α-helix and two cysteine residues on the β-sheets are bonded to a zinc atom, which serves to stabilize the protein domain as a whole. This stabilization particularly benefits the α-helix in its function as the DNA-recognition and -binding domain. Transcription factor TFIIIA is an example of a naturally-occurring protein with zinc-finger motifs. [23]

How they work
Zinc-finger motifs bind into the major groove of helical DNA, [23] where the amino acid residue sequence on the α-helix gives the motif its target sequence specificity. The domain binds to a seven-nucleotide sequence of DNA (positions 1 through 6 on the primary strand of DNA, plus positions 0 and 3 on the complementary strand), thereby ensuring that the protein motif is highly selective of its target. [22] In engineering a designer zinc-finger protein, researchers can utilize techniques such as site-directed mutagenesis followed by randomized trials for binding capacity, [22] [24] or the in vitro recombination of motifs with known target specificity to produce a library of sequence-specific final proteins. [25]


Effects and impacts on gene modulation
Designer zinc-finger proteins can modulate genome expression in a number of ways. Ultimately, two factors are primarily responsible for the result on expression: whether the targeted sequence is a regulatory region or a coding region of DNA, and whether and what types of effector domains are bound to the zinc-finger domain. If the target sequence for an engineered designer protein is a regulatory domain - e.g., a promoter or a repressor of replication - the binding site for naturally-occurring transcription factors will be obscured, leading to a corresponding decrease or increase, respectively, in transcription for the associated gene. [26] Similarly, if the target sequence is an exon, the designer zinc-finger will obscure the sequence from RNA polymerase transcription complexes, resulting in a truncated or otherwise nonfunctional gene product. [22]
Effector domains bound to the zinc-finger can also have comparable effects. It is the function of these effector domains which are arguably the most important with respect to the use of designer zinc-finger proteins for therapeutic gene modulation. If a methylase domain is bound to the designer zinc-finger protein, when the zinc-finger protein binds to the target DNA sequence an increase in methylation state of DNA in that region will subsequently result. Transcription rates of genes so-affected will be reduced. [27] Many of the effector domains function to modulate either the DNA directly - e.g. via methylation, cleaving, [28] or recombination of the target DNA sequence [29] - or by modulating its transcription rate - e.g. inhibiting transcription via repressor domains that block transcriptional machinery, [30] promoting transcription with activation domains that recruit transcriptional machinery to the site, [31] or histone- or other epigenetic-modification domains that affect chromatin state and the ability of transcriptional machinery to access the affected genes. [32] Epigenetic modification is a major theme in determining varying expression levels for genes, as explained by the idea that how tightly-wound the DNA strand is - from histones at the local level up to chromatin at the chromosomal level - can influence the accessibility of sequences of DNA to transcription machinery, thereby influencing the rate at which it can be transcribed. [23] If, instead of impacting the DNA strand directly, as described above, a designer zinc-finger protein instead affects epigenetic modification state for a target DNA region, modulation of gene expression could similarly be accomplished.
In the first case to successfully demonstrate the use of designer zinc-finger proteins to modulate gene expression in vivo, Choo et al. [26] designed a protein consisting of three zinc-finger domains that targeted a specific sequence on a BCR-ABL fusion oncogene. This specific oncogene is implicated in acute lymphoblastic leukemia. The oncogene typically enables leukemia cells to proliferate in the absence of specific growth factors, a hallmark of cancer. By including a nuclear localization signal with the tri-domain zinc-finger protein in order to facilitate binding of the protein to genomic DNA in the nucleus, Choo et al. were able to demonstrate that their engineered protein could block transcription of the oncogene in vivo. Leukemia cells became dependent on regular growth factors, bringing the cell cycle back under the control of normal regulation. [26]