The Phoenician alphabet is a consonantal alphabet used across the Mediterranean civilization of Phoenicia for most of the 1st millennium BCE. It was one of the first alphabets, and attested in Canaanite and Aramaic inscriptions found across the Mediterranean region. In the history of writing systems, the Phoenician script also marked the first to have a fixed writing direction—while previous systems were multi-directional, Phoenician was written horizontally, from right to left. It developed directly from the Proto-Sinaitic script used during the Late Bronze Age, which was derived in turn from Egyptian hieroglyphs.
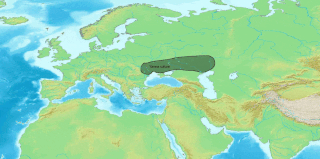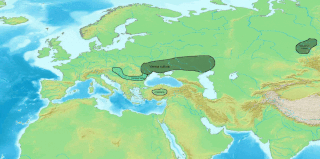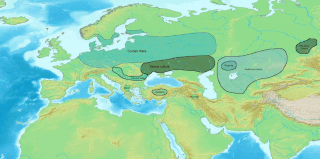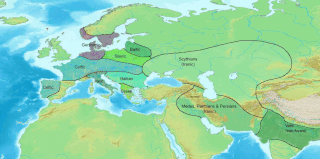
The Anatolian languages are an extinct branch of Indo-European languages that were spoken in Anatolia, part of present-day Turkey. The best known Anatolian language is Hittite, which is considered the earliest-attested Indo-European language.

The Lycian language was the language of the ancient Lycians who occupied the Anatolian region known during the Iron Age as Lycia. Most texts date back to the fifth and fourth century BC. Two languages are known as Lycian: regular Lycian or Lycian A, and Lycian B or Milyan. Lycian became extinct around the beginning of the first century BC, replaced by the Ancient Greek language during the Hellenization of Anatolia. Lycian had its own alphabet, which was closely related to the Greek alphabet but included at least one character borrowed from Carian as well as characters proper to the language. The words were often separated by two points.

Luwian, sometimes known as Luvian or Luish, is an ancient language, or group of languages, within the Anatolian branch of the Indo-European language family. The ethnonym Luwian comes from Luwiya – the name of the region in which the Luwians lived. Luwiya is attested, for example, in the Hittite laws.

Bedřich Hrozný, also known as Friedrich Hrozny, was a Czech orientalist and linguist. He contributed to the decipherment of the ancient Hittite language, identified it as an Indo-European language, and laid the groundwork for the development of Hittitology.

Cuneiform is a logo-syllabic writing system that was used to write several languages of the Ancient Near East. The script was in active use from the early Bronze Age until the beginning of the Common Era. Cuneiform scripts are marked by and named for the characteristic wedge-shaped impressions which form their signs. Cuneiform is the earliest known writing system and was originally developed to write the Sumerian language of southern Mesopotamia.

Hittite, also known as Nesite, is an extinct Indo-European language that was spoken by the Hittites, a people of Bronze Age Anatolia who created an empire centred on Hattusa, as well as parts of the northern Levant and Upper Mesopotamia. The language, now long extinct, is attested in cuneiform, in records dating from the 17th to the 13th centuries BC, with isolated Hittite loanwords and numerous personal names appearing in an Old Assyrian context from as early as the 20th century BC, making it the earliest attested use of the Indo-European languages.
Old Persian is one of two directly attested Old Iranian languages and is the ancestor of Middle Persian. Like other Old Iranian languages, it was known to its native speakers as ariya (Iranian). Old Persian is close to both Avestan and the language of the Rig Veda, the oldest form of the Sanskrit language. All three languages are highly inflected.

Hattusa, also Hattuşa, Ḫattuša, Hattusas, or Hattusha, was the capital of the Hittite Empire in the late Bronze Age during two distinct periods. Its ruins lie near modern Boğazkale, Turkey, within the great loop of the Kızılırmak River.

Assyriology, also known as Cuneiform studies or Ancient Near East studies, is the archaeological, anthropological, historical, and linguistic study of the cultures that used cuneiform writing. The field covers Pre Dynastic Mesopotamia, Sumer, the early Sumero-Akkadian city-states, the Akkadian Empire, Ebla, the Akkadian and Imperial Aramaic speaking states of Assyria, Babylonia and the Sealand Dynasty, the migrant foreign dynasties of southern Mesopotamia, including the Gutians, Amorites, Kassites, Arameans, Suteans and Chaldeans. Assyriology can be included to cover Neolithic pre-Dynastic cultures dating to as far back as 8000 BC, to the Islamic Conquest of the 7th century AD, so the topic is significantly wider than that implied by the root "Assyria".

Palmyrene Aramaic was a primarily Western Aramaic dialect, exhibiting Eastern Aramaic grammatical features and hence often regarded as a dialect continuum between the Eastern and Western Aramaic branches. It was primarily documented in Palmyra itself, but also found in the western parts of the Roman Empire, extending as far as Britannia. Dated inscriptions range from 44 BCE to 274 CE, with over 4,000 known inscriptions, mostly comprising honorific, dedicatory, and funerary texts. The dialect still retains echoes of earlier Imperial Aramaic. The lexicon bears influences from both Koine Greek and, to some extent, Arabic.

Tyana, earlier known as Tuwana during the Iron Age, and Tūwanuwa during the Bronze Age, was an ancient city in the Anatolian region of Cappadocia, in modern Kemerhisar, Niğde Province, Central Anatolia, Turkey.
The history of the alphabet goes back to the consonantal writing system used to write Semitic languages in the Levant during the 2nd millennium BCE. Nearly all alphabetic scripts used throughout the world today ultimately go back to this Semitic script. Its first origins can be traced back to a Proto-Sinaitic script developed in Ancient Egypt to represent the language of Semitic-speaking workers and slaves in Egypt. Unskilled in the complex hieroglyphic system used to write the Egyptian language, which required a large number of pictograms, they selected a small number of those commonly seen in their surroundings to describe the sounds, as opposed to the semantic values, of their own Canaanite language. This script was partly influenced by the older Egyptian hieratic, a cursive script related to Egyptian hieroglyphs. The Semitic alphabet became the ancestor of multiple writing systems across the Middle East, Europe, northern Africa, and Pakistan, mainly through Ancient South Arabian, Phoenician and the closely related Paleo-Hebrew alphabet, and later Aramaic and the Nabatean—derived from the Aramaic alphabet and developed into the Arabic alphabet—five closely related members of the Semitic family of scripts that were in use during the early first millennium BCE.

Anatolian hieroglyphs are an indigenous logographic script native to central Anatolia, consisting of some 500 signs. They were once commonly known as Hittite hieroglyphs, but the language they encode proved to be Luwian, not Hittite, and the term Luwian hieroglyphs is used in English publications. They are typologically similar to Egyptian hieroglyphs, but do not derive graphically from that script, and they are not known to have played the sacred role of hieroglyphs in Egypt. There is no demonstrable connection to Hittite cuneiform.

Old Persian cuneiform is a semi-alphabetic cuneiform script that was the primary script for Old Persian. Texts written in this cuneiform have been found in Iran, Armenia, Romania (Gherla), Turkey, and along the Suez Canal. They were mostly inscriptions from the time period of Darius I, such as the DNa inscription, as well as his son, Xerxes I. Later kings down to Artaxerxes III used more recent forms of the language classified as "pre-Middle Persian".

In epigraphy, a multilingual inscription is an inscription that includes the same text in two or more languages. A bilingual is an inscription that includes the same text in two languages. Multilingual inscriptions are important for the decipherment of ancient writing systems, and for the study of ancient languages with small or repetitive corpora.
Cybistra or Kybistra, earlier known as Ḫubišna, was a town of ancient Cappadocia or Cilicia.
The Open Richly Annotated Cuneiform Corpus, or Oracc, is an ongoing project designed to make the corpus of cuneiform compositions from the ancient Near East available online and accessible to users. The project, created by Steve Tinney of the University of Pennsylvania, incorporates a number of sub-projects, including online publications of lemmatized texts in different genres, as well as extensive annotations and other tools for studying and learning about the ancient Near East. The sub-projects are directed by individual scholars specializing in the relevant topic. The overall project is led by a steering committee of Tinney, Eleanor Robson of Cambridge University, and Niek Veldhuis of the University of California, Berkeley.

The Canaanite and Aramaic inscriptions, also known as Northwest Semitic inscriptions, are the primary extra-Biblical source for understanding of the society and history of the ancient Phoenicians, Hebrews and Arameans. Semitic inscriptions may occur on stone slabs, pottery ostraca, ornaments, and range from simple names to full texts. The older inscriptions form a Canaanite–Aramaic dialect continuum, exemplified by writings which scholars have struggled to fit into either category, such as the Stele of Zakkur and the Deir Alla Inscription.

Kubaba was a goddess of uncertain origin worshiped in ancient Syria. Despite the similarity of her name to these of legendary queen Kubaba of Kish and Phrygian Cybele, she is considered a distinct figure from them both. Her character is poorly known. Multiple local traditions associating her with other deities existed, and they cannot necessarily be harmonized with each other. She is first documented in texts from Kanesh and Alalakh, though her main cult center was Carchemish. She was among the deities worshiped in northern Syria who were incorporated into Hurrian religion, and in Hurrian context she occurs in some of the Ugaritic texts. She was also incorporated into Hittite religion through Hurrian intermediaties. In the first millennium BCE she was worshiped by Luwians, Arameans and Lydians, and references to her can be found in a number of Greek texts.
